深度学习 实验六 卷积神经网络(1)卷积 torch.nn
目录
- 第5章 卷积神经网络
-
- 5.1 卷积
-
- 5.1.1 二维卷积运算
- 5.1.2 二维卷积算子
- 5.1.3 二维卷积的参数量和计算量
- 5.1.4 感受野
- 5.1.5 卷积的变种
-
- 5.1.5.1 步长(Stride)
- 5.1.5.2 零填充(Zero Padding)
- 5.1.6 带步长和零填充的二维卷积算子
- 5.1.7 使用卷积运算完成图像边缘检测任务
- 总结
- 参考链接
第5章 卷积神经网络
卷积神经网络(Convolutional Neural Network,CNN)是受生物学上感受野机制的启发而提出的。目前的卷积神经网络一般是由卷积层、汇聚层和全连接层交叉堆叠而成的前馈神经网络,有三个结构上的特性:局部连接、权重共享以及汇聚。这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性。和前馈神经网络相比,卷积神经网络的参数更少。卷积神经网络主要应用在图像和视频分析的任务上,其准确率一般也远远超出了其他的神经网络模型。近年来卷积神经网络也广泛地应用到自然语言处理、推荐系统等领域。
在学习本章内容前,建议您先阅读《神经网络与深度学习》第5章:卷积神经网络的相关内容,关键知识点如 图5.1 所示,以便更好的理解和掌握书中的理论知识在实践中的应用方法。
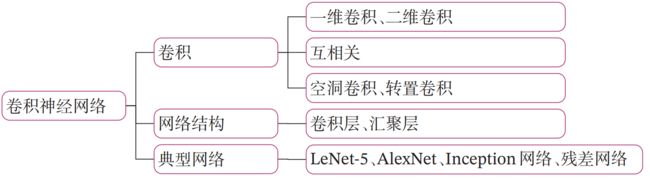
本实践基于 《神经网络与深度学习》第5章:卷积神经网络 相关内容进行设计,主要包含两部分:
- 模型解读:介绍卷积的原理、卷积神经网络的网络结构、残差连接的原理以及残差网络的网络结构,并使用简单卷积神经网络和残差网络,完成手写数字识别任务;
- 案例与实践:基于残差网络ResNet18完成CIFAR-10图像分类任务。
5.1 卷积
考虑到使用全连接前馈网络来处理图像时,会出现如下问题:
-
模型参数过多,容易发生过拟合。 在全连接前馈网络中,隐藏层的每个神经元都要跟该层所有输入的神经元相连接。随着隐藏层神经元数量的增多,参数的规模也会急剧增加,导致整个神经网络的训练效率非常低,也很容易发生过拟合。
-
难以提取图像中的局部不变性特征。 自然图像中的物体都具有局部不变性特征,比如尺度缩放、平移、旋转等操作不影响其语义信息。而全连接前馈网络很难提取这些局部不变性特征。
卷积神经网络有三个结构上的特性:局部连接、权重共享和汇聚。这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性。和前馈神经网络相比,卷积神经网络的参数也更少。因此,通常会使用卷积神经网络来处理图像信息。
卷积是分析数学中的一种重要运算,常用于信号处理或图像处理任务。本节以二维卷积为例来进行实践。
5.1.1 二维卷积运算
在机器学习和图像处理领域,卷积的主要功能是在一个图像(或特征图)上滑动一个卷积核,通过卷积操作得到一组新的特征。在计算卷积的过程中,需要进行卷积核的翻转,而这也会带来一些不必要的操作和开销。因此,在具体实现上,一般会以数学中的互相关(Cross-Correlatio)运算来代替卷积。
在神经网络中,卷积运算的主要作用是抽取特征,卷积核是否进行翻转并不会影响其特征抽取的能力。特别是当卷积核是可学习的参数时,卷积和互相关在能力上是等价的。因此,很多时候,为方便起见,会直接用互相关来代替卷积。
说明:
在本案例之后的描述中,除非特别声明,卷积一般指“互相关”。
对于一个输入矩阵 X ∈ R M × N \mathbf X\in\Bbb{R}^{M\times N} X∈RM×N和一个滤波器 W ∈ R U × V \mathbf W \in\Bbb{R}^{U\times V} W∈RU×V,它们的卷积为
y i , j = ∑ u = 0 U − 1 ∑ v = 0 V − 1 w u v x i + u , j + v 。( 5.1 ) y_{i,j}=\sum_{u=0}^{U-1} \sum_{v=0}^{V-1} w_{uv}x_{i+u,j+v}。(5.1) yi,j=u=0∑U−1v=0∑V−1wuvxi+u,j+v。(5.1)
说明:
这里和《神经网络与深度学习》中的定义区别是矩阵的下标从0开始。
图5.2 给出了卷积计算的示例。

图5.2:卷积操作的计算过程
经过卷积运算后,最终输出矩阵大小则为
M ′ = M − U + 1 , ( 5.2 ) M' = M - U + 1,(5.2) M′=M−U+1,(5.2)
N ′ = N − V + 1. ( 5.3 ) N' = N - V + 1.(5.3) N′=N−V+1.(5.3)
可以发现,使用卷积处理图像,会有以下两个特性:
- 在卷积层(假设是第 l l l层)中的每一个神经元都只和前一层(第 l − 1 l-1 l−1层)中某个局部窗口内的神经元相连,构成一个局部连接网络,这也就是卷积神经网络的局部连接特性。
- 由于卷积的主要功能是在一个图像(或特征图)上滑动一个卷积核,所以作为参数的卷积核 W ∈ R U × V \mathbf W \in\Bbb{R}^{U\times V} W∈RU×V对于第 l l l层的所有的神经元都是相同的,这也就是卷积神经网络的权重共享特性。
