图神经网络(11)— 在知识图谱上推理
目录
预测单跳查询(one-hop queries)
预测路径查询(path queries)
Traversing Knowledge Graphs in Vector Space(以TransE为例)
预测(多路)结合查询(conjunctive queries)
Query2box**
思路:
算法概括:
box表示:
投影运算:
intersection 操作:
实体到box的距离:
AND-OR QUERY( 拓展union操作)
如何训练 Query2box
如何产生训练样本
摘要:如何在知识图谱上进行推理,主要介绍Traversing Knowledge Graphs in Vector Space(以TransE为例)和 Query2box* 两个算法。
这篇文章,主要是讨论在不完整的知识图谱上推理,回答(预测)多跳的查询问题。
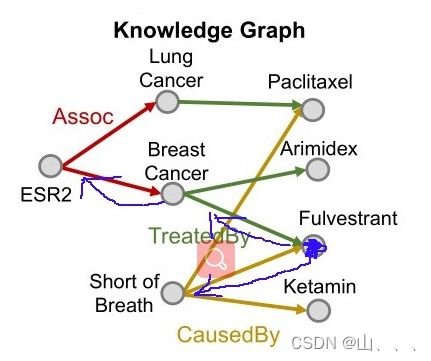
之后举的例子,都是以这个知识图为例子!
这个知识图谱有个特点:一种节点对应一种指向自己连边(interact不一样)
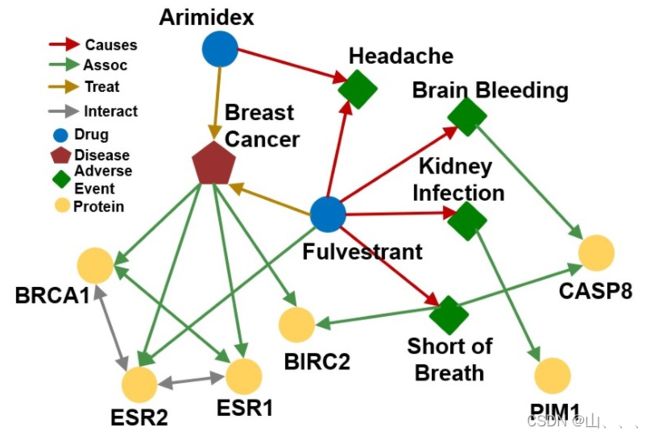
在知识图谱中的预测序列任务可以分为三种,单跳查询——从一个起始节点(实体)通过长度为1的边(关系)查询其他节点(实体);路径查询——从一个起始节点(实体)通过长度为n的边查询其他节点(实体);联合查询——从多个起始节点(实体)通过长度为n1,n2...的边查询共有的其他节点(实体)。下面是具体的示例:

预测单跳查询(one-hop queries)
单跳查询——从一个起始节点(实体)通过长度为1的边(关系)查询其他节点(实体)
这个问题很好解决,要回答单跳查询其实就等价于预测这两个节点之间是否有边连接。
预测路径查询(path queries)
路径查询——从一个起始节点(实体)通过长度为n的边(关系)查询其他节点(实体)
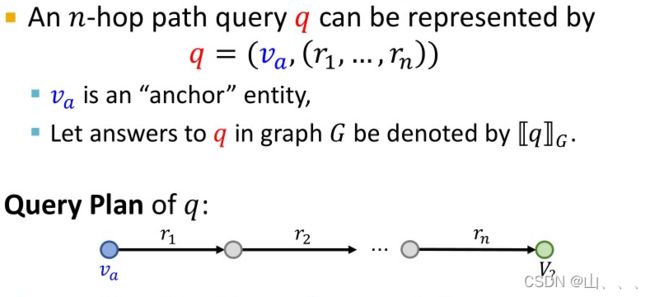
问题是,给我们一个知识图,怎么能找到最后的目标节点(实体)呢?
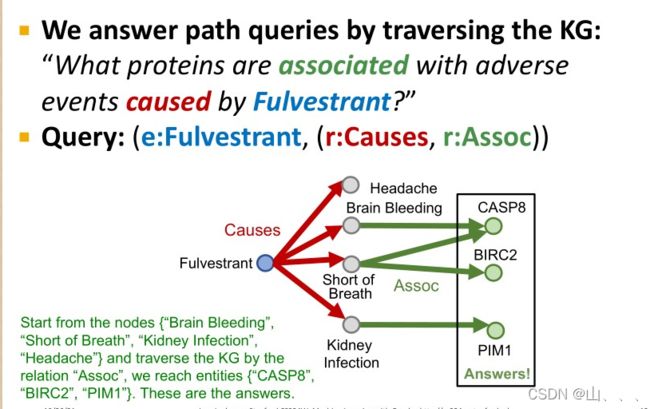
其实也很简单,就是从初始节点,按照关系r向前走就行!
但是,很不幸的是,知识图谱是不完整的,其中会缺少很多边。那么就会因此缺少很多应该得到的结果!
我们也不可能先把知识图谱补充完整(太难了),再去推理结果。
因此我们需要一种在不完整的知识图谱上推理多跳结果的方法!
思路:把序列映射成向量,结果节点也映射成向量;序列embedding与之相对应的结果节点embedding应该接近。
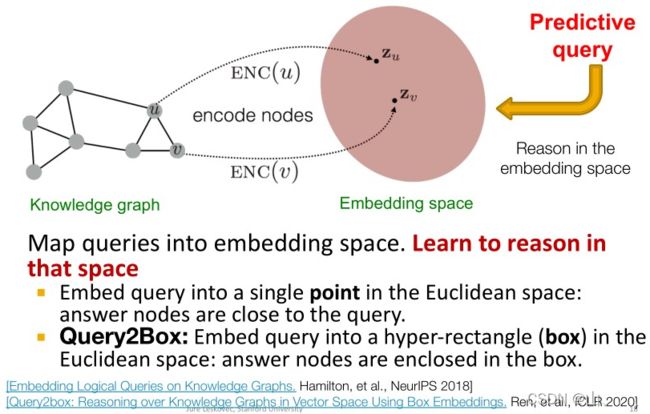
Traversing Knowledge Graphs in Vector Space(以TransE为例)
其实就是利用TransE算出来各个实体(节点)和关系(边)的嵌入;那么序列的嵌入就等于起始节点嵌入加上多个边嵌入。

例子: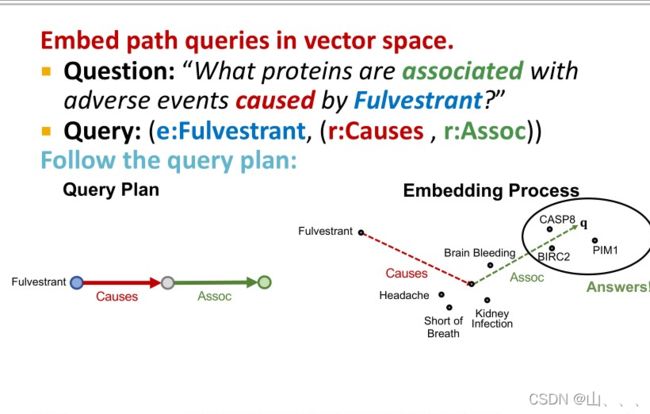
TransE可以很轻易的处理多个关系结合(直接相加),所以可以处理多跳推理;但是对于TransR/DistMult/ComplEx 来说,不能处理多个关系的结合,所以不能处理多跳推理。
预测(多路)结合查询(conjunctive queries)
多路结合查询只需要从多个节点开始,根据相应的关系向前推理,最后取交集。
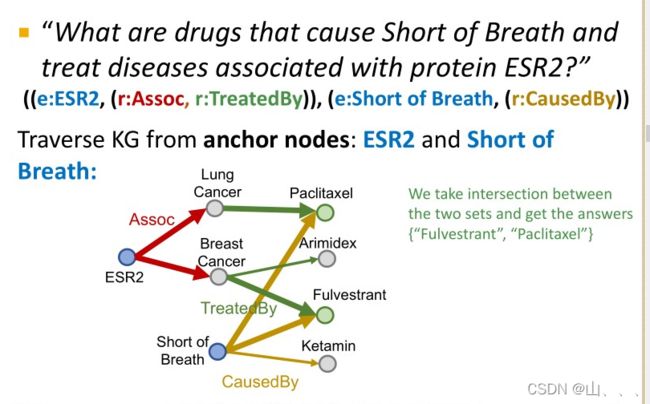
如果知识图谱是完整的话,就可以非常简单的得到结果,但是同样由于知识图谱不全,会漏掉结果。所以我们需要一个在不完整的知识图谱上预测的算法!
Query2box**
更多细节可以看这篇论文,下载地址Query2box Reasoning over Knowledge Graphs in Vector Space Using Box Embeddings
思路:
Query2box把序列映射成boxes。而上面提到的拓展的transE算法,它是把序列映射成点(向量形式)
算法概括:
在Query2box算法中,每一个box,它由中心点和偏移项表示,实体(节点)被看作是没有容积的box,关系(边)被看作是一种投影运算—— 一个box通过关系的投影可以得到一个新的box。此外,还定义intersection操作。
以下面这个conjunctive queries 为例:

我们可以把它简化成下面的形式: (intersection 表示交集)
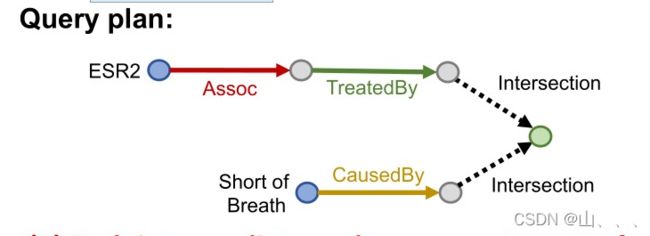
上图中每一个节点,他表示的不仅仅是一个实体(节点),他表示的是一个集合,表示的是一个范围。而在Query2box算法中,上图中每个节点都由一个boxs表示。
box表示:
每一个box,由中心点和偏移项表示,实体(节点)被看作是没有容积的box
下图是 由Fulvestrant造成的症状,我们用一个box表示。

投影运算:
关系(边)被看作是一种投影运算—— 一个box通过关系的投影可以得到一个新的box
那么由知识图谱得到的表示方式,就可以化为在向量空间的表示: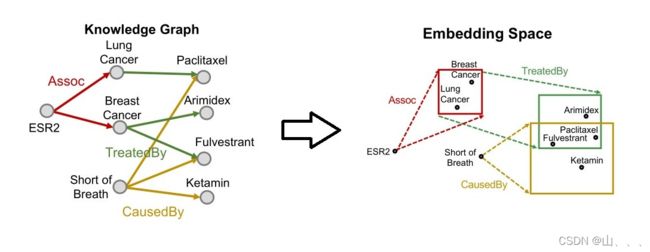
intersection 操作:
intersection操作,是获得多个box共有区域。这个共有区域要尽可能的小(offset小),并且交集box的中心要在一个“合理”的位置。
交集box中心:
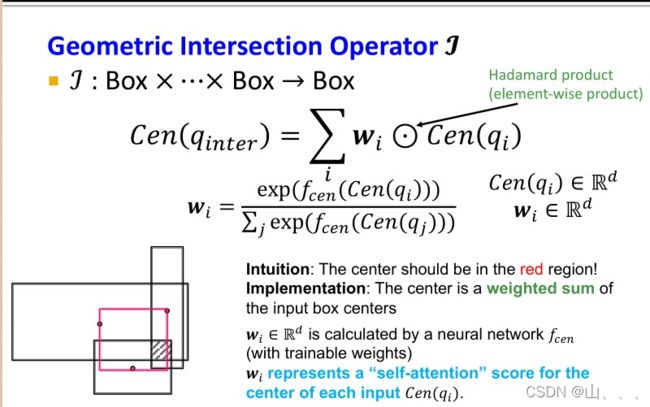
交集box偏移项:

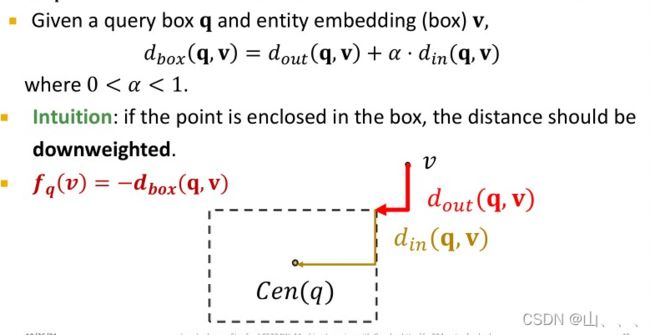
实体到box的距离:
包括两个距离,实体到box边缘的距离和顶点到中心的距离。训练模型的时候,就是要使得模型得到的box到结果节点的距离最小。
AND-OR QUERY( 拓展union操作)
在知识图谱上的推理,除了求交集外,也有求并集的时候。例如说,What drug can treat breast cancer or lung cancer? 它用的or就对应着并集,而上面提到的交集一般对应着and。有Conjunctive 和disjunction的queries,被称作为Existential Positive First-order (EPFO) queries,也成为AND-OR QUERY。
问题:值得注意的是,在box的表示形式下,使用union操作的话,那么我们的嵌入空间维度会很大,节点越多维度越大。而在知识图谱中,节点非常多。
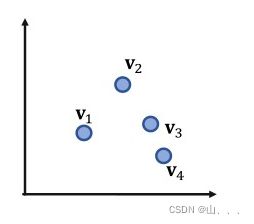
例如,在二维空间,是无法使用union,得到下图中仅包含v2和v4的box。在三维空间,便可以得到这四个节点任意两个节点的union box。
解决方法:把union操作放到最后一步——也就是把AND-OR 查询 转换成 DNF形式。

对于AND-OR queries,实体(节点)到box的距离就变成:实体(节点)到其中任意一个子box的最小距离。

实体到box的距离很近,就表示这个实体(节点)是box所表示的queries的答案。对于实行union操作的子box,实体(节点)接近任意一个子box的都是答案。
处理流程:

如何训练 Query2box

如何产生训练样本
首先定义一些模板:

然后根据模板实例化得到query:
1. 首先实例化answer节点:在KG上随机采样一个节点作为answer节点。
2.根据模板,由answer节点反着向前推理得到anchor节点。
3.由anchor节点根据KG推理得到所有的answer节点。
4. 负采样,选择answer节点之外的节点,作为query的错误answer。
举例说明。如果你想得到下面这个query作为样本。假设我们随机抽样,抽样到Fulvestrant作为answer节点,然后根据模板,反着推理。从Fulvestrant可以反推到anchor节点short of breath 和节点breast cancer。节点breast cancer可以接着反推到anchor节点ESR2。然后,我们再利用两个anchor节点,顺着推理得到 answer节点集(最右边的四个节点)。接着我们就能负采样不属于answer节点集的节点。