无监督学习(2) 数据降维简述与Python实现
为什么要数据降维
大数据时代面临的最大问题是"维度灾难",度量上的不平衡和高维空间的学习复杂度都让机器学习算法在高维数据上很多时候行不通。而且,如果数据超过三维,它们也很难被可视化。不能被可视化的数据是很难理解的。
如果我们的数据比较高维,不适合直接进行监督或聚类学习,则我们可以先用一些其他的无监督或有监督的技巧把数据进行降维。这一系列的方法也常常被叫做度量学习。
通过有监督或者无监督的方法,学习在原始的坐标距之上的距离评估方法,就是度量学习。度量学习可以为KNN和聚类服务,有时这些方法也可以被直接用在数据预处理上,而且一般表现都不错。我们首先介绍的是PCA,主成分分析;
PCA
PCA使用一个线性变换投影来得到新的坐标空间,也就是把原向量空间里的数据x乘上一个W矩阵,变换到另一个向量空间。PCA的目的就是确定W应该是怎样的W;考虑我们希望的是让被处理后的数据被分的尽可能开,也就是让投影后的数据点的方差最大化,问题就简化为了最大化协方差矩阵的迹。如果投影后的新向量是
W T x W^Tx WTx
那么协方差矩阵就是
W T ( x − x ^ ) ( x − x ^ ) T W W^T(x-\hat{x})(x-\hat{x})^TW WT(x−x^)(x−x^)TW
因为W^T是投影矩阵,新的坐标基应该满足两两正交条件,还需要有约束条件
W T W = I W^TW = I WTW=I
PCA有意思就有意思在下面的步骤,我们知道如果是约束优化问题,可以用拉格朗日乘子法来解。给上面的约束条件使用拉格朗日乘子法添上一个 λ \lambda λ,就变成
W T ( x − x ^ ) ( x − x ^ ) T W = λ ( W T W − I ) W^T(x-\hat{x})(x-\hat{x})^TW=\lambda (W^TW - I) WT(x−x^)(x−x^)TW=λ(WTW−I)
再计算偏导等于零,原式变为
( x − x ^ ) ( x − x ^ ) T W = λ W (x-\hat{x})(x-\hat{x})^TW=\lambda W (x−x^)(x−x^)TW=λW
这是特征值分解的形式!特征值分解找到的特征值和特征向量对有多个,也就是满足约束条件的解有多个。对W的一个向量w,我们希望最大化的目标函数是
w T ( x − x ^ ) . ( x − x ^ ) T . w = w T w λ = λ w^T(x-\hat{x}).(x-\hat{x})^T.w=w^Tw\lambda=\lambda wT(x−x^).(x−x^)T.w=wTwλ=λ
就等于 λ \lambda λ,最大的 λ \lambda λ对应最好的约束优化问题的解;好了,现在拿到数据,我们把数据做个标准化,让 x ^ \hat x x^=0,然后令S = X T X X^TX XTX,对S做特征值分解,在得到的 λ \lambda λ中选k个最大的对应的特征向量,就得到W矩阵,做W点乘X就能把数据降维到k维。算法就结束啦。下面的代码也可以看到,只需要几行就可以实现。
def PCA(X,dim):
#中心化
xmean = np.mean(X,axis=0)
X=deepcopy(X-xmean)
#协方差矩阵
Covs = X.T.dot(X)
lamda,V=np.linalg.eigh(Covs)
#取前dim个最大的特征值对应的特征向量
index=np.argsort(-lamda)[:dim]
V_selected=V[:,index]
return V_selected
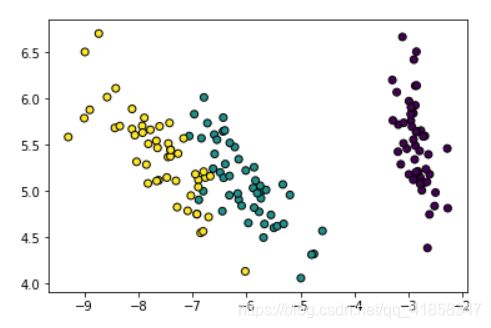
我们可以试试在Iris上的效果
X,y = datasets.load_iris(return_X_y=True)
W = PCA(X,2)
X_ = X.dot(W)
plt.scatter(X_[:,0], X_[:,1],edgecolors='black',c=y)
LDA
PCA并不总能把事情做的很好,因为PCA盲目地把数据映射到了最能"平铺"的空间。如果我们想完成二分类任务,我们的数据集像油条的两根那样平行地排布在一起,而且又被拉长,则PCA只会把油条平放在桌子上,而我们希望油条被竖直地立在桌子上,这样才能更好地区分两个类别。
为此需要引入有标签的线性降维学习方法LDA,其实思想是和PCA完全一致,但现在我们希望最小化类内方差,最大化类间方差。事实上这部分内容在讲线性模型时已经讲过了,我们这里复习一下。
首先定义类间距离和类内距离,类间距就是两个类中心的距离,类内距就是所有数据点到类中心的距离均值
J 0 = ( ( μ 1 − μ 0 ) W ) T ( ( μ 1 − μ 0 ) W ) = W T ( μ 1 − μ 0 ) T ( μ 1 − μ 0 ) W J_0=((\mu_1-\mu_0)W)^T((\mu_1-\mu_0)W)=W^T(\mu_1-\mu_0)^T(\mu_1-\mu_0)W J0=((μ1−μ0)W)T((μ1−μ0)W)=WT(μ1−μ0)T(μ1−μ0)W
J 1 = ( ( X − μ ) W ) T ( ( X − μ ) W ) = W T ( X − μ ) T ( X − μ ) W J_1=((X-\mu)W)^T((X-\mu)W)=W^T(X-\mu)^T(X-\mu)W J1=((X−μ)W)T((X−μ)W)=WT(X−μ)T(X−μ)W
我们设 S 1 = ( X − μ ) T ( X − μ ) , S 0 = ( μ 1 − μ 0 ) T ( μ 1 − μ 0 ) S_1=(X-\mu)^T(X-\mu),S_0 = (\mu_1-\mu_0)^T(\mu_1-\mu_0) S1=(X−μ)T(X−μ),S0=(μ1−μ0)T(μ1−μ0)
有了这两个量就可以自己定义损失函数了,一种能保证数据规模不会影响loss的方法是设J1=1,最大化J0。即 J = W T S 0 W s . t . W T S 1 W = 1 J=W^TS_0W \quad s.t.\quad W^TS_1W=1 J=WTS0Ws.t.WTS1W=1
这个问题直接用拉格朗日乘子法就能求解,写出拉格朗日函数
L ( W , λ ) = W T S 0 W − λ ( W T S 1 W − 1 ) L(W,\lambda)=W^TS_0W-\lambda (W^TS_1W-1) L(W,λ)=WTS0W−λ(WTS1W−1)
计算偏导并让它等于0,就得到极值的必要条件
∂ L ∂ W = 2 W T S 0 W − 2 λ W T S 1 = 0 \frac{\partial{L}} {\partial{W}}=2W^TS_0W-2\lambda W^TS_1=0 ∂W∂L=2WTS0W−2λWTS1=0
S 0 W = λ S 1 W S_0W=\lambda S_1W S0W=λS1W
S 1 − 1 S 0 W = λ W S_1^{-1}S_0W=\lambda W S1−1S0W=λW
即W是最优解时上式一定成立,从上式我们能逐步推导出
S 0 W = λ S 1 W S_0 W = \lambda S_1 W S0W=λS1W
W T S 0 W = λ W T S 1 W = λ = J W^TS_0W = \lambda W^TS_1W = \lambda = J WTS0W=λWTS1W=λ=J
目标函数和 λ \lambda λ相等。我们发现还是类似PCA的特征值分解。因为我们要最大化目标函数,我们取 S 1 − 1 S 0 S_1^{-1}S_0 S1−1S0最大的特征向量,就得到了最优解W。如果我们取前d个最大的特征向量,就能实现从原数据域降维到d维的线性变换矩阵。
def LDA(X,y,dim):
'''
接收数据特征X和标签y,需要X为NxM的二维numpy array
y为数值为0-1的一维numpy array
'''
# 分为正负样本
X_1 = X[np.where(y==1)]
X_0 = X[np.where(y==0)]
# 计算均值
mu1 = np.mean(X_1,axis = 0)
mu0 = np.mean(X_0,axis = 0)
# 类内散度
S1 = (X_1-mu1).T.dot((X_1-mu1))
# 类间散度
S0 = (mu1-mu0).reshape(-1,1).dot((mu1-mu0).reshape(1,-1))
# 特征值分解
S = np.linalg.inv(S1).dot(S0)
S += np.eye(len(S))*0.001
lamda,V=np.linalg.eigh(S)
#取前dim个最大的特征值对应的特征向量
index=np.argsort(-lamda)[:dim]
V_selected=V[:,index]
return V_selected,S0,S1
按照我们上面说的"油条数据集",我们自己定义一个三维的数据集来验证LDA和PCA的区别。
n = 30
X0 = 0.1*np.ones(n)
X1 = X0*2 + 0.2
X0 = np.concatenate((X0+np.random.rand(n),X0+np.random.rand(n)))
X1 = np.concatenate((X1+np.random.rand(n),X1+np.random.rand(n)))
X2_1 = X0[:n] * 0.9 + X1[:n] ** (-0.3) + 0.2
X2_2 = X0[n:] * 0.9 + X1[n:] ** (-0.3) - 0.2
X2 = np.concatenate((X2_1,X2_2))
X = np.concatenate((X0[None],X1[None],X2[None]),axis = 0).T
y = np.concatenate((np.zeros(n),np.ones(n)))
W = PCA(X,2)
X_ = X.dot(W)
plt.scatter(X_[:,0], X_[:,1],edgecolors='black',c=y)
W,S0,S1 = LDA(X,y,2)
X_ = X.dot(W)
plt.scatter(X_[:,0], X_[:,1],edgecolors='black',c=y)
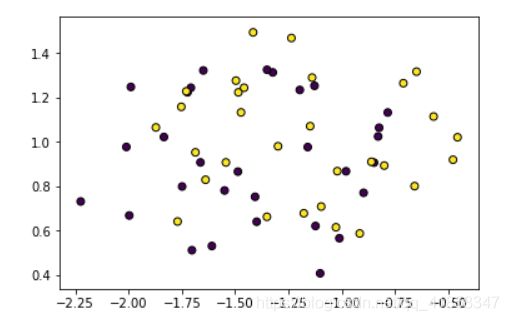
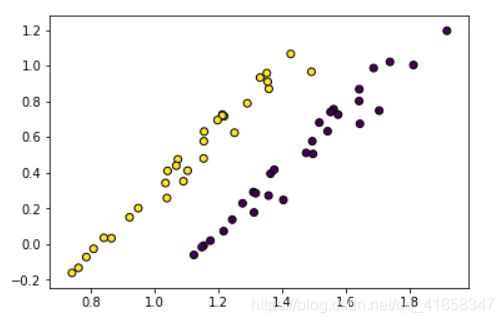
LDA能做到PCA做不到的事情。
Auto Encoder
自编码器是基于PCA和神经网络的思想,我们把PCA的线性变化矩阵和神经网络的非线性激励函数叠起来,就能实现非线性降维任务。自编码器把输入当作神经网络的输出,中间的隐层需要至少一层的神经元个数少于输入层,这样就能在这一层得到神经网络自动降维后的结果。
事实上,今天自编码器担任的不仅仅是降维的角色,相当多的研究者在使用这种模型做更多有意思的事情。比如用特殊结构的AE做字典学习,用变分的AE做生成器等等。这里我们拿pytorch的神经网络模型来实现一个自编码器。
import torch
import torch.nn as nn
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# 压缩
self.encoder = nn.Sequential(
nn.Linear(4,3),
nn.Tanh(),
nn.Linear(3,2),
nn.Tanh(),
)
# 解压
self.decoder = nn.Sequential(
nn.Linear(2,3),
nn.Tanh(),
nn.Linear(3,4)
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
autoencoder = AutoEncoder()
from torch.utils.data import DataLoader,TensorDataset
X,y = datasets.load_iris(return_X_y=True)
X_train = torch.Tensor(X)
y_train = torch.Tensor(y)
myset = TensorDataset(X_train,y_train)
myloader = DataLoader(dataset=myset, batch_size=10, shuffle=True)
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=0.002)
loss_func = nn.MSELoss()
for epoch in range(1000):
Loss = 0
for step, (X_, y_) in enumerate(myloader):
encoded, decoded = autoencoder(X_)
loss = loss_func(decoded, X_)
optimizer.zero_grad()
loss.backward()
Loss += loss.item()
optimizer.step()
Loss /= (step+1)
if (epoch+1)%100==0:
print("epoch %d, loss %.2f"%(epoch+1,Loss))
epoch 100, loss 0.44
epoch 200, loss 0.14
epoch 300, loss 0.11
epoch 400, loss 0.10
epoch 500, loss 0.09
epoch 600, loss 0.09
epoch 700, loss 0.04
epoch 800, loss 0.04
epoch 900, loss 0.03
epoch 1000, loss 0.03
# 看一看结果如何
X_red,_ = autoencoder(X_train)
X_red = X_red.detach().numpy()
plt.scatter(X_red[:,0], X_red[:,1],edgecolors='black',c=y)
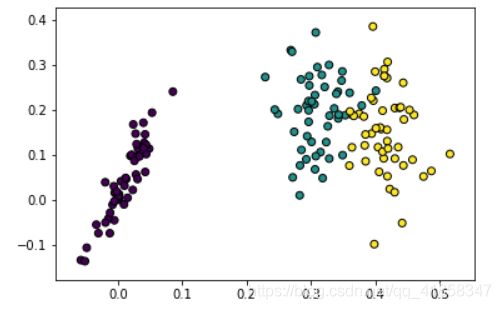
如果不设置激活函数,只设置两个线性变化矩阵的话,会发现得到的结果实际上和PCA得到的结果非常类似。PCA比起单隐层线性自编码器,只是多了一个正交的限制条件,而且输入的线性变化矩阵和输出的矩阵互为转置。这也就决定了线性自编码器得到的结果会和PCA很相似,但是并不会比PCA更好。
更好的降维算法
上面的算法是比较快速,比较简单的降维算法。但是在实际使用时,我们经常发现,因为LDA和PCA不能实现非线性降维,它们在实际场景中不总能取得好的效果。而AE虽然能实现非线性,但它需要一段可能不短的训练时间开销,而且它给出的解并不稳定(会根据初始化的值变化)。我们也许需要更好的,既能实现非线性,又能学习流形,还能保证运行速度的算法。
LLE
首先讲一下基于线性近邻的降维学习方法,这个方法叫Locally Linear的Embeddding。虽然它的名字是linear,但其实实现的是非线性的降维。为什么叫Locally Linear呢?这个名字就是算法的精髓,我们对原数据降维后,保有的是样本点和它附近的k个样本点的固有线性关系。如果原空间的x0附近的3近邻是x1,x2,x3,而且原空间中有x0 = 0.5x1+0.25x2+0.25x3的线性关系,那么我们希望降维后,这个关系仍然存在。
那么,算法最首要的任务就是求解每个数据点的k近邻,并计算上面的线性组合权重向量w。事实上,k近邻的线性组合并不保证能完全等于数据点x,所以我们实质上要解的是一个优化问题。写出优化问题,如下式(x默认为行向量)
m i n i m i z e ∑ i = 1 M ∣ ∣ x i − ∑ j ∈ Q i w i j x j ∣ ∣ 2 minimize \qquad \sum_{i=1}^M ||x_i-\sum_{j\in Q_i}w_{ij}x_j||^2 minimizei=1∑M∣∣xi−j∈Qi∑wijxj∣∣2
如果我们把所有k近邻的xj行向量在列方向上排列成矩阵,wi是样本点xi对于的权重向量,则上式有矩阵代数形式
m i n i m i z e ∑ i = 1 M ∣ ∣ x i − w i X Q i ∣ ∣ 2 minimize \qquad \sum_{i=1}^M ||x_i-w_i X_{Q_i}||^2 minimizei=1∑M∣∣xi−wiXQi∣∣2
求和号中的每项都是独立的优化问题,我们对其中任意i的一项求偏导为0
( w i X Q i − x i ) X Q i T = 0 (w_i X_{Q_i}-x_i)X_{Q_i}^T = 0 (wiXQi−xi)XQiT=0
w i = x i X Q i T ( X Q i X Q i T ) − 1 w_i = x_i X_{Q_i}^T(X_{Q_i}X_{Q_i}^T)^{-1} wi=xiXQiT(XQiXQiT)−1
按照上式可以解出所有的 w i j w_{ij} wij(不属于k近邻的 j j j权重 w i j w_{ij} wij就设为0),然后我们的问题就变成了从W矩阵重构一个低维的数据集矩阵Z,其中 z i z_{i} zi是Z矩阵的第i行,表示原数据点 x i x_i xi降维后的结果。我们的设降维后的Z高为n,宽为d,即降维的目标维度。优化问题和上面的形式实质上是类似的,不过我们现在希望求解Z
m i n i m i z e ∑ i = 1 M ∣ ∣ z i − w i Z ∣ ∣ 2 minimize \qquad \sum_{i=1}^M ||z_i-w_i Z||^2 minimizei=1∑M∣∣zi−wiZ∣∣2
同样可以写成更代数的形式
m i n i m i z e t r [ ( Z − W Z ) T ( Z − W Z ) ] = t r [ Z T ( I − W ) T ( I − W ) Z ] minimize \qquad tr[(Z- WZ)^T(Z- WZ)] = tr[Z^T(I- W)^T(I- W)Z] minimizetr[(Z−WZ)T(Z−WZ)]=tr[ZT(I−W)T(I−W)Z]
如果不加约束,上式解出来的Z只会非常非常小,甚至等于0.为了得到有效的解我们还要加一些约束
s . t . Z T Z = I s.t.\qquad Z^TZ = I s.t.ZTZ=I
然后这个形式就和PCA类似了,我们对 M = ( I − W ) T ( I − W ) M=(I- W)^T(I- W) M=(I−W)T(I−W)做特征值分解,并取最小的特征值,就得到了Z,降维后的数据。
L ( Z ) = t r [ Z T M Z ] − λ ( Z T Z − I ) L(Z) = tr[Z^TMZ]-\lambda (Z^TZ - I) L(Z)=tr[ZTMZ]−λ(ZTZ−I)
∂ L ∂ Z = M Z − λ Z = 0 \frac{\partial{L}}{\partial{Z}} = MZ-\lambda Z = 0 ∂Z∂L=MZ−λZ=0
M z i = λ z i M z_i = \lambda z_i Mzi=λzi
又是特征值分解,特征值分解无处不在。
def dist(x1,x2):
'''
x1,x2: numpy array, shape1 = (m,), shape2 = (m,)
表示维度都为m的两个向量
return: D,int, 表示数据点差异的L2范数
'''
return np.sum((x1-x2)**2)
def LLE(X, k, d):
'''
X: numpy array, shape = (n,m),表示n个m维的数据点组成的数据集
k: LLE使用k近邻,不得大于n-1
d: 目标降维维度,小于m大于0
return: Z,numpy array, shape = (n,d),表示n个d维的数据点组成的数据集
'''
n,m = X.shape
D = np.zeros((n,n))
for i in range(n):
for j in range(n):
D[i][j] = dist(X[i],X[j]) #得到L2的距离矩阵
knn = []
for i in range(n):
knn.append(np.argsort(D[i])[1:k+1]) #得到每个点的k近邻
W = np.zeros((n,n))
for i in range(n):
XQ = X[knn[i]] # K近邻矩阵
A = XQ.dot(XQ.T)
A+=np.eye(k)*1e-3*np.trace(XQ) #magic,保证正定
W[i][knn[i]] = X[i].dot(XQ.T).dot(np.linalg.pinv(A))
# 得到局部线性嵌入权重矩阵
M = (np.eye(n)-W).T.dot((np.eye(n)-W)) # 计算M矩阵
lamda,V=np.linalg.eigh(M)
# 取前dim个最小的特征值对应的特征向量
index=np.argsort(lamda)[:d]
V_selected=V[:,index]
return V_selected
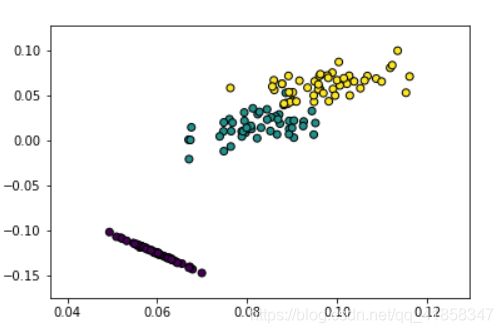
我们在Iris和瑞士卷数据上测试这个算法。
X,y = datasets.load_iris(return_X_y=True)
Z = LLE(X,25,2)
plt.scatter(Z[:,0], Z[:,1],edgecolors='black',c=y)
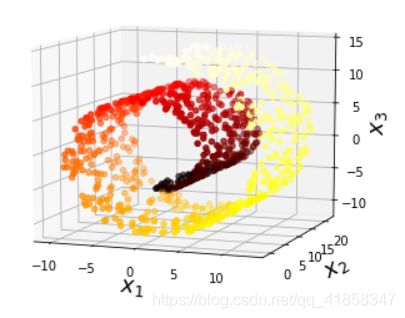
import matplotlib as mpl
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import proj3d
#Generate mainfold data set
from sklearn.datasets import make_swiss_roll
X, t = make_swiss_roll(n_samples=1000, noise=0, random_state=0)
axes = [-11.5, 14, -2, 23, -12, 15]
#plot figure
fig = plt.figure(figsize=(6, 5))
plt.title("old_data", fontsize=14)
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=t, cmap=plt.cm.hot)
ax.view_init(10, -70)
ax.set_xlabel("$x_1$", fontsize=18)
ax.set_ylabel("$x_2$", fontsize=18)
ax.set_zlabel("$x_3$", fontsize=18)
ax.set_xlim(axes[0:2])
ax.set_ylim(axes[2:4])
ax.set_zlim(axes[4:6])
plt.show()
Z = LLE(X,k=6,d=2)
plt.scatter(Z[:, 0], Z[:, 1], c=t, cmap=plt.cm.hot)
plt.show()
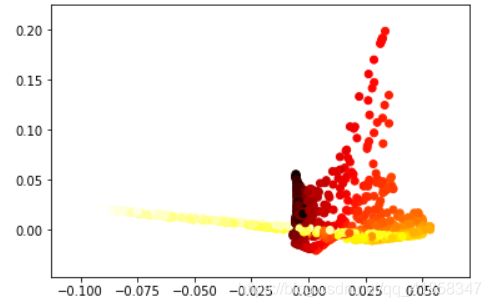
LLE对参数非常敏感,在使用时要进行细致的调参。
Isomap
上面的LLE算法,劣势在于我们用于重建Z的W矩阵,只包含近邻点的信息;很直觉地可以想到,如果上级算法不提供给我们它与其他非近邻点的关系信息,算法很显然不能稳定地给出近邻的点仍然近邻,远离的点仍然远离的结果。
以上面的流形问题为例,我们在这种模型中希望用测地线距离替换原空间的欧拉距离。修过图论或者数据结构的都知道,如果我们把数据点看做图中的顶点,则我们是有比较高效的算法计算任意两点间在图中的最短距离的(Floyd or dijkstra)。这样我们就得到了一种能近似测地线距离的新距离矩阵。这个矩阵提供了哪些点离得近,哪些点离得远的全部信息。
MDS
从距离矩阵重构数据点信息需要MDS算法。首先我们认为这个距离矩阵在重构后的空间Z中表现出的是两点间的欧拉距离,如果我们设 b i j = z i T z j b_{ij} = z_i^Tz_j bij=ziTzj,限制Z,认为Z的均值为0。就有 d i s t i j 2 = ∣ ∣ z i ∣ ∣ 2 + ∣ ∣ z j ∣ ∣ 2 − 2 z i T z j = b i i + b j j − 2 b i j dist_{ij}^2 = ||z_i||^2+||z_j||^2-2z_i^Tz_j = b_{ii}+b_{jj}-2b_{ij} distij2=∣∣zi∣∣2+∣∣zj∣∣2−2ziTzj=bii+bjj−2bij且 ∑ i = 1 n b i j = ∑ j = 1 n b i j = 0 \sum_{i=1}^n b_{ij} = \sum_{j=1}^n b_{ij} = 0 ∑i=1nbij=∑j=1nbij=0。则如果对上面的式子做类似"边缘积分"的运算,能得到一些有用的结论。
∑ i = 1 n d i s t i j 2 = t r ( B ) + n b j j \sum_{i=1}^ndist_{ij}^2 = tr(B)+nb_{jj} i=1∑ndistij2=tr(B)+nbjj
∑ j = 1 n d i s t i j 2 = t r ( B ) + n b i i \sum_{j=1}^ndist_{ij}^2 = tr(B)+nb_{ii} j=1∑ndistij2=tr(B)+nbii
∑ i = 1 n d i s t i j 2 ∑ j = 1 n = 2 n t r ( B ) \sum_{i=1}^ndist_{ij}^2\sum_{j=1}^n = 2ntr(B) i=1∑ndistij2j=1∑n=2ntr(B)
从这三个结论我们可以反推出,具有中心化性质的Z矩阵对应的内积矩阵B
b i j = − 1 2 ( d i s t i j 2 − 1 n ∑ j = 1 n d i s t i j 2 − 1 n ∑ i = 1 n d i s t i j 2 + 1 n 2 ∑ i = 1 n ∑ j = 1 n d i s t i j 2 b_{ij} = -\frac{1}{2}(dist_{ij}^2-\frac{1}{n}\sum_{j=1}^n dist_{ij}^2-\frac{1}{n}\sum_{i=1}^n dist_{ij}^2+\frac{1}{n^2}\sum_{i=1}^n\sum_{j=1}^n dist_{ij}^2 bij=−21(distij2−n1j=1∑ndistij2−n1i=1∑ndistij2+n21i=1∑nj=1∑ndistij2
内积矩阵是 B = Z Z T B = ZZ^T B=ZZT,可以用特征值分解来解Z。 B = V Λ V T B = V\Lambda V^T B=VΛVT,则 Z = V Λ 1 2 Z = V \Lambda^{\frac{1}{2}} Z=VΛ21。我们取前d个特征向量和特征值,就得到了降维后的Z矩阵。
import heapq
def MDS(D,dim):
m = len(D)
disti_ = np.zeros(m)
dist_j = np.zeros(m)
dist__ = 0
for i in range(m):
disti_[i]=np.mean(D[i,:])
for j in range(m):
dist_j[j]=np.mean(D[:,j])
dist__ = np.mean(D)
B = np.copy(D)
for i in range(m):
for j in range(m):
B[i][j] += (-disti_[i]-dist_j[j]+dist__)
B[i][j] *= -0.5
vals, vecs = np.linalg.eig(B)
lamda,V=np.linalg.eigh(B)
index=np.argsort(-lamda)[:dim]
diag_lamda=np.sqrt(np.diag(-np.sort(-lamda)[:dim]))
V_selected=V[:,index]
Z=V_selected.dot(diag_lamda)
return Z
def Isomap(X, k, dim):
N = len(X)
D = np.zeros((N,N))
for i in range(N):
for j in range(i+1,N):
D[i][j] = dist(X[i],X[j])**0.5
D[j][i] = D[i][j]
bound = D.max()
Map = np.ones((N,N))*1000
n,m = X.shape
for i in range(n):
knn = np.argsort(D[i])[1:k+1] #得到每个点的k近邻
Map[i,knn] = D[i,knn]
Map[knn,i] = D[knn,i]
#Floyd算法
for k in range(N):
for i in range(N):
for j in range(N):
Map[i][j] = min(Map[i][k]+Map[k][j],Map[i][j])
Map[np.where(Map==1000)] = bound
return MDS(Map,dim)
X, t = make_swiss_roll(n_samples=300, noise=0, random_state=0)
Z = Isomap(X,k=4,dim=2)
plt.scatter(Z[:, 0], Z[:, 1], c=t, cmap=plt.cm.hot)
plt.show()
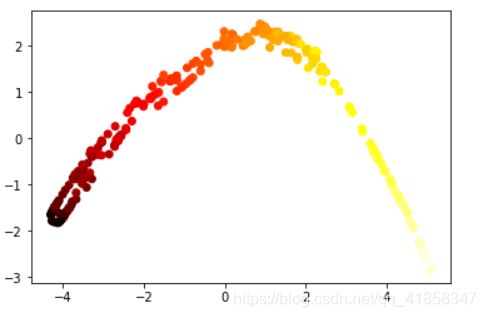
虽然Isomap一般能比较完美地学习流形,但Isomap的劣势也非常明显,它必须花费 O ( n 3 ) O(n^3) O(n3)的时间开销去计算距离矩阵,这比一般算法的 O ( n 2 ) O(n^2) O(n2)要可怕很多。即使是在上面的1000级别的瑞士卷样本上跑一次都要花费相当多的时间。尽管我们可以用一些近似算法来做一些加速,但是这仍然不是一个高效的算法。
SNE
stochastic neighbor embedding,事实上我们从上面的例子可以看出来,LLE解决的问题是"把原本就靠近的数据点相互靠近",这可以在原始数据分布性质比较好,分布比较开的数据集上表现得不错。但是如果原始数据集的分布性质一般,像是上面的流形,算法的确会把近似的点都放在一起,但是并不保证不相似的点能分开。虽然LLE经过细致的调参可以在上面的流形跑出还不错的结果,但是这并非我们想要的。
TSNE一定程度上解决的就是这个问题,它使用了概率和近似的方法,一般能得到高维到低维的比较好的效果。它也是当前最常被用作可视化工具的一种方法。
算法
这个算法基于距离,给出样本点的相似度概念;这个相似度还会被归一化成概率形式。
P ( x j ∣ x i ) = S ( x i , x j ) ∑ k ≠ i S ( x i , x k ) P(x_j|x_i) = \frac{S(x_i,x_j)}{\sum_{k\neq i}S(x_i,x_k)} P(xj∣xi)=∑k=iS(xi,xk)S(xi,xj)
P ( z j ∣ z i ) = S ′ ( z i , z j ) ∑ k ≠ i S ′ ( z i , z k ) P(z_j|z_i) = \frac{S'(z_i,z_j)}{\sum_{k\neq i}S'(z_i,z_k)} P(zj∣zi)=∑k=iS′(zi,zk)S′(zi,zj)
算法的优化目标是两个概率分布的KL散度
L = ∑ i K L ( P ( ∗ ∣ x i ) ∣ ∣ Q ( ∗ ∣ z i ) ) = ∑ i ∑ j P ( x j ∣ x i ) l o g P ( x j ∣ x i ) Q ( z j ∣ z i ) L = \sum_i KL(P(*|x_i)||Q(*|z_i)) = \sum_i\sum_j P(x_j|x_i)log\frac{P(x_j|x_i)}{Q(z_j|z_i)} L=i∑KL(P(∗∣xi)∣∣Q(∗∣zi))=i∑j∑P(xj∣xi)logQ(zj∣zi)P(xj∣xi)
SNE在相似度上使用的分布函数是高斯函数。
P ( x j ∣ x i ) = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 / 2 σ i 2 ) ∑ k ≠ i e x p ( − ∣ ∣ x i − x k ∣ ∣ 2 / 2 σ i 2 ) P(x_j|x_i) = \frac{exp(-||x_i-x_j||^2/2\sigma_i^2)}{\sum_{k\neq i}exp(-||x_i-x_k||^2/2\sigma_i^2)} P(xj∣xi)=∑k=iexp(−∣∣xi−xk∣∣2/2σi2)exp(−∣∣xi−xj∣∣2/2σi2)
想执行算法可能还需要先确定每个i对应的方差(高斯核带宽),这个过程也是有方法做的。原始论文用的是perplexity的定义。我们用二分法找一个困惑度最小的方差
P e r p ( P i ) = 2 H ( P i ) Perp(P_i) = 2^{H(P_i)} Perp(Pi)=2H(Pi)
H ( P i ) = − ∑ j p j ∣ i l o g 2 p j ∣ i H(P_i) = -\sum_j p_{j|i}log_2 p_{j|i} H(Pi)=−j∑pj∣ilog2pj∣i
但是实际使用的时候,一般会在转换前的高维空间进行搜索,对低维直接用常数。确定了方差,一切就都可以计算了,我们可以用梯度下降来解这个问题
∂ L ∂ y i = 2 ∑ j ( p j ∣ i − q j ∣ i + p i ∣ j − q i ∣ j ) ( y i − y j ) \frac{\partial L} {\partial y_i} = 2\sum_j(p_{j|i}-q_{j|i}+p_{i|j}-q{i|j})(y_i-y_j) ∂yi∂L=2j∑(pj∣i−qj∣i+pi∣j−qi∣j)(yi−yj)
t-SNE
SNE的缺点是不容易优化,Hinton等人在08年提出了t-SNE这种变形。主要改动了以下两点。
- t-SNE在相似度上使用的分布函数是高斯函数和学生氏分布(t分布)。
p i ∣ j = e x p ( − ∣ ∣ x i − x j ∣ ∣ 2 / 2 σ i 2 ) ∑ k ≠ i e x p ( − ∣ ∣ x k − x i ∣ ∣ 2 / 2 σ i 2 ) p_{i|j} = \frac{exp(-||x_i-x_j||^2/2\sigma_i^2)}{\sum_{k\neq i}exp(-||x_k-x_i||^2/2\sigma_i^2)} pi∣j=∑k=iexp(−∣∣xk−xi∣∣2/2σi2)exp(−∣∣xi−xj∣∣2/2σi2)
q i ∣ j = ( 1 + ∣ ∣ x i − x j ∣ ∣ 2 ) − 1 ∑ k ≠ i ( 1 + ∣ ∣ x k − x i ∣ ∣ 2 ) − 1 q_{i|j} = \frac{(1+||x_i-x_j||^{2})^{-1}}{\sum_{k\neq i}(1+||x_k-x_i||^{2})^{-1}} qi∣j=∑k=i(1+∣∣xk−xi∣∣2)−1(1+∣∣xi−xj∣∣2)−1
因为t分布更有长期性,在新空间中可以表现得更好。 - 这里的分布不再是条件概率分布,而是联合概率分布。同时提出假设,假设pij=pji。另外,为了柔和化异常点的影响,我们使用修正的概率计算梯度。
p i j = ( p i ∣ j + p j ∣ i ) / 2 p_{ij} = (p_{i|j}+p_{j|i})/2 pij=(pi∣j+pj∣i)/2
这时的梯度也有更为简单的形式。
∂ L ∂ y i = 4 ∑ j ( p i j − q i j ) ( y i − y j ) ( 1 + ∣ ∣ y i − y j ∣ ∣ 2 ) − 1 \frac{\partial L} {\partial y_i} = 4\sum_j(p_{ij}-q_{ij})(y_i-y_j)(1+||y_i-y_j||^2)^{-1} ∂yi∂L=4j∑(pij−qij)(yi−yj)(1+∣∣yi−yj∣∣2)−1
这里贴一篇讲的比较好的博客:click.
def cal_pairwise_dist(x):
'''计算pairwise 距离, x是matrix
(a-b)^2 = a^2 + b^2 - 2*a*b
'''
sum_x = np.sum(np.square(x), 1)
dist = np.add(np.add(-2 * np.dot(x, x.T), sum_x).T, sum_x)
#返回任意两个点之间距离的平方
return dist
# 计算困惑度,最终会选择合适的beta,也就是每个点的方差啦
def cal_perplexity(dist, idx=0, beta=1.0):
# '''计算perplexity, D是距离向量,
# idx指dist中自己与自己距离的位置,beta是高斯分布参数
# 这里的perp仅计算了熵,方便计算
# '''
prob = np.exp(-dist * beta)
# 设置自身prob为0
prob[idx] = 0
sum_prob = np.sum(prob)
if sum_prob == 0:
prob = np.maximum(prob, 1e-12)
perp = -12
else:
prob /= sum_prob
perp = 0
for pj in prob:
if pj != 0:
perp += -pj*np.log(pj)
# 困惑度和pi\j的概率分布
return perp, prob
def seach_prob(x, tol=1e-5, perplexity=30.0):
# '''二分搜索寻找beta,并计算pairwise的prob
# '''
# 初始化参数
print("Computing pairwise distances...")
(n, d) = x.shape
dist = cal_pairwise_dist(x)
pair_prob = np.zeros((n, n))
beta = np.ones((n, 1))
# 取log,方便后续计算
base_perp = np.log(perplexity)
for i in range(n):
if i % 500 == 0:
print("Computing pair_prob for point %s of %s ..." %(i,n))
betamin = -np.inf
betamax = np.inf
#dist[i]需要换不能是所有点
perp, this_prob = cal_perplexity(dist[i], i, beta[i])
# 二分搜索,寻找最佳sigma下的prob
perp_diff = perp - base_perp
tries = 0
while np.abs(perp_diff) > tol and tries < 50:
if perp_diff > 0:
betamin = beta[i].copy()
if betamax == np.inf or betamax == -np.inf:
beta[i] = beta[i] * 2
else:
beta[i] = (beta[i] + betamax) / 2
else:
betamax = beta[i].copy()
if betamin == np.inf or betamin == -np.inf:
beta[i] = beta[i] / 2
else:
beta[i] = (beta[i] + betamin) / 2
# 更新perb,prob值
perp, this_prob = cal_perplexity(dist[i], i, beta[i])
perp_diff = perp - base_perp
tries = tries + 1
# 记录prob值
pair_prob[i,] = this_prob
print("Mean value of sigma: ", np.mean(np.sqrt(1 / beta)))
#每个点对其他点的条件概率分布pi\j
return pair_prob
def tsne(x, no_dims=2, initial_dims=50, perplexity=30.0, max_iter=800):
"""Runs t-SNE on the dataset in the NxD array x
to reduce its dimensionality to no_dims dimensions.
The syntaxis of the function is Y = tsne.tsne(x, no_dims, perplexity),
where x is an NxD NumPy array.
"""
# Check inputs
if isinstance(no_dims, float):
print("Error: array x should have type float.")
return -1
if round(no_dims) != no_dims:
print("Error: number of dimensions should be an integer.")
return -1
(n, d) = x.shape
print (x.shape)
#动量
lr = 500
# 随机初始化Y
y = np.random.randn(n, no_dims)
# dy梯度
dy = np.zeros((n, no_dims))
# 对称化
P = seach_prob(x, 1e-5, perplexity)
P = P + np.transpose(P)
P = P / np.sum(P) #pij
# early exaggeration
# pi\j
P = P * 4
P = np.maximum(P, 1e-12)
# Run iterations
for iter in range(max_iter):
# Compute pairwise affinities
sum_y = np.sum(np.square(y), 1)
num = 1 / (1 + np.add(np.add(-2 * np.dot(y, y.T), sum_y).T, sum_y))
num[range(n), range(n)] = 0
Q = num / np.sum(num) #qij
Q = np.maximum(Q, 1e-12) #X与Y逐位比较取其大者
# Compute gradient
#pij-qij
PQ = P - Q
#梯度dy
for i in range(n):
dy[i,:] = np.sum(np.tile(PQ[:,i] * num[:,i], (no_dims, 1)).T * (y[i,:] - y), 0)
# 更新y
y = y - lr*dy
# 减去均值
y = y - np.tile(np.mean(y, 0), (n, 1))
# Compute current value of cost function
if (iter + 1) % 50 == 0:
if iter > 100:
C = np.sum(P * np.log(P / Q))
else:
C = np.sum( P/4 * np.log( P/4 / Q))
print("Iteration ", (iter + 1), ": error is ", C)
# Stop lying about P-values
if iter == 100:
P = P / 4
print("finished training!")
return y
X, t = make_swiss_roll(n_samples=1000, noise=0, random_state=0)
Y = tsne(X, 2, 50, 20.0)
plt.scatter(Y[:, 0], Y[:, 1], 20, c = t, cmap=plt.cm.hot)
plt.show()
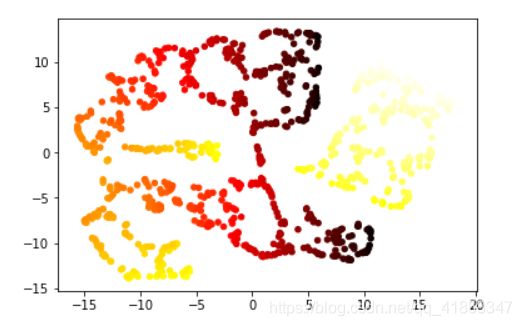
小结
上面的算法是比较常见的降维算法,它们有不同的应用场景。PCA在无标签的大量数据降维时比较有效,而如果是为了分析值域和可视化,t-SNE是最常用的方法。此外,isomap可以很好的学习流形,auto-encoder可以做生成式模型和其他有意思的无监督学习任务。所有的算法没有绝对的优劣,都是视应用场景而定。
还有就是学好线性代数太重要了。