5.1.2 二维卷积算子
在本书后面的实现中,算子都继承paddle.nn.Layer,并使用支持反向传播的飞桨API进行实现,这样我们就可以不用手工写backword()的代码实现。
根据公式(5.1),我们首先实现一个简单的二维卷积算子,代码实现如下:
import torch
import torch.nn as nn
class Conv2D(nn.Module):
def __init__(self, kernel_size,
weight_attr = nn.Parameter(torch.FloatTensor([[0., 1.],[2., 3.]]))):
super(Conv2D, self).__init__()
self.weight = weight_attr
def forward(self, X):
"""
输入:
- X:输入矩阵,shape=[B, M, N],B为样本数量
输出:
- output:输出矩阵
"""
u, v = self.weight.shape
output = torch.zeros([X.shape[0], X.shape[1] - u + 1, X.shape[2] - v + 1])
for i in range(output.shape[1]):
for j in range(output.shape[2]):
output[:, i, j] = torch.sum(X[:, i:i+u, j:j+v]*self.weight, axis=[1,2])
return output
# 随机构造一个二维输入矩阵
inputs = torch.as_tensor([[[1.,2.,3.],[4.,5.,6.],[7.,8.,9.]]])
conv2d = Conv2D(kernel_size=2)
outputs = conv2d(inputs)
print("input: {}, \noutput: {}".format(inputs, outputs))
运行结果:
input: tensor([[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]]]),
output: tensor([[[25., 31.],
[43., 49.]]], grad_fn=)
5.1.3 二维卷积的参数量和计算量
参数量
由于二维卷积的运算方式为在一个图像(或特征图)上滑动一个卷积核,通过卷积操作得到一组新的特征。所以参数量仅仅与卷积核的尺寸有关,对于一个输入矩阵 X ∈ R M × N \mathbf X\in\Bbb{R}^{M\times N} X∈RM×N和一个滤波器 W ∈ R U × V \mathbf W \in\Bbb{R}^{U\times V} W∈RU×V,卷积核的参数量为 U × V U\times V U×V。
假设有一幅大小为 32 × 32 32\times 32 32×32的图像,如果使用全连接前馈网络进行处理,即便第一个隐藏层神经元个数为1,此时该层的参数量也高达 1025 1025 1025个,此时该层的计算过程如 图5.3 所示。

图5.3:使用全连接前馈网络处理图像数据的计算过程
可以想像,随着隐藏层神经元数量的变多以及层数的加深,使用全连接前馈网络处理图像数据时,参数量会急剧增加。
如果使用卷积进行图像处理,当卷积核为 3 × 3 3\times 3 3×3时,参数量仅为 9 9 9,相较于全连接前馈网络,参数量少了非常多。
计算量
在卷积神经网络中运算时,通常会统计网络总的乘加运算次数作为计算量(FLOPs,floating point of operations),来衡量整个网络的运算速度。对于单个二维卷积,计算量的统计方式为:
F L O P s = M ′ × N ′ × U × V 。( 5.4 ) FLOPs=M'\times N'\times U\times V。(5.4) FLOPs=M′×N′×U×V。(5.4)
其中 M ′ × N ′ M'\times N' M′×N′表示输出特征图的尺寸,即输出特征图上每个点都要与卷积核 W ∈ R U × V \mathbf W \in\Bbb{R}^{U\times V} W∈RU×V进行 U × V U\times V U×V次乘加运算。对于一幅大小为 32 × 32 32\times 32 32×32的图像,使用 3 × 3 3\times 3 3×3的卷积核进行运算可以得到以下的输出特征图尺寸:
M ′ = M − U + 1 = 30 M' = M - U + 1 = 30 M′=M−U+1=30
N ′ = N − V + 1 = 30 N' = N - V + 1 = 30 N′=N−V+1=30
此时,计算量为:
F L O P s = M ′ × N ′ × U × V = 30 × 30 × 3 × 3 = 8100 FLOPs=M'\times N'\times U\times V=30\times 30\times 3\times 3=8100 FLOPs=M′×N′×U×V=30×30×3×3=8100
5.1.4 感受野
输出特征图上每个点的数值,是由输入图片上大小为 U × V U\times V U×V的区域的元素与卷积核每个元素相乘再相加得到的,所以输入图像上 U × V U\times V U×V区域内每个元素数值的改变,都会影响输出点的像素值。我们将这个区域叫做输出特征图上对应点的感受野。感受野内每个元素数值的变动,都会影响输出点的数值变化。比如 3 × 3 3\times3 3×3卷积对应的感受野大小就是 3 × 3 3\times3 3×3,如 图5.4 所示。
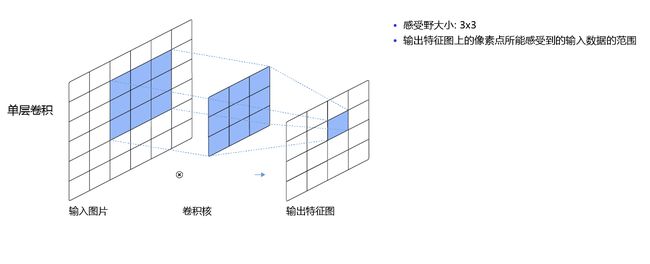
图5.4:感受野为3×3的卷积
而当通过两层 3 × 3 3\times3 3×3的卷积之后,感受野的大小将会增加到 5 × 5 5\times5 5×5,如 图5.5 所示。
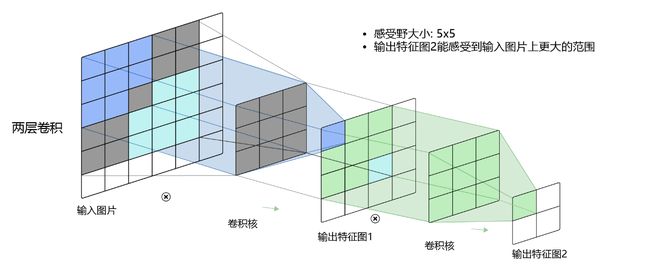
图5.5:感受野为5×5的卷积
因此,当增加卷积网络深度的同时,感受野将会增大,输出特征图中的一个像素点将会包含更多的图像语义信息。
5.1.5 卷积的变种
在卷积的标准定义基础上,还可以引入卷积核的滑动步长和零填充来增加卷积的多样性,从而更灵活地进行特征抽取。
5.1.5.1 步长(Stride)
在卷积运算的过程中,有时会希望跳过一些位置来降低计算的开销,也可以把这一过程看作是对标准卷积运算输出的下采样。
在计算卷积时,可以在所有维度上每间隔 S S S个元素计算一次, S S S称为卷积运算的步长(Stride),也就是卷积核在滑动时的间隔。
此时,对于一个输入矩阵 X ∈ R M × N \mathbf X\in\Bbb{R}^{M\times N} X∈RM×N和一个滤波器 W ∈ R U × V \mathbf W \in\Bbb{R}^{U\times V} W∈RU×V,它们的卷积为
y i , j = ∑ u = 0 U − 1 ∑ v = 0 V − 1 w u v x i × S + u , j × S + v ,( 5.5 ) y_{i,j}=\sum_{u=0}^{U-1} \sum_{v=0}^{V-1} w_{uv}x_{i\times S+u,j\times S+v},(5.5) yi,j=u=0∑U−1v=0∑V−1wuvxi×S+u,j×S+v,(5.5)
在二维卷积运算中,当步长 S = 2 S=2 S=2时,计算过程如 图5.6 所示。
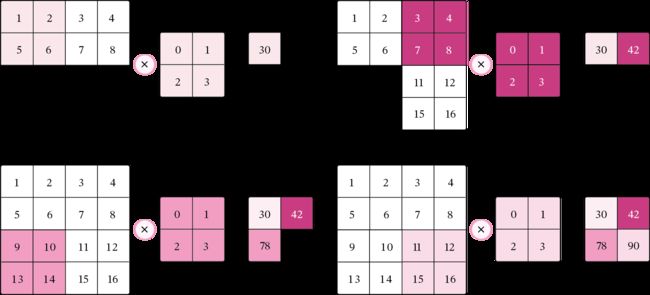
图5.6:步长为2的二维卷积计算过程
5.1.5.2 零填充(Zero Padding)
在卷积运算中,还可以对输入用零进行填充使得其尺寸变大。根据卷积的定义,如果不进行填充,当卷积核尺寸大于1时,输出特征会缩减。对输入进行零填充则可以对卷积核的宽度和输出的大小进行独立的控制。
在二维卷积运算中,零填充(Zero Padding)是指在输入矩阵周围对称地补上 P P P个 0 0 0。图5.7 为使用零填充的示例。

图5.7:padding=1的零填充
对于一个输入矩阵 X ∈ R M × N \mathbf X\in\Bbb{R}^{M\times N} X∈RM×N和一个滤波器 W ∈ R U × V \mathbf W \in\Bbb{R}^{U\times V} W∈RU×V,,步长为 S S S,对输入矩阵进行零填充,那么最终输出矩阵大小则为
M ′ = M + 2 P − U S + 1 , ( 5.6 ) M' = \frac{M + 2P - U}{S} + 1,(5.6) M′=SM+2P−U+1,(5.6)
N ′ = N + 2 P − V S + 1. ( 5.7 ) N' = \frac{N + 2P - V}{S} + 1.(5.7) N′=SN+2P−V+1.(5.7)
引入步长和零填充后的卷积,参数量和计算量的统计方式与之前一致,参数量与卷积核的尺寸有关,为: U × V U\times V U×V,计算量与输出特征图和卷积核的尺寸有关,为:
F L O P s = M ′ × N ′ × U × V = ( M + 2 P − U S + 1 ) × ( N + 2 P − V S + 1 ) × U × V 。( 5.8 ) FLOPs=M'\times N'\times U\times V=(\frac{M + 2P - U}{S} + 1)\times (\frac{N + 2P - V}{S} + 1)\times U\times V。(5.8) FLOPs=M′×N′×U×V=(SM+2P−U+1)×(SN+2P−V+1)×U×V。(5.8)
一般常用的卷积有以下三类:
- 窄卷积:步长 S = 1 S=1 S=1,两端不补零 P = 0 P=0 P=0,卷积后输出尺寸为:
M ′ = M − U + 1 , ( 5.9 ) M' = M - U + 1,(5.9) M′=M−U+1,(5.9)
N ′ = N − V + 1. ( 5.10 ) N' = N - V + 1.(5.10) N′=N−V+1.(5.10)
- 宽卷积:步长 S = 1 S=1 S=1,两端补零 P = U − 1 = V − 1 P=U-1=V-1 P=U−1=V−1,卷积后输出尺寸为:
M ′ = M + U − 1 , ( 5.11 ) M' = M + U - 1,(5.11) M′=M+U−1,(5.11)
N ′ = N + V − 1. ( 5.12 ) N' = N + V - 1.(5.12) N′=N+V−1.(5.12)
- 等宽卷积:步长 S = 1 S=1 S=1,两端补零 P = ( U − 1 ) 2 = ( V − 1 ) 2 P=\frac{(U-1)}{2}=\frac{(V-1)}{2} P=2(U−1)=2(V−1),卷积后输出尺寸为:
M ′ = M , ( 5.13 ) M' = M,(5.13) M′=M,(5.13)
N ′ = N . ( 5.14 ) N' = N.(5.14) N′=N.(5.14)
通常情况下,在层数较深的卷积神经网络,比如:VGG、ResNet中,会使用等宽卷积保证输出特征图的大小不会随着层数的变深而快速缩减。例如:当卷积核的大小为 3 × 3 3\times 3 3×3时,会将步长设置为 S = 1 S=1 S=1,两端补零 P = 1 P=1 P=1,此时,卷积后的输出尺寸就可以保持不变。在本章后续的案例中,会使用ResNet进行实验。
5.1.6 带步长和零填充的二维卷积算子
引入步长和零填充后,二维卷积算子代码实现如下:
class Conv2D(nn.Module):
def __init__(self, kernel_size, stride=1, padding=0):
super(Conv2D, self).__init__()
weight_attr = torch.ones(size=[kernel_size,kernel_size])
torch.nn.init.constant_(weight_attr,1.0)
self.weight = torch.nn.Parameter(weight_attr)
# 步长
self.stride = stride
# 零填充
self.padding = padding
def forward(self, X):
# 零填充
new_X = torch.zeros([X.shape[0], X.shape[1]+2*self.padding, X.shape[2]+2*self.padding])
new_X[:, self.padding:X.shape[1]+self.padding, self.padding:X.shape[2]+self.padding] = X
u, v = self.weight.shape
output_w = (new_X.shape[1] - u) // self.stride + 1
output_h = (new_X.shape[2] - v) // self.stride + 1
output = torch.zeros([X.shape[0], output_w, output_h])
for i in range(0, output.shape[1]):
for j in range(0, output.shape[2]):
output[:, i, j] = torch.sum(
new_X[:, self.stride*i:self.stride*i+u, self.stride*j:self.stride*j+v]*self.weight,
axis=[1,2])
return output
inputs = torch.randn(size=[2, 8, 8])
conv2d_padding = Conv2D(kernel_size=3, padding=1)
outputs = conv2d_padding(inputs)
print("When kernel_size=3, padding=1 stride=1, input's shape: {}, output's shape: {}".format(inputs.shape, outputs.shape))
conv2d_stride = Conv2D(kernel_size=3, stride=2, padding=1)
outputs = conv2d_stride(inputs)
print("When kernel_size=3, padding=1 stride=2, input's shape: {}, output's shape: {}".format(inputs.shape, outputs.shape))
运行结果:
When kernel_size=3, padding=1 stride=1, input's shape: torch.Size([2, 8, 8]), output's shape: torch.Size([2, 8, 8])
When kernel_size=3, padding=1 stride=2, input's shape: torch.Size([2, 8, 8]), output's shape: torch.Size([2, 4, 4])
从输出结果看出,使用 3 × 3 3\times3 3×3大小卷积,padding为1,当stride=1时,模型的输出特征图可以与输入特征图保持一致;当stride=2时,输出特征图的宽和高都缩小一倍。
5.1.7 使用卷积运算完成图像边缘检测任务
在图像处理任务中,常用拉普拉斯算子对物体边缘进行提取,拉普拉斯算子为一个大小为 3 × 3 3 \times 3 3×3的卷积核,中心元素值是 8 8 8,其余元素值是 − 1 -1 −1。
考虑到边缘其实就是图像上像素值变化很大的点的集合,因此可以通过计算二阶微分得到,当二阶微分为0时,像素值的变化最大。此时,对 x x x方向和 y y y方向分别求取二阶导数:
δ 2 I δ x 2 = I ( i , j + 1 ) − 2 I ( i , j ) + I ( i , j − 1 ) , ( 5.15 ) \frac{\delta^2 I}{\delta x^2} = I(i, j+1) - 2I(i,j) + I(i,j-1),(5.15) δx2δ2I=I(i,j+1)−2I(i,j)+I(i,j−1),(5.15) δ 2 I δ y 2 = I ( i + 1 , j ) − 2 I ( i , j ) + I ( i − 1 , j ) . ( 5.16 ) \frac{\delta^2 I}{\delta y^2} = I(i+1, j) - 2I(i,j) + I(i-1,j).(5.16) δy2δ2I=I(i+1,j)−2I(i,j)+I(i−1,j).(5.16)
完整的二阶微分公式为:
∇ 2 I = δ 2 I δ x 2 + δ 2 I δ y 2 = − 4 I ( i , j ) + I ( i , j − 1 ) + I ( i , j + 1 ) + I ( i + 1 , j ) + I ( i − 1 , j ) , ( 5.17 ) \nabla^2I = \frac{\delta^2 I}{\delta x^2} + \frac{\delta^2 I}{\delta y^2} = - 4I(i,j) + I(i,j-1) + I(i, j+1) + I(i+1, j) + I(i-1,j),(5.17) ∇2I=δx2δ2I+δy2δ2I=−4I(i,j)+I(i,j−1)+I(i,j+1)+I(i+1,j)+I(i−1,j),(5.17)
上述公式也被称为拉普拉斯算子,对应的二阶微分卷积核为:
[ 0 1 0 1 − 4 1 0 1 0 ] \begin{bmatrix} 0 & 1 & 0 \\ 1 & -4 & 1 \\ 0 & 1 & 0 \\ \end{bmatrix} ⎣ ⎡0101−41010⎦ ⎤
对上述算子全部求反也可以起到相同的作用,此时,该算子可以表示为:
[ 0 − 1 0 − 1 4 − 1 0 − 1 0 ] \begin{bmatrix} 0 & -1 & 0 \\ -1 & 4 & -1 \\ 0 & -1 & 0 \\ \end{bmatrix} ⎣ ⎡0−10−14−10−10⎦ ⎤
也就是一个点的四邻域拉普拉斯的算子计算结果是自己像素值的四倍减去上下左右的像素的和,将这个算子旋转 45 ° 45° 45°后与原算子相加,就变成八邻域的拉普拉斯算子,也就是一个像素自己值的八倍减去周围一圈八个像素值的和,做为拉普拉斯计算结果,此时,该算子可以表示为:
[ − 1 − 1 − 1 − 1 8 − 1 − 1 − 1 − 1 ] \begin{bmatrix} -1 & -1 & -1 \\ -1 & 8 & -1 \\ -1 & -1 & -1 \\ \end{bmatrix} ⎣ ⎡−1−1−1−18−1−1−1−1⎦ ⎤
下面我们利用上面定义的Conv2D算子,构造一个简单的拉普拉斯算子,并对一张输入的灰度图片进行边缘检测,提取出目标的外形轮廓。
%matplotlib inline
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
# 读取图片
img = Image.open('/kaggle/input/picdata/kasha.jpeg').convert('L')
img.resize((256,256))
# 设置卷积核参数
w = np.array([[-1,-1,-1], [-1,8,-1], [-1,-1,-1]], dtype='float32')
# 创建卷积算子,卷积核大小为3x3,并使用上面的设置好的数值作为卷积核权重的初始化参数
conv = Conv2D(kernel_size=3, stride=1, padding=0, weight_attr=torch.tensor(w))
# 将读入的图片转化为float32类型的numpy.ndarray
inputs = np.array(img).astype('float32')
print("bf to_tensor, inputs:",inputs)
