Textured Neural Avatars 论文方法简述
论文链接:Textured Neural Avatar
CMU Panotic dataset链接:CMU Panoptic Dataset
完成的工作:video to video translation,从输入的有限角度图片合成任意viewpoint的、与输入不同pose的image sequence,即video
问题:
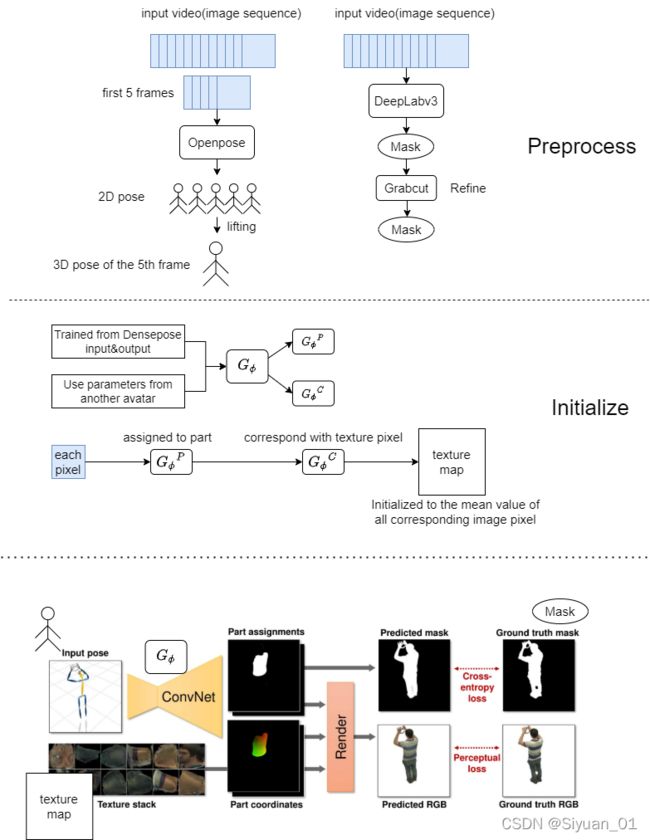
1、如何获得input pose?
CMU Panoptic数据集自带骨骼点数据。对于其他的数据集,先对单目RGB视频的前五帧应用Openpose得到五个2D pose,再lift得到第五帧时的3D pose
2、如何获得ground-truth foreground mask(计算mask的loss时要用)?
用DeepLabv3+生成,用GrabCut来refine
Methods
1、Input and Output
输入:image  (视频中的一帧),以及对应image 的map stack
(视频中的一帧),以及对应image 的map stack 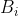 ,包括了image 中pose的信息。中的每个map
,包括了image 中pose的信息。中的每个map ![]() 包含第
包含第 块“火柴人”的骨头在相机平面上的投影(也就是说,被第块骨头覆盖的pixel在
块“火柴人”的骨头在相机平面上的投影(也就是说,被第块骨头覆盖的pixel在![]() 中对应的值非零,其余pixel在
中对应的值非零,其余pixel在![]() 中对应的值为零)。每块骨头覆盖的区域(segment)是由关节点确定的,关节点有横纵坐标和深度坐标,而segment内的普通点没有深度坐标,因此对每个segment里的普通点的深度坐标进行线性插值,并据此确定
中对应的值为零)。每块骨头覆盖的区域(segment)是由关节点确定的,关节点有横纵坐标和深度坐标,而segment内的普通点没有深度坐标,因此对每个segment里的普通点的深度坐标进行线性插值,并据此确定![]() 中对应的值
中对应的值
输出:一个RGB image(three-channel stack)![]() 和一个mask(single-channel stack)
和一个mask(single-channel stack)
2、Baseline
Image-to-image translation network,使用 fully-convolutional architecture直接将映射到![]() 和。此文具体选用了一个video-to-video的变体来作为baseline
和。此文具体选用了一个video-to-video的变体来作为baseline
3、Textured Neural Avatar
上述baseline的系统强烈依赖于全卷积结构,而几乎没有使用任何domain-specific的知识。此文对纹理(texture)进行显式建模(怎么显式建模?),从而保证身体各个部分在不同姿势下纹理的一致性。
此文的方法参考了DensePose,将body分成 =24个部分,每个body part都有一个2D参数。此外,每个body part都有一个texture map
=24个部分,每个body part都有一个2D参数。此外,每个body part都有一个texture map ![]() (实际上就是UV贴图),其大小是预先设置的,此文中为256
(实际上就是UV贴图),其大小是预先设置的,此文中为256 256。参数
256。参数 表示第个body part。Input image中的每一个pixel都被assign到24个body part中的一个或者background里,结果用
表示第个body part。Input image中的每一个pixel都被assign到24个body part中的一个或者background里,结果用 (stack of body assignment stack)表示。同时得到每个pixel在body part内部的坐标,结果用
