决策树(decision tree)——(1)生成与度量指标
**注:本博客为李航《统计学习方法》与周志华《机器学习》读书笔记,虽然有一些自己的理解,但是其中仍然有大量文字摘自李老师和周老师的书籍内容。
决策树(decision tree)是一种基本的分类与回归方法.
本章主要讨论用于分类的决策树.
决策树模型呈树形结构,
分类时,可以认为是定义在特征空间与类空间上的条件概率分布.其主要优点是模型具有可读性,分类速度快。
学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。
预测时,对新的数据,利用决策树模型进行分类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
决策树由Quinlan在1986年提出的ID3算法和1993年提出的C4.5算法。
以及由Breiman等人在1984年提出的CART算法. 决策树(决策树)是一种基本的分类与回归方法。

决策树的生成
决策树学习的算法通常是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程.这一过程对应着对特征空间的划分,也对应着决策树的构建.
开始,构建根结点,将所有训练数据都放在根结点.选择一个最优特征,按照这一特征将训练数据集分割成子集,使得各个子集有一个在当前条件下最好的分类.如果这些子集已经能够被基本正确分类,那么构建叶结点,并将这些子集分到所对应的叶结点中去;
如果还有子集不能被基本正确分类,那么就对这些子集选择新的最优特征,继续对其进行分割,构建相应的结点.如此递归地进行下去,直至所有训练数据子集被基本正确分类,或者没有合适的特征为止.最后每个子集都被分到叶结点上,即都有了明确的类.这就生成了一棵决策树。

特征的选择
特征选择在于选取对训练数据具有分类能力特征。这样可以提高决策树的学习的概率,
如果利用一个特征进行分类的结果与随机分类的结果没有很大差别,则称这个特征是没有分类能力
的.经验上扔掉这样的特征对决策树学习的精度影响不大.通常特征选择的准则是信息增益或信息
增益比、分类误差率、基尼指数。
下面分别介绍
我们举例子进行说明,这样方便大家理解。
例 贷款申请,数据集T
图 1.1

分类误差率
分类误差率是指集合中任一样例被分错类别的概率。它是不纯度最直接的度量方法。
在二分类中,对于任意一个叶子节点t,它预测的类别应该是t中包含样例个树最多的类别。
因为t中所有的样例都被预测为出现概率最大的那个类别,所以t的分类误差率,记为Error(t)
![]()
当t中各所以样例都属于同一类别,即最纯时,Error(t)取最小值0,当t中的各类分布均匀,即各类包含的样例各数相等时,Error(t)取最大值(1-1/n).
例如:
以图1.1为例,以年龄为节点,可以分成三个子集。
年龄这个特征的分类误差率为:
![]()
其子集的分类误差率为:
![]()
![]()
![]()
所以总的分类误差率减少![]()
![]()
同理算出各个特征的分类误差率
进行比较,选择误差率最大的那个,重复以上步骤继续分裂下去。
缺点:
分类误差对分类概率的改变不够敏感,导致生成低效的决策树。
信息增益
熵,它是热力学中的一个概念,用于衡量一个系统的混乱度,一个系统月无序混乱,熵越大。在信息论中,熵是对随机变量不确定性的度量,熵的值越大,随机变量的不确定性就越大,即信息量月大。
设X是一个取有限个值的离散随机变量,其概率分布为
![]()
则随机变量X的熵定义为
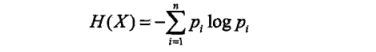
当随机变量只取两个值,例如1,0时,有:
![]()
熵为:
![]()
条件熵H(Y\X)表示在已知随机变量X的条件下随机变量Y的不确定性.随机变量X给定的条件下随机变量Y的条件熵(条件熵)H(Y=X),定义为X给定条件下Y的条件概率分布的熵对的数学期望
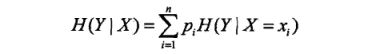
当熵和条件熵中的概率由数据估计(特别是极大似然估计〉得到时,所对应的熵与条件熵分别称为经验熵( empirical entropy)和经验条件熵( empiricalconditional entropy).
此时,如果有0概率,令0log0=0 .
信息增益(information gain)表示得知特征X的信息而使得类Y的信息的不确定性减少的程度.
信息增益:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验嫡H(D)与特征A给定条件下D的经验条件熵H(D=A)之差,即
![]()
一般地,熵H(Y)与条件熵H(Y=X)之差称为互信息(mutual information)决策树学习中的信息增益等价于训练数据集中类与特征的互信息.
例如:
以图1.1为例,以年龄为节点,可以分成三个子集。
年龄的熵为:
![]()
其子集的经验熵为:
![]()
![]()
则分裂后熵减少了,即年龄的信息增益为:
![]()
计算出其他特征的熵,选择最大的互信息
信息增益值的大小是相对于训练数据集而言的,并没有绝对意义.在分类问题困难时,也就是说在训练数据集的经验嫡大的时候,信息增益值会偏大.反之,信息增益值会偏小.使用信息增益比( information gain ratio)可以对这一问题进行校正.这是特征选择的另--准则.
信息增益率
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种偏好可能带来的不利影响,著名的C4.5决策树算法[Quinlan,1993]不直接使用信息增益,而是使用“增益率”(gain ratio)来选择最优划分属性,信息增益率定义为

称为属性α的“固有值”(intrinsic value)[Quinlan,1993].属性α的可能取值数目越多(即V越大),则IV(a)的值通常会越大.IV(a)称为内部信息。
例如:
以图1.1为例,以年龄为节点,可以分成三个子集。
年龄的熵为:
![]()
其子集的分类误差率为:
![]()
![]()
则分裂后熵减少了,即年龄的信息增益为:
![]()
![]()
![]()
需注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式[Quinlan,1993]:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的.
基尼指数
基尼指数是0~1之间的一个比值,其值月大,表示不平等程度越高,衡量一个节点的不纯度。
CART决策树[Breiman et al.,1984]使用“基尼指数”(Gini index)来选择划分属性。定义数据集D,数据集D的纯度可用基尼值来度量:
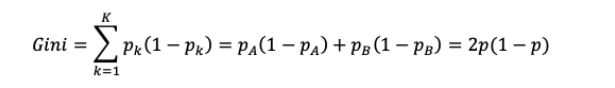
直观来说,定义数据集D,则Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率.因此, Gini(D)越小,则数据集D的纯度越高。
例如:
以图1.1为例,以年龄为节点,可以分成三个子集。
数据集的T的基尼指数:
![]()
分裂后得到,D1,D2,D3
![]()
![]()
![]()
则分裂后基尼指数减少了:
![]()
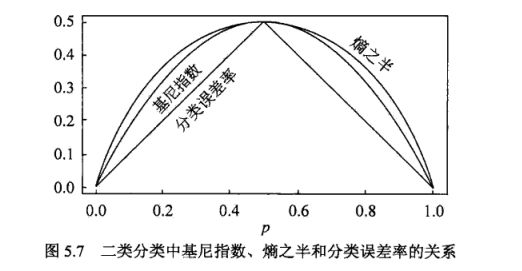
二类分类中基尼指数、嫡之半和分类误差率的关系
以二分类为例,显示二类分类问题中基尼指数Gini(p)、熵(单位比特)之半H(p)和分类误差率的关系.横坐标表示概率p,纵坐标表示损失.可以看出基尼指数和熵之半的曲线很接近,都可以近似地代表分类误差率.
python进行实现:
import numpy as np
from matplotlib import pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['simHei']
mpl.rcParams['axes.unicode_minus'] = False
p = np.linspace(0.0001, 0.9999 ,50)
Gini = 2 * p * (1-p)
H = (-p * np.log2(p) - (1 - p) * np.log2(1 - p))/2.0
x1 = np.linspace(0,0.5,50)
y1 = x1
x2 = np.linspace(0.5,1,50)
y2 = 1- x2
plt.figure(figsize=(10,5))
plt.plot(p, Gini, 'r-', label='基尼指数')
plt.plot(p, H, 'b-', label='半熵')
plt.plot(x1, y1, 'g-', label='分类误差率')
plt.plot(x2, y2, 'g-')
plt.legend()
plt.xlim(-0.01, 1.01)
plt.ylim(0, 0.51)
plt.show()下一篇介绍几种算法:
关注我文章。
参考:李航《统计统计学习方法》
参考:周志华《机器学习》