《scikit-learn》随机森林之分类预测乳腺癌模型
今天我们使用随机森林分类器来对乳腺癌数据进行预测
第一步:加载数据
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer # 乳腺癌数据
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV, cross_val_score # 网格搜索,和交叉验证指标
# 加载乳腺癌数据,569个样本数据,30个属性特征,维度不高,数据样本也少。
breast_cancer = load_breast_cancer()
print(breast_cancer.data.shape)
print(breast_cancer.feature_names)
print(breast_cancer.target.shape)
print(breast_cancer.target_names) # [“恶性”, “良性”]
# print(breast_cancer.keys())
第二步:简单试验一个随机森林的分类器的表现
# === 1: 单个随机森林的分类试验
rfc = RandomForestClassifier(n_estimators=100, random_state=100) # 实例化
score = cross_val_score(rfc, breast_cancer.data, breast_cancer.target, cv=10, scoring='accuracy')
print("单个测试随机森林分类器的结果是:", score.mean())
第三步:利用学习曲线来调整调整一些参数,这里我只调整了n_estimators
使用交叉验证。
# === 2: 使用学习曲线,来看看某些参数的影响,可以更能让我们看到参数的影响趋势。可以让我们大致能锁定该参数最合适的取值范围。
scores = []
for i in range(1, 201, 10):
rfc = RandomForestClassifier(n_estimators=i, random_state=100, n_jobs=-1)
score = cross_val_score(rfc, breast_cancer.data, breast_cancer.target, cv=10, scoring='accuracy').mean()
scores.append(score)
print("最大的值是:{}, n_estimators的取值是{}.".format(max(scores), scores.index(max(scores)) * 10 + 1))
plt.figure(figsize=[10, 5])
plt.plot(range(1, 201, 10), scores)
plt.title("n_estimators")
plt.legend()
plt.show()
得到大致的图像如下:
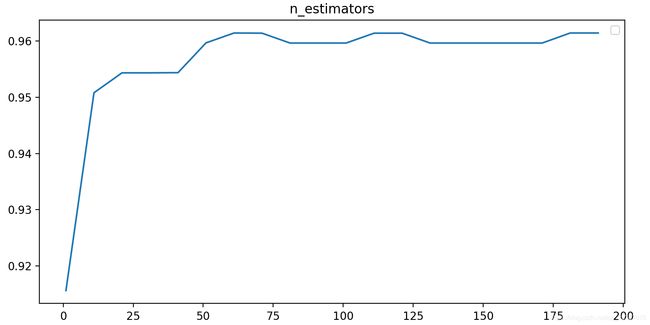
发现在50~70之间存在峰值,那么进一步利用学习曲线,缩小范围来整。
# 经过学习曲线能够观察到,n_estimators 在50~60以后就趋于平稳了。在此处的地方可以达到最大
# 那么而下一步,我们继续细微调节,在最大值附近应该是存在某个很好的值
scores = []
for i in range(40, 70, 2):
rfc = RandomForestClassifier(n_estimators=i, random_state=100, n_jobs=-1)
score = cross_val_score(rfc, breast_cancer.data, breast_cancer.target, cv=10, scoring='accuracy').mean()
scores.append(score)
print("最大的值是:{}, n_estimators的取值是{}.".format(max(scores), [*range(40, 70, 2)][scores.index(max(scores))] ))
plt.figure(figsize=[10, 5])
plt.plot(range(40, 70, 2), scores)
plt.title("n_estimators")
plt.legend()
plt.show()
# 前面的学习曲线,就是为给网格搜索做准备的。知道了趋势,方便更小范围定位搜索
曲线如下:
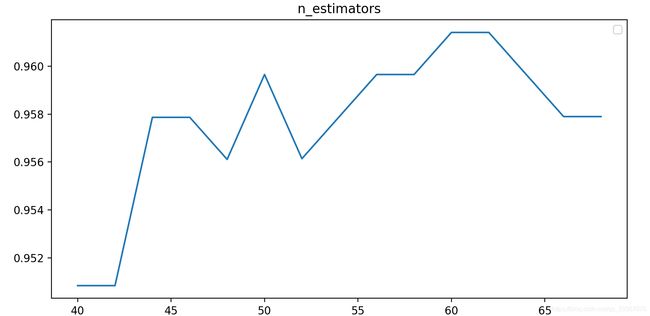
我们把多个参数一起这么试验。得到一些更小的范围
最后我们根据不同的参数的小范围来进行网格搜索,对于范围较大的参数建议一开始使用网格搜索来看趋势,锁定小范围。
# === 3: 使用网格搜索
# 有一些参数,一上来我们根本不知道其范围,范围太大了,适合先用学习曲线来卡哪款趋势。比如n_estimators 和 max_depth 和 max_leaf_nodes
# 有一些参数,可以知道范围的,范围也小,数量少,直接使用网格搜索,比如criterion
clf = RandomForestClassifier(n_estimators=60, random_state=100, n_jobs=-1)
param_grid = [
{'criterion': ['entropy', 'gini'],
'max_features': [*range(10, 30, 2)],
'max_depth': [5, 6, 7, 8, 9, 10],
'min_samples_leaf': [*range(1, 10, 5)],
'min_impurity_decrease': [*np.arange(0.01, 0.1, 0.01)]}, # 一共有 2x11x6x2x11 个超参数组合
]
grid_search = GridSearchCV(clf, param_grid, cv=10, n_jobs=2)
grid_search = grid_search.fit(breast_cancer.data, breast_cancer.target)
print(grid_search.best_params_) # 找到最优的超参数,这里帮我自动选择好了最优的参数列表
print(grid_search.best_estimator_) # 找到最优化的模型,甚至把初始化参数都打印出来了
print(grid_search.best_score_) # 找到最优的结果