(stack of body assignment stack)表示。同时得到每个pixel在body part内部的坐标,结果用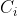 (stack of body part coordinate)表示。DensePose使用image来估计assignment和coordinate,而本文仅使用了
(stack of body part coordinate)表示。DensePose使用image来估计assignment和coordinate,而本文仅使用了
由n+1个map组成,map内元素非负。![]() 表示image中的一点
表示image中的一点 ![]() 属于第
属于第  个body part或background的概率(
个body part或background的概率(![]() 为background),且有
为background),且有 ![]()
![]() 由2个map组成,map内元素为0~
由2个map组成,map内元素为0~![]() 之间的实数。
之间的实数。![]() 为texture map
为texture map ![]() 的尺寸,此处
的尺寸,此处![]() =256。
=256。![]() 和
和 ![]() 表示 image中的一点
表示 image中的一点![]() 在第 个body part中的坐标
在第 个body part中的坐标
系统输出image![]() 可以用texture element加权表示:
可以用texture element加权表示:
其中 函数是sampling function,其输出就是
函数是sampling function,其输出就是![]() (当然,最终的输出结果需要多次回馈、迭代)。在
(当然,最终的输出结果需要多次回馈、迭代)。在 与
与 非整数处,采用双线性插值
非整数处,采用双线性插值
此文通过训练得到跟据预测和![]() 的网络
的网络![]() 以及网络参数
以及网络参数 ,
,![]() 有两个分支:
有两个分支:![]() 和
和![]() 。为了训练参数,要计算loss并回馈到
。为了训练参数,要计算loss并回馈到![]() 和
和![]() ,使得每一次迭代不仅更新网络参数,也更新纹理。
,使得每一次迭代不仅更新网络参数,也更新纹理。

对mask的训练也要计算与ground-truth mask之间的loss,回馈迭代
4、Textured Neural Avatar的初始化
此文表示网络模型初始化参数对于3D重建的成功非常重要。初始化![]() 有两种方式:
有两种方式:
1、先把input放到DensePose里跑一边得到output,然后训练一个translation network ![]() between input and DensePose output作为初始
between input and DensePose output作为初始
2、Transfer learning,由于不同人体之间有差异但差异不大,可以使用别的data训练出来的![]() 作为初始
作为初始
接着对![]() 进行初始化。对于input image中每个pixel,根据
进行初始化。对于input image中每个pixel,根据![]() 得到其body part assignment,根据
得到其body part assignment,根据![]() 得到其对应的texture pixel(不是一一映射)。每个texture pixel的值(RGB)被初始化为映射到它的image pixel的均值,没有被image pixel映射到的texture pixel初始化为黑色。
得到其对应的texture pixel(不是一一映射)。每个texture pixel的值(RGB)被初始化为映射到它的image pixel的均值,没有被image pixel映射到的texture pixel初始化为黑色。
画了张图完整表示这套系统的工作流程: