Hadoop伪分布式环境搭建
Hadoop伪分布式环境搭建
-
- 0.实验准备
- 1.下载linux版本的jdk,hadoop
- 2.下载MobaXterm远程连接Linux的工具
- 3.linux远程连接服务器
- 4.在根目录/下创建tools和training两个目录
- 5.利用ftp工具上传jdk,hadoop
- 6.执行以下命令解压安装jdk,hadoop到training目录下
- 7.配置环境变量:
- 8.让环境变量生效:
- 9.验证是否生效:
- 10.虚拟机主机名的设置
- 11、虚拟机主机名与ip地址的映射关系
- 12.windows上配置虚拟机ip地址与虚拟机主机名称的对应关系(为后面web页面访问和编程做准备)
- 13、关闭防火墙
- 14、禁用selinux
- 15.设置静态ip
- 16.配置文件
-
-
- (1)hadoop-env.sh
- (2)hdfs-site.xml
- (3)core-site.xml
- (4)mapred-site.xml (这个文件事先是不存在的,需要复制一份)
- (5)配置yarn-site.xml文件:
-
- 17.格式化:HDFS(NameNode)
- 18.配置SSH免密登录
- 19.启动hadoop环境
- 120.验证:
-
-
- (1)web界面进行验证
- (2)执行jps命令,看看是否会有如下进程
-
0.实验准备
1.下载linux版本的jdk,hadoop
官网下载对应版本jdk jdk下载
官网下载对应版本hadoop hadoop下载
链接:hadoop网盘下载
提取码:e90m
链接:jdk网盘下载
提取码:8v09
2.下载MobaXterm远程连接Linux的工具
官网下载 Mobaterm
3.linux远程连接服务器
用MobaXterm连入一个linux系统。新建一个新的session,然后输入系统的ip和用户名。SSH的x11-forwarding功能提供了一个非常好的方法,在你的本地主机上执行远程主机的GUI程序(远程运行图形化程序);如果已被禁用或不支持,则:
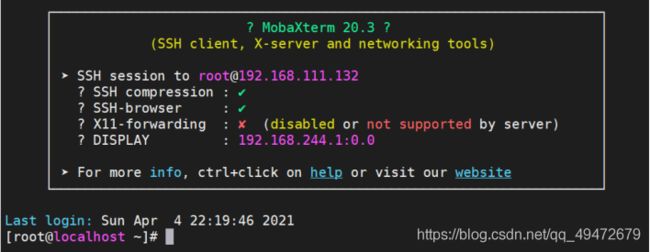
解决办法:安装xorg-x11-xauth
命令:yum install xorg-x11-xauth
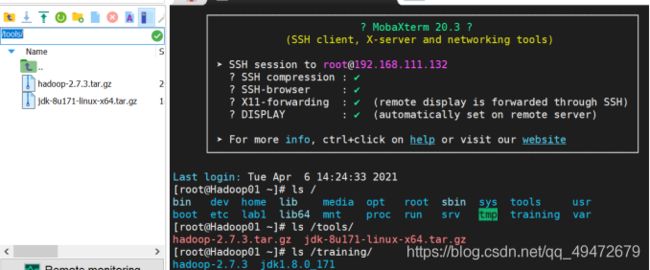
4.在根目录/下创建tools和training两个目录
mkdir /tools
mkdir /training
5.利用ftp工具上传jdk,hadoop
将jdk、hadoop安装包到/tools目录下(将左上边/root/目录切换到/tools/,再把hadoop,jdk压缩包直接拖到左下方空白区域上传)
6.执行以下命令解压安装jdk,hadoop到training目录下
tar -zvxf jdk-8u171-linux-x64.tar.gz -C /training/
tar -zvxf hadoop-2.7.3.tar.gz -C /training/
7.配置环境变量:
vi ~/.bash_profile
(root用户在.bash_profile中配置,普通用户在/etc/profile/中配置,作用于全局。用vi编辑器打开,按i或o编辑,按 esc键+:wq 保存并退出)
在.bash_profile文件中添加如下信息:
export JAVA_HOME=/training/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export HADOOP_HOME=/training/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
8.让环境变量生效:
source ~/.bash_profile
9.验证是否生效:
执行java或javac或java -version;hdfs 或hadoop或hadoop version 有相关信息出现即可。
10.虚拟机主机名的设置
hostnamectl --static set-hostname hadoop01
说明:--static 参数代表永久生效 hadoop01表示你希望设置的主机名 (主机名保存在/etc/hostname/ 中,也可以在/etc/sysconfig/network这个路径下配置主机名)
11、虚拟机主机名与ip地址的映射关系
(在/etc/hosts中编辑,主要是为了方便和出现ip地址问题时只需要在该路径下直接修改此ip地址即可。ip地址用ip addr(或 ip a)查看)
vi /etc/hosts
先按i或o,进入编辑模式,再在文件的末尾添加类似于 192.168.111.132 hadoop01这样的格式ip和主机名称选择自己的即可。esc+:wq退出并保存
12.windows上配置虚拟机ip地址与虚拟机主机名称的对应关系(为后面web页面访问和编程做准备)
进入到C:\Windows\System32\drivers\etc文件夹下,找到hosts文件,使用文本工具如 nodepad++打开,在文件末尾添加虚拟机ip和主机名 如下:
192.168.111.132 hadoop01
13、关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service (开机启动时也关闭)
用systemctl status firewalld.service命令查看防火墙状态(inactive(dead)即为关闭)
14、禁用selinux
永久关闭selinux安全策略,可以修改/etc/selinux/config,用以下命令
vi /etc/selinux/config
将SELINUX=enforcing改为SELINUX=disabled
关闭selinux
setenforce 0
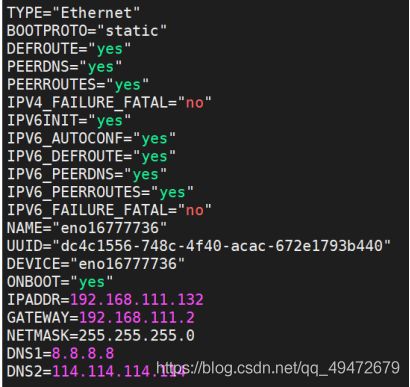
15.设置静态ip
用vi /etc/sysconfig/network-scripts/ifcfg-eno16777736 命令(eno16777736是自己的网卡,各电脑不同,事先不知道网卡可以切换到 cd /etc/ysconfig/network-scripts/目录下查看)将DHCP一栏改为static;ONBOOT改为yes;再添加IPADDR;GATEWAY前三个与ip一样,最后设为2;再添加子网掩码netmask(都一样)和DNS服务器(都一样)
16.配置文件
进入到/training/hadoop-2.7.3/etc/hadoop目录下 cd /training/hadoop-2.7.3/etc/hadoop 需要对五个文件进行配置:
(1)hadoop-env.sh
在hadoop-env.sh 文件中找到JAVA_HOME,并进行如下修改
export JAVA_HOME=/training/jdk1.8.0_171 (jdk的安装目录)
(2)hdfs-site.xml
配置hdfs-site.xml文件:
vi /training/hadoop-2.7.3/etc/hadoop/hdfs-site.xml
在hdfs-site.xml文件的
<property>
<!-- 指定HDFS副本的数量 -->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
(3)core-site.xml
vi /training/hadoop-2.7.3/etc/hadoop/core-site.xml
在core-site.xml文件的
<property>
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<!-- 指定hadoop运行时产生临时文件的存储目录 -->
<name>hadoop.tmp.dir</name>
<value>/training/hadoop-2.7.3/tmp</value>
</property>
(4)mapred-site.xml (这个文件事先是不存在的,需要复制一份)
在/training/hadoop-2.7.3/etc/hadoop/目录下
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
在mapper-site.xml文件的
<property>
<!-- 指定mr运行在yarn上 -->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
(5)配置yarn-site.xml文件:
vi /training/hadoop-2.7.3/etc/hadoop/yarn-site.xml
在yarn-site.xml文件的
<!-- Site specific YARN configuration properties -->
<property>
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!--配置Log Server -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
17.格式化:HDFS(NameNode)
执行命令:
hdfs namenode -format
如格式化成功,在打印出来的日志可以看到如下信息:
![]()
18.配置SSH免密登录
Hadoop各组件之间使用SSH登录,为了免输密码,可以设计SSH免密码登录。
(1)cd /root/.ssh (进入密钥存放目录)
(2)rm -rf * (删除旧密钥)
(3)ssh-keygen -t rsa (生成新密码,连续按三次回车)
(查看 ls /root/.ssh 会有id_rsa私钥,id_rsa.pub公钥)
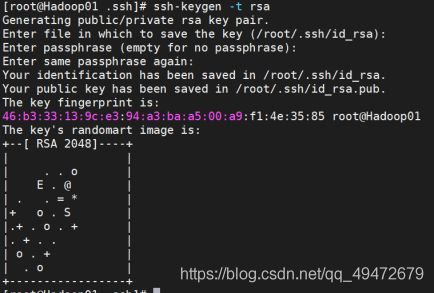
(4)ssh-copy-id -i id_rsa.pub root@hadoop01(将密钥赋予当前主机。输入命令后回
车;输入yes回车;再回车即可;可以用ssh hadoop01命令测试,回到hadoop01根目录即成功)
19.启动hadoop环境
启动服务 start-all.sh
120.验证:
(1)web界面进行验证
HDFS:http://hadoop01:50070 (或者 192.168.111.132:50070)
Yarn:http://hadoop01:8088 (或者 192.168.111.132:8088)
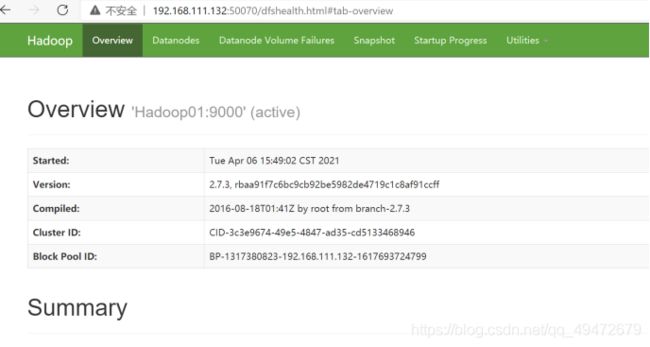
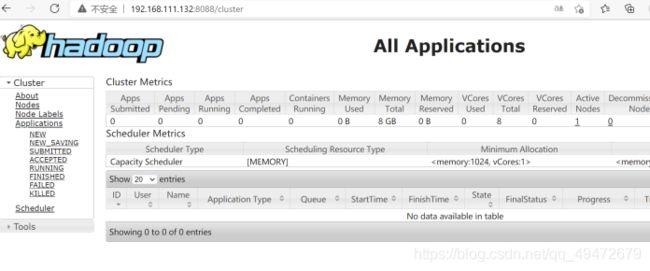
(2)执行jps命令,看看是否会有如下进程
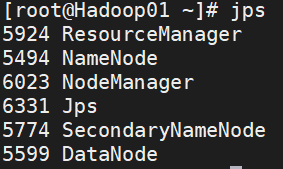
有即配置完成