ECCV 2022 | 清华&腾讯AI Lab提出REALY: 重新思考3D人脸重建的评估方法
作者丨人脸人体重建
来源丨人脸人体重建
编辑丨极市平台
极市导读
本文围绕3D人脸重建的评估方式进行了重新的思考和探索。作者团队通过构建新数据集RELAY,囊括了更丰富以及更高质量的脸部区域信息,并借助新的流程对先前的数十个重建算法、3DMM进行了评价。

本文分享ECCV 2022论文《REALY: Rethinking the Evaluation of 3D Face Reconstruction》,对3D人脸重建的评估方法进行重新思考。该论文提出一个新的3D人脸重建的benchmark数据集,名为REALY benchmark,和相应的评估方法,能对于重建的3D人脸模型在不同脸部区域进行细粒度评价,并对于主流的单张照片3D人脸重建算法进行了详细的评测。
另外,该论文同时公开了一个由近2000个人脸扫描模型构建的高质量全头模型3DMM基底:HIFI3D++,该基底相对于BFM、FWH、FaceScape、FLAME、LSFM、LYHM等3DMM基底有更强的表达能力和更高的Mesh模型质量。
相关代码和3DMM已开源。此项工作由清华大学与腾讯AI Lab合作完成。
论文链接:https://arxiv.org/abs/2203.09729
代码链接:https://github.com/czh-98/REALY
项目网站:https://www.realy3dface.com/
一、简介
3D人脸重建历经多年发展,不同的重建方案层出不穷,然而对于不同方法重建结果的定量评价却存在明显的问题和缺陷,即客观指标与人的主观感受难以相符。
回顾先前的3D人脸重建评价方案,基于3D顶点的评价流程通常借助关键点进行scale和pose的预对齐,并通过Iterative Closest Point (ICP)算法进行微调使得predicted mesh和ground-truth scan对齐,再通过两者的最近邻点建立顶点的对应关系,并计算这组对应关系的NMSE/RMSE作为指标。
本文首先分析这样的评价流程存在的问题,揭示了先前的评价方案无法与主观评价相吻合的重要原因:_即全局的刚性对齐会受到脸部局部区域重建质量的影响,并且根据单方向距离(最近邻点)建立的对应关系无法保证顶点之间语义信息的一致性。_所以我们构建了REALY benchmark,设计了新的3D人脸重建评价方案,并对先前的模型和3DMM进行了重新的评价,验证了我们的评价流程的合理性。
此外,在构建新的benchmark的过程中,我们通过整合约2000个高质量的人脸scan数据,进行拓扑结构的统一,从而构建了一个新的具有高表达能力的3DMM,其拓扑结构、基的维度都要优于先前的3DMM,并在RGB-(D) Fitting的比较中证明其表达能力和重建效果。
二、论文动机
先前的评价方案存在以下两个主要问题。
1. ICP对齐过程对局部区域的变化比较敏感。
直观而言,对于两个完全重合的3D mesh,如果我们只对predicted mesh的鼻子区域进行修改,理想状况下,两个mesh对齐结果应该如中间所示,因为其他区域在改变前后与ground-truth是完全重合的,两者的误差应该主要集中在鼻子区域;而根据以往的评价流程,全局对齐操作则会由于鼻子区域的变化,导致对齐后mesh整体的位置发生偏移而带来误差的放大。对此,本文将人脸的评估分为四个区域,分别对每一个区域进行对齐、评估,而不考虑其他区域的影响。

