基于TensorFlow和Keras的卷积神经网络实现猫狗数据集分类实验
目录
- 一、基础模型建立
- 二、根据基准模型进行调整
- 三、卷积神经网络的可视化
环境:anaconda3
详细安装配置:
https://blog.csdn.net/cungudafa/article/details/104573389
一、基础模型建立
1、制作数据集
首先需要原始数据
百度网盘
链接:https://pan.baidu.com/s/1Cahz_6zOlX2voH0TaATLiw
提取码:2dgw
![]()
解压在合适的地方
打开解压文件原始目录如下,再将两个压缩包解压在当前目录
打开Jupyter Notebook
2、图片分类
下面original_dataset_dir为原始数据练习集路径
base_dir是代码执行后生成的分类文件夹
注:执行成功不会有反馈,可以自行查看文件夹
import os, shutil
# The path to the directory where the original
# dataset was uncompressed
original_dataset_dir = 'F:/data_cat&dog/kaggle_Dog&Cat/train'
# The directory where we will
# store our smaller dataset
base_dir = 'F:/data_cat&dog/kaggle_Dog&Cat/find_cats_and_dogs'
os.mkdir(base_dir)
# Directories for our training,
# validation and test splits
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# Directory with our training cat pictures
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# Directory with our training dog pictures
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# Directory with our validation cat pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# Directory with our validation dog pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
# Directory with our validation cat pictures
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
# Directory with our validation dog pictures
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# Copy first 1000 cat images to train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 cat images to validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 cat images to test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# Copy first 1000 dog images to train_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 dog images to validation_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# Copy next 500 dog images to test_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
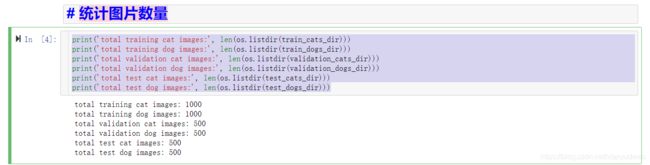
3、统计图片数量
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))
4、定义模型
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()
5、图像生成器读取文件中数据
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(learning_rate=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255) #之后可能会在这里进行图像增强
test_datagen = ImageDataGenerator(rescale=1./255) #注意验证集不可用图像增强
batch_size = 20
train_dir = r'F:\data_cat&dog\kaggle_Dog&Cat\find_cats_and_dogs\train'
validation_dir = r'F:\data_cat&dog\kaggle_Dog&Cat\find_cats_and_dogs\validation'
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150,150),
batch_size=batch_size,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size=batch_size,
class_mode='binary')

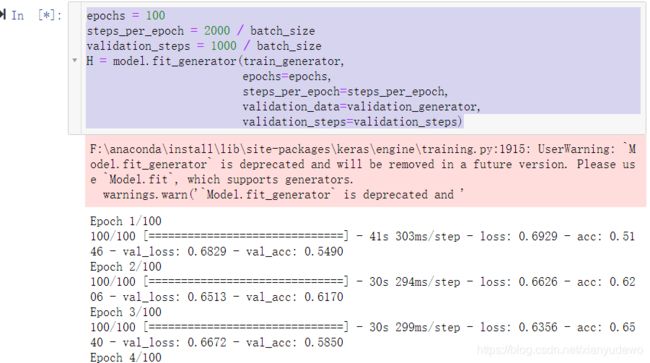
6、开始训练
epochs = 100
steps_per_epoch = 2000 / batch_size
validation_steps = 1000 / batch_size
H = model.fit_generator(train_generator,
epochs=epochs,
steps_per_epoch=steps_per_epoch,
validation_data=validation_generator,
validation_steps=validation_steps)
7、保存模型
model.save('cats_and_dogs_small_1.h5')
print("The trained model has been saved.")

