tensorflow实现猫狗分类器(二)数据增强版
在上文我们训练了一个猫狗分类器,虽然训练集的表现很好但是验证集却还不够,并且有明显的过拟合现象。为了克服过拟合通常需要扩大数据集,但是往往并没有足够的数据用来训练,所以我们采用数据增强的方式扩大训练规模。
我们利用ImageGenerator来实现数据增强
train_datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
- rotation_range is a value in degrees (0–180), a range within which to
randomly rotate pictures.
旋转范围是以度(0–180)为单位的值,在该范围内可以随机旋转图片。 - width_shift and height_shift are ranges (as a fraction of total width
or height) within which to randomly translate pictures vertically
or horizontally.
宽度偏移和高度偏移是垂直或水平随机转换图片的范围(作为总宽度或高度的分数)。 - shear_range is for randomly applying shearing transformations.
剪切范围用于随机应用剪切变换。 - zoom_range is for randomly zooming inside pictures.
缩放范围用于随机缩放内部图片。 - horizontal_flip is for randomly flipping half of the images
horizontally. This is relevant when there are no assumptions of
horizontal assymmetry (e.g. real-world pictures).
水平翻转用于随机水平翻转一半图像 - fill_mode is the strategy used for filling in newly created pixels,
which can appear after a rotation or a width/height shift.
填充模式是用于填充新创建像素的策略,可在旋转或宽度/高度移动后显示。
比如我们的数据集有如下左图所示的举起右手的动作但没有右图举起左手的:
 我们可以通过水平翻转得到类似右图的动作
我们可以通过水平翻转得到类似右图的动作

完成代码编写如下:
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip \
-O /tmp/cats_and_dogs_filtered.zip
import os
import zipfile
import tensorflow as tf
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
local_zip = '/tmp/cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()
base_dir = '/tmp/cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# Directory with our training cat pictures
train_cats_dir = os.path.join(train_dir, 'cats')
# Directory with our training dog pictures
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with our validation cat pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
# Directory with our validation dog pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=1e-4),
metrics=['acc'])
# This code has changed. Now instead of the ImageGenerator just rescaling
# the image, we also rotate and do other operations
# Updated to do image augmentation
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1./255)
# Flow training images in batches of 20 using train_datagen generator
train_generator = train_datagen.flow_from_directory(
train_dir, # This is the source directory for training images
target_size=(150, 150), # All images will be resized to 150x150
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
# Flow validation images in batches of 20 using test_datagen generator
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100, # 2000 images = batch_size * steps
epochs=100,
validation_data=validation_generator,
validation_steps=50, # 1000 images = batch_size * steps
verbose=2)

这次我们扩大了epoch到100,在前几个epoch我们可以看到数据的准确率不如我们之前的没有增强过的是因为在处理图像转换,平移,压缩等操作。但是随着迭代轮数的增加我们的准确率不断上升,我们的损失也在下降。并且观察验证集上的准确率我们可以看到没有了上次的情况。为了清晰下面绘制相应的图展示
acc = history.history['acc' ]
val_acc = history.history[ 'val_acc' ]
loss = history.history['loss' ]
val_loss = history.history['val_loss' ]
epochs = range(len(acc)) # Get number of epochs
# Plot training and validation accuracy per epoch
plt.plot ( epochs, acc )
plt.plot ( epochs, val_acc )
plt.title ('Training and validation accuracy')
plt.figure()
# Plot training and validation loss per epoch
plt.plot ( epochs, loss )
plt.plot ( epochs, val_loss )
plt.title ('Training and validation loss' )
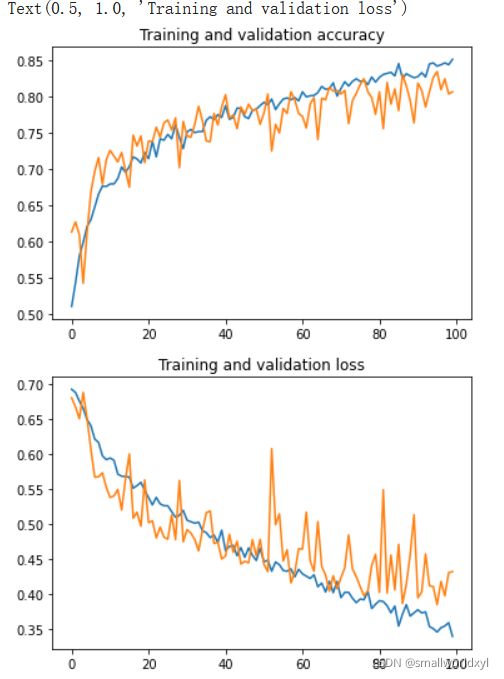
从图像可以看出之前的过拟合现象得到了有效的缓解,验证集和训练集的准确率同步上升。损失也在下降。虽然训练集最终的准确率不如上次没有添加数据增强的,但是随着迭代次数增加,这个准确率是在不断提高的,所以可以通过提高迭代次数来达到更高的acc。
但是如果只对训练集进行数据增强,对验证集不进行,就会出现类似下面这种情况
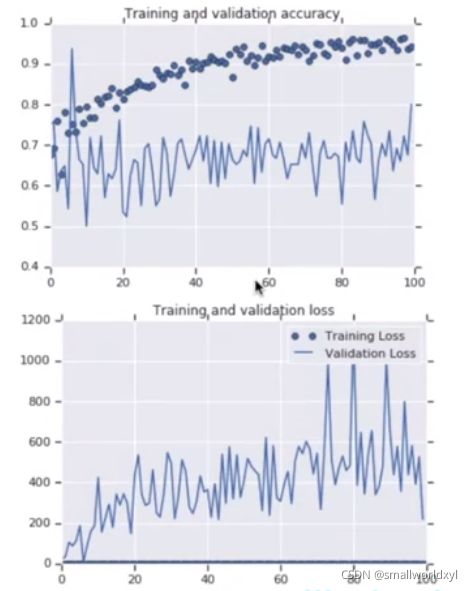
数据增强引入了随机性,但如果验证集没用相同的随机性就会出现如上图所示的波动。大规模数据可以帮助你更好的完成训练,但是你的测试也需要大规模数据。所以数据增强只能帮助你训练,并不能对你的测试起到更多的帮助作用。所以获取更多的数据总是更有帮助。