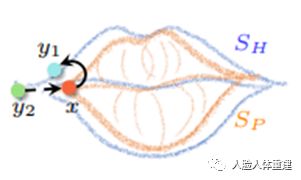
2. 单向的最近邻点建立的对应关系容易导致语义信息的不一致。
如图所示,对于predicted mesh上的某一点x,在计算误差时需要找到ground-truth scan上的对应点,若通过点到平面的最近距离建立对应关系,则可能为y1。这时,虽然y1是x距离最近的点,然而他们在语义信息上没有关联性,与嘴角的点x相关联的应该是y2,然而y2不会是x所对应的最近点。在这样的情况下,虽然计算得到的误差较小,但由于对应点之间的语义信息并不一致,因此计算得到的误差并不靠谱,较小的误差并不能表明较大的相似度。对此我们提出使用一步额外反方向非刚性对齐,并且其中增加了包含有语义信息的关键点损失,从而得到语义上更加一致的对应关系。
三、REALY
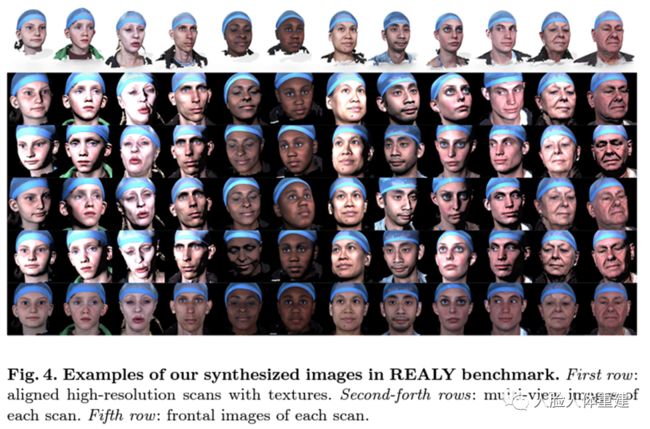
为了解决上述两个问题,我们首先构建了一个新的benchmark,包含100个2D图片-3D scan对,其中每个scan渲染了5个不同视角下(包含1个正脸和4个侧脸)的RGB图片及深度图片;对于每个3D scan,我们都得到了语义信息一致的68个关键点以及不同脸部区域的mask,并在此基础上首次实现了3D人脸在不同区域上的细粒度评价。我们的benchmark的部分数据如下图所示。

数据集的构建过程借助256个关键点进行对齐和转拓扑,确保了统一拓扑的mesh的质量,进而保证了不同id的人脸区域的mask以及关键点的一致性。

四、新的评价流程
在REALY的基础上,我们提出一个新的评价流程避免先前评价流程的问题,具体而言,我们的评价流程包含如下两个步骤:
局部区域的对齐:考虑到不同区域的重建质量会影响全局的对齐结果,由于我们的benchmark得到了不同脸部区域的mask,因此我们可以借助这个信息将predicted mesh对齐到ground-truth scan的特定区域,在error计算时只计算ground-truth scan上的特定区域与predicted mesh之间的误差,而不考虑脸部其他区域对于对齐结果以及误差计算的影响。

对应关系的建立:在局部对齐的基础上,我们需要建立ground-truth scan某一区域上的每一个点与predicted mesh之间的对应点并计算两者的误差。考虑到先前基于最近点的方式存在的问题,我们提出一个新的对应关系的建立方法,提高了关键点语义信息的一致性。
具体而言,我们首先通过最近点建立初步的对应关系;随后借助non-rigid ICP将ground-truth scan某一区域变形到predicted mesh上,由于变形后的区域与predicted mesh已经贴合,因为在变形过程中考虑了具备语义信息的关键点损失,所以这时的对应关系相比于原始的最近点的对应关系具有更好的语义关系的一致性(如,图3中脸部关键点的一致性),从而我们对初始的对应关系进行更新;最后,由于变形前后的拓扑形状的一致性,我们能够借助更新后的对应关系计算原始的ground-truth scan区域与局部对齐的mesh之间的最终误差。

通过本文提出的评价流程,我们能够建立语义信息更一致的对应关系,从而提升最终评价结果的可靠性。直观而言,如图所示,对于ground-truth scan嘴部区域的关键点,我们分别比较了predicted mesh使用先前的对齐方法(gICP),以及本文提出的基于区域的对齐方法(rICP)以及基于形变的关键点更新策略(bICP)在ground-truth scan上找到的对应点与真实的嘴部关键点的差异,可以发现,我们的方法建立的关键点与真实的关键点更加接近,因此这时的误差最能体现真实的相似性。

五、新的人脸3DMM:HIFI3D++
在构建benchmark的过程中,我们对于一些高质量的人脸数据(Headspace, FaceScape, HIFI3D)进行了拓扑结构的统一,得到了约2000个不同性别、年龄、种族的人脸mesh,在此基础上,我们构建了一个全头人脸3DMM并命名为HIFI3D++,不仅包含脸部区域,还包含脖子、眼球、口腔,不同拓扑结构的比较如图1所示。

表1统计了开源的3DMM与HIFI3D++的基本信息,图9则显示了不同3DMM的variation,我们的RGB(-D) Fitting实验也证明了HIFI3D++在表达能力上优于先前的3DMM。


六、实验
1. 评价方案有效性的证明
我们首先在toy数据上证明我们的评价流程相较于先前的方法的优越性。通过替换一组统一拓扑人脸的不同区域,采用不同的评价流程进行对齐和对应关系的建立,比较了不同评价流程 i) 由于对齐导致的误差以及 ii) 建立的对应点与ground-truth真实对应点之间的误差,结果如图4和表2、3所示。


从图4来看,全局的对齐策略(右图)由于局部区域的改变容易导致全局误差的变化,而我们的对齐策略则只聚焦于特定区域(右图),其中对角线的error map表明误差较大的区域,而非对角线的error map的误差较小,对应没有发生变化的区域。
从表2来看,我们的对齐结果通过ground-truth的对应点计算得到的误差与真实的误差更为接近,而全局的对齐策略则导致误差与真实误差不匹配。
从表3来看,我们的对应点计算策略带来的误差要显著小于全局对齐后最近点获得的对应点。实验结果表明,我们的评价流程不仅能够聚焦到脸部区域有差异的部分(图4和表2的对角线),并且我们的对应关系建立更加准确(表3)。
2. 不同方法在REALY benchmark上的表现
我们对比了先前的评价流程与我们提出的评价流程在REALY benchmark上的表现。对于先前的评价方法,我们从两个方向(即ground-truth scan的每个点与predicted mesh建立对应关系,以及predicted mesh每个点与ground-truth scan建立对应关系)作为对比,定量与定性的比较如表4和图5所示。


我们通过user study投票选出各组最好(*)/次好(†)的人脸,通过比较不同评价流程选出的最好的人脸(橙、蓝、紫框)可以发现,我们的评价流程(橙框)选出的最好的人脸与user study的投票结果匹配程度更高。并且,我们的评价流程给出了细粒度的评测结果,即:对不同的人脸区域都能进行定量的评价和比较。
3. 不同3DMM在REALY上的表现
借助REALY benchmark,本文采用RGB(-D) Fitting的方式对不同3DMM的表达能力进行了评价,定量与定性的比较如表5和图8所示。


定量和定性的结果表明,我们的3DMM在REALY上取得了更优的重建效果,并且,通过不同方法的比较表明,RGB-D Fitting的结果要显著优于目前最好的重建算法,3D人脸重建任务仍有很大的提升空间。
为了进一步证明HIFI3D++的表达能力,我们只用顶点损失,根据最小二乘的方式拟合一组mesh,对HIFI3D/HIFI3D(A)/HIFI3D++进行比较,如图9所示。

七、总结
本文是我们对3D人脸重建评价的重新思考和探索。针对先前的评价指标无法准确衡量重建mesh与ground-truth相似性的问题,我们构建了一个新的数据集——REALY,包含更加丰富以及高质量的脸部区域信息,并借助新的评价流程对先前的数十个重建算法、3DMM进行了评价。
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
计算机视觉工坊精品课程官网:3dcver.com
1.面向自动驾驶领域的多传感器数据融合技术
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
9.从零搭建一套结构光3D重建系统[理论+源码+实践]
10.单目深度估计方法:算法梳理与代码实现
11.自动驾驶中的深度学习模型部署实战
12.相机模型与标定(单目+双目+鱼眼)
13.重磅!四旋翼飞行器:算法与实战
14.ROS2从入门到精通:理论与实战
15.国内首个3D缺陷检测教程:理论、源码与实战
16.基于Open3D的点云处理入门与实战教程
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~