8、模型评估
test_dir = r'F:\data_cat&dog\kaggle_Dog&Cat\find_cats_and_dogs\test'
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=(150,150), batch_size=20, class_mode='binary')
score = model.evaluate(test_generator, steps=50)
print("测试损失为:{:.4f}".format(score[0]))
print("测试准确率为:{:.4f}".format(score[1]))
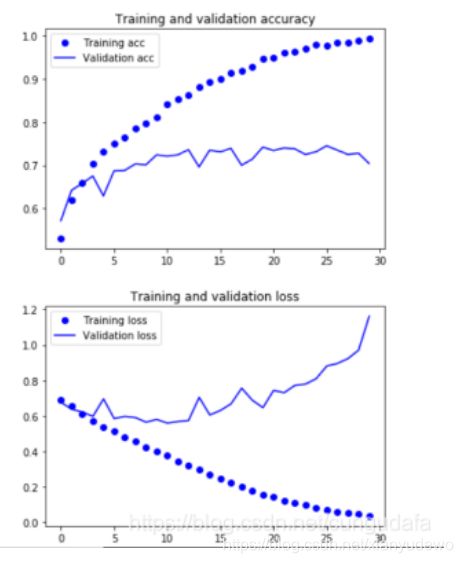
9、结果可视化
import matplotlib.pyplot as plt
loss = H.history['loss']
acc = H.history['acc']
val_loss = H.history['val_loss']
val_acc = H.history['val_acc']
epoch = range(1, len(loss)+1)
fig, ax = plt.subplots(1, 2, figsize=(10,4))
ax[0].plot(epoch, loss, label='Train loss')
ax[0].plot(epoch, val_loss, label='Validation loss')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss')
ax[0].legend()
ax[1].plot(epoch, acc, label='Train acc')
ax[1].plot(epoch, val_acc, label='Validation acc')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Accuracy')
ax[1].legend()
plt.show()
二、根据基准模型进行调整
为了解决过拟合问题,可以减小模型复杂度,也可以用一系列手段去对冲,比如增加数据(图像增强、人工合成或者多搜集真实数据)、L1/L2正则化、dropout正则化等。这里主要介绍CV中最常用的图像增强。
1、图像增强方法
在Keras中,可以利用图像生成器很方便地定义一些常见的图像变换。将变换后的图像送入训练之前,可以按变换方法逐个看看变换的效果。代码如下:
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# This is module with image preprocessing utilities
from keras.preprocessing import image
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
# We pick one image to "augment"
img_path = fnames[3]
# Read the image and resize it
img = image.load_img(img_path, target_size=(150, 150))
# Convert it to a Numpy array with shape (150, 150, 3)
x = image.img_to_array(img)
# Reshape it to (1, 150, 150, 3)
x = x.reshape((1,) + x.shape)
# The .flow() command below generates batches of randomly transformed images.
# It will loop indefinitely, so we need to `break` the loop at some point!
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
2、模型调整
图像增强
#######################查看数据增强效果#########################
from keras.preprocessing import image
import numpy as np
#定义一个图像生成器
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
#生成所有猫图的路径列表
train_cats_dir = os.path.join(train_dir, 'cats')
fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]
#选一张图片,包装成(batches, 150, 150, 3)格式
img_path = fnames[1]
img = image.load_img(img_path, target_size=(150,150)) #读入一张图像
x_aug = image.img_to_array(img) #将图像格式转为array格式
x_aug = np.expand_dims(x_aug, axis=0) #(1, 150, 150, 3) array格式
#对选定的图片进行增强,并查看效果
fig = plt.figure(figsize=(8,8))
k = 1
for batch in datagen.flow(x_aug, batch_size=1): #注意生成器的使用方式
ax = fig.add_subplot(3, 3, k)
ax.imshow(image.array_to_img(batch[0])) #当x_aug中样本个数只有一个时,即便batch_size=4,也只能获得一个样本,所以batch[1]会出错
k += 1
if k > 9:
break
plt.show()
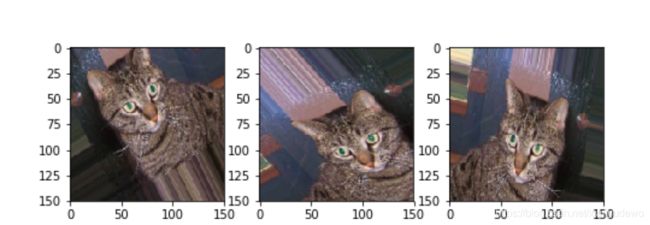
三、卷积神经网络的可视化
1、导入训练模型,查看模型参数
from keras.models import load_model
model = load_model('cats_and_dogs_small_1.h5')
model.summary() # As a reminder.
2、模型预处理
img_path = 'D:/python_project/kaggle_Dog&Cat/find_cats_and_dogs/test/cats/cat.1502.jpg'
# We preprocess the image into a 4D tensor
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path, target_size=(150, 150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor, axis=0)
# Remember that the model was trained on inputs
# that were preprocessed in the following way:
img_tensor /= 255.
# Its shape is (1, 150, 150, 3)
print(img_tensor.shape)
3、输入一张猫的图像
import matplotlib.pyplot as plt
plt.imshow(img_tensor[0])
plt.show()

。。。
参考:
https://blog.csdn.net/cungudafa/article/details/104573389
https://www.cnblogs.com/inchbyinch/p/11971358.html