# 将图片转为Tensor
inputs = torch.tensor(inputs)
print("bf unsqueeze, inputs:",inputs)
inputs = torch.unsqueeze(inputs, axis=0)
print("af unsqueeze, inputs:",inputs)
outputs = conv(inputs)
# outputs = outputs.detach().numpy()
# 可视化结果
plt.figure(figsize=(8, 4))
f = plt.subplot(121)
f.set_title('input image', fontsize=15)
plt.imshow(img)
f = plt.subplot(122)
f.set_title('output feature map', fontsize=15)
plt.imshow(outputs.detach().numpy().squeeze(), cmap='gray')
plt.savefig('conv-vis.pdf')
plt.show()
运行结果:
bf to_tensor, inputs: [[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 2. 0.
0. 1. 0. 1. 0. 2. 0. 0. 0. 2. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0.
1. 0. 0. 3. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0.
0. 1. 0. 0. 0. 0. 0. 1. 5. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 4. 1. 0. 1.
0. 0. 0. 0. 1. 0. 3. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 2. 1. 2.
0. 2. 0. 0. 0. 0. 0. 4. 0. 1. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 4. 0. 0. 0. 0.
3. 1. 0. 0. 3. 0. 0. 0. 2. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 3. 1. 2.
43. 157. 248. 246. 244. 37. 0. 1. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 47. 230.
247. 251. 190. 164. 248. 207. 1. 0. 2. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 53. 219. 248. 247.
246. 176. 0. 0. 250. 245. 0. 1. 0. 1. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 1. 2. 242. 248. 247. 248.
177. 0. 0. 2. 241. 251. 0. 0. 1. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 108. 248. 244. 183. 82.
0. 1. 0. 0. 251. 244. 2. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 1. 0. 0.
2. 0. 0. 0. 246. 247. 0. 0. 0. 4. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 4. 0.
0. 3. 1. 58. 249. 247. 0. 0. 1. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 3.
0. 0. 1. 150. 243. 128. 0. 1. 0. 1. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 2. 101. 248.
252. 252. 247. 249. 201. 3. 0. 3. 3. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 197. 249. 228. 201.
82. 227. 248. 247. 202. 1. 1. 0. 0. 1. 0. 0. 0. 0.]
[ 1. 0. 0. 0. 1. 0. 1. 0. 0. 249. 244. 1. 0. 0.
1. 158. 246. 246. 247. 248. 0. 0. 0. 1. 0. 0. 0. 1.]
[ 0. 0. 4. 0. 1. 2. 0. 14. 246. 248. 106. 0. 4. 0.
150. 250. 239. 0. 89. 247. 247. 112. 2. 0. 2. 1. 2. 0.]
[ 0. 0. 3. 0. 0. 0. 15. 246. 224. 1. 0. 1. 0. 143.
247. 173. 0. 3. 0. 1. 68. 227. 243. 248. 190. 0. 0. 0.]
[ 1. 0. 0. 1. 2. 2. 244. 228. 2. 0. 0. 84. 229. 245.
0. 2. 0. 0. 2. 1. 0. 1. 104. 105. 0. 0. 0. 4.]
[ 0. 1. 0. 1. 0. 202. 249. 234. 152. 173. 246. 249. 247. 4.
2. 0. 3. 2. 0. 0. 0. 4. 0. 0. 2. 0. 3. 0.]
[ 2. 0. 0. 0. 0. 160. 247. 246. 246. 249. 102. 0. 0. 0.
0. 0. 0. 0. 2. 0. 4. 0. 0. 3. 0. 2. 0. 0.]
[ 0. 0. 4. 0. 0. 0. 0. 30. 2. 0. 0. 1. 2. 0.
1. 1. 1. 1. 0. 0. 0. 0. 4. 0. 1. 0. 0. 3.]
[ 0. 3. 0. 0. 1. 2. 0. 0. 0. 0. 1. 0. 0. 0.
0. 0. 0. 1. 2. 0. 1. 0. 0. 0. 0. 1. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
bf unsqueeze, inputs: tensor([[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
2., 0., 0., 1., 0., 1., 0., 2., 0., 0., 0., 2.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0.,
0., 0., 1., 0., 0., 3., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0., 0.,
0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 5., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 4., 1.,
0., 1., 0., 0., 0., 0., 1., 0., 3., 0., 0., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 2.,
1., 2., 0., 2., 0., 0., 0., 0., 0., 4., 0., 1.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 4., 0., 0.,
0., 0., 3., 1., 0., 0., 3., 0., 0., 0., 2., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 3.,
1., 2., 43., 157., 248., 246., 244., 37., 0., 1., 0., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.,
47., 230., 247., 251., 190., 164., 248., 207., 1., 0., 2., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 53., 219.,
248., 247., 246., 176., 0., 0., 250., 245., 0., 1., 0., 1.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 1., 2., 242., 248.,
247., 248., 177., 0., 0., 2., 241., 251., 0., 0., 1., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 108., 248., 244.,
183., 82., 0., 1., 0., 0., 251., 244., 2., 0., 0., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0., 1.,
0., 0., 2., 0., 0., 0., 246., 247., 0., 0., 0., 4.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,
4., 0., 0., 3., 1., 58., 249., 247., 0., 0., 1., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.,
0., 3., 0., 0., 1., 150., 243., 128., 0., 1., 0., 1.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0., 2.,
101., 248., 252., 252., 247., 249., 201., 3., 0., 3., 3., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 197., 249.,
228., 201., 82., 227., 248., 247., 202., 1., 1., 0., 0., 1.,
0., 0., 0., 0.],
[ 1., 0., 0., 0., 1., 0., 1., 0., 0., 249., 244., 1.,
0., 0., 1., 158., 246., 246., 247., 248., 0., 0., 0., 1.,
0., 0., 0., 1.],
[ 0., 0., 4., 0., 1., 2., 0., 14., 246., 248., 106., 0.,
4., 0., 150., 250., 239., 0., 89., 247., 247., 112., 2., 0.,
2., 1., 2., 0.],
[ 0., 0., 3., 0., 0., 0., 15., 246., 224., 1., 0., 1.,
0., 143., 247., 173., 0., 3., 0., 1., 68., 227., 243., 248.,
190., 0., 0., 0.],
[ 1., 0., 0., 1., 2., 2., 244., 228., 2., 0., 0., 84.,
229., 245., 0., 2., 0., 0., 2., 1., 0., 1., 104., 105.,
0., 0., 0., 4.],
[ 0., 1., 0., 1., 0., 202., 249., 234., 152., 173., 246., 249.,
247., 4., 2., 0., 3., 2., 0., 0., 0., 4., 0., 0.,
2., 0., 3., 0.],
[ 2., 0., 0., 0., 0., 160., 247., 246., 246., 249., 102., 0.,
0., 0., 0., 0., 0., 0., 2., 0., 4., 0., 0., 3.,
0., 2., 0., 0.],
[ 0., 0., 4., 0., 0., 0., 0., 30., 2., 0., 0., 1.,
2., 0., 1., 1., 1., 1., 0., 0., 0., 0., 4., 0.,
1., 0., 0., 3.],
[ 0., 3., 0., 0., 1., 2., 0., 0., 0., 0., 1., 0.,
0., 0., 0., 0., 0., 1., 2., 0., 1., 0., 0., 0.,
0., 1., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]])
af unsqueeze, inputs: tensor([[[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,
0., 2., 0., 0., 1., 0., 1., 0., 2., 0., 0.,
0., 2., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 2., 0.,
0., 0., 0., 1., 0., 0., 3., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0.,
0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1.,
5., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 4.,
1., 0., 1., 0., 0., 0., 0., 1., 0., 3., 0.,
0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
2., 1., 2., 0., 2., 0., 0., 0., 0., 0., 4.,
0., 1., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 4., 0.,
0., 0., 0., 3., 1., 0., 0., 3., 0., 0., 0.,
2., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
3., 1., 2., 43., 157., 248., 246., 244., 37., 0., 1.,
0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 47., 230., 247., 251., 190., 164., 248., 207., 1., 0.,
2., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 53.,
219., 248., 247., 246., 176., 0., 0., 250., 245., 0., 1.,
0., 1., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 1., 2., 242.,
248., 247., 248., 177., 0., 0., 2., 241., 251., 0., 0.,
1., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 108., 248.,
244., 183., 82., 0., 1., 0., 0., 251., 244., 2., 0.,
0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0.,
1., 0., 0., 2., 0., 0., 0., 246., 247., 0., 0.,
0., 4., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 4., 0., 0., 3., 1., 58., 249., 247., 0., 0.,
1., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,
0., 0., 3., 0., 0., 1., 150., 243., 128., 0., 1.,
0., 1., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 2., 0., 0.,
2., 101., 248., 252., 252., 247., 249., 201., 3., 0., 3.,
3., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 197.,
249., 228., 201., 82., 227., 248., 247., 202., 1., 1., 0.,
0., 1., 0., 0., 0., 0.],
[ 1., 0., 0., 0., 1., 0., 1., 0., 0., 249., 244.,
1., 0., 0., 1., 158., 246., 246., 247., 248., 0., 0.,
0., 1., 0., 0., 0., 1.],
[ 0., 0., 4., 0., 1., 2., 0., 14., 246., 248., 106.,
0., 4., 0., 150., 250., 239., 0., 89., 247., 247., 112.,
2., 0., 2., 1., 2., 0.],
[ 0., 0., 3., 0., 0., 0., 15., 246., 224., 1., 0.,
1., 0., 143., 247., 173., 0., 3., 0., 1., 68., 227.,
243., 248., 190., 0., 0., 0.],
[ 1., 0., 0., 1., 2., 2., 244., 228., 2., 0., 0.,
84., 229., 245., 0., 2., 0., 0., 2., 1., 0., 1.,
104., 105., 0., 0., 0., 4.],
[ 0., 1., 0., 1., 0., 202., 249., 234., 152., 173., 246.,
249., 247., 4., 2., 0., 3., 2., 0., 0., 0., 4.,
0., 0., 2., 0., 3., 0.],
[ 2., 0., 0., 0., 0., 160., 247., 246., 246., 249., 102.,
0., 0., 0., 0., 0., 0., 0., 2., 0., 4., 0.,
0., 3., 0., 2., 0., 0.],
[ 0., 0., 4., 0., 0., 0., 0., 30., 2., 0., 0.,
1., 2., 0., 1., 1., 1., 1., 0., 0., 0., 0.,
4., 0., 1., 0., 0., 3.],
[ 0., 3., 0., 0., 1., 2., 0., 0., 0., 0., 1.,
0., 0., 0., 0., 0., 0., 1., 2., 0., 1., 0.,
0., 0., 0., 1., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.],
[ 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0.]]])

总结
这里学习了卷积,这周的时间分配不合理,选做题(卷积核)的话,后续会单独写一章,还是很有意思的。卷积真的是一个很有趣的东西,无法想象是怎么通过计算来把一个图片处理成自己想要的图像,要加倍学这个卷积啊。
参考链接
这里可以看大纲:NNDL 实验六 卷积神经网络(1)卷积
这里比较详细:NNDL 实验5(上)

创作不易,如果对你有帮助,求求你给我个赞!!!
点赞 + 收藏 + 关注!!!
如有错误与建议,望告知!!!(将于下篇文章更正)
请多多关注我!!!谢谢!!!