利用CNN实现图像和数值数据融合
利用CNN实现图像(MRI)和数值数据融合
一、背景
在很多实际任务当中,模型构建数据类型多样,有数值型、图像、音频等各式各样的数据,如果单纯利用某种类型的数据构建分类或回归模型,好处是构建简单,数据不存在类型不同融合困难的问题,但如果单纯的利用某一种数据且模型性能一般,如accuracy在0.6-0.7之间徘徊,那有必要纳入更多的特征,特别是在医疗领域,部分数值型数据本来的可分性就不好,因此要纳入一部分的图像数据,如早期预测一个人是否会患某种疾病,训练集样本均为正常人,此时无论是数值型数据或影像数据,区别并不大,因此要考虑融合二者来提升预测的准确性。
二、目前常用的图像和数值型数据融合的方式
目前来说,把图像和数值型数据融合方式有三种:
1、直接把图像转为向量
这种方法是最暴力的解法,如一张32X32像素的彩色图片,其转化为向量为32X32X3=3072,相当于纳入了3072个特征,优点是纳入了所有图像中的细节(像素级),缺点是由于纳入了所有的细节(像素),会不必要的有一部分混杂因素,因此需要复杂的特征工程,另一方面,其计算量会大大增加,导致模型拟合或后期应用出现问题。
2、利用软件提取图像中的某些特征
 如上面的这张颅脑磁共振成像,利用某些软件如FSL,可以提取丘脑、海马体、脑皮厚度、脑容量等参数,之后把这部分参数当作新的特征和数值型数据融合,优点是大大减少了特征数,提升了计算速度,缺点是一些器质性病变无法体现。
如上面的这张颅脑磁共振成像,利用某些软件如FSL,可以提取丘脑、海马体、脑皮厚度、脑容量等参数,之后把这部分参数当作新的特征和数值型数据融合,优点是大大减少了特征数,提升了计算速度,缺点是一些器质性病变无法体现。
3、利用CNN(卷积神经网络)
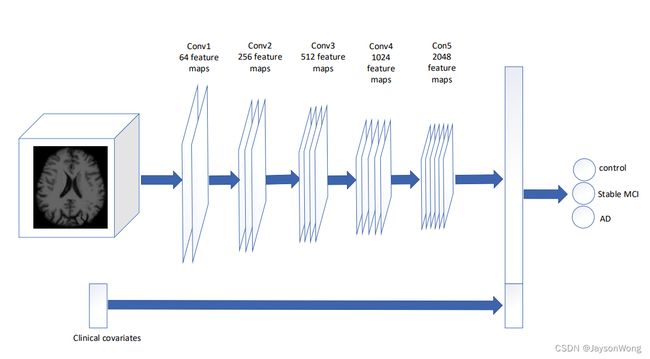
CNN也可以用来提取特征,前提是该模型预测准确性较好,自然相当于提取的特征较为准确,一般是在卷积基后的flatten层和数值型数据拼接在一起,实现图像和数值型数据的融合,具体如上图所示。
三、CNN实现图像和数值型数据融合的步骤
1、训练CNN网络
这一步是整个融合过程中较为重要的步骤,只有较为准确的CNN网络才能提取准确有用的特征,一般采用预训练+微调的模式来训练CNN,为了演示方便,我们采用Fashion MNIST数据集来为我们的图像,iris数据集作为我们的数值型数据,来做演示。另外由于Fashion MNIST类别有10中,而iris只有3种,我们之纳入irsi的数据来“假定为我们图像配套的数值型数据”,新建一个py文件,具体代码如下:
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow import keras
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 加载数据
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 查看数据大小
# print(train_images.shape)
# print(test_images.shape)
# 数据集归一化
train_images_norm = train_images / 255.0
test_images_norm = test_images / 255.0
train_images_reshape = train_images.reshape([-1, 28, 28, 1])
test_images_reshape = test_images.reshape([-1, 28, 28, 1])
L = keras.layers
model = keras.Sequential([
# 卷积层
L.Conv2D(input_shape=(28, 28, 1), filters=32, kernel_size=3, strides=1),
# 池化层
L.MaxPool2D(pool_size=2, strides=2),
# 卷积层
L.Conv2D(filters=64, kernel_size=3, strides=1),
# 池化层
L.MaxPool2D(pool_size=2, strides=2),
# 全连接层
L.Flatten(),
L.Dense(256, activation='relu'),
L.Dense(10, activation='softmax')
])
model.summary()
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_images_norm, train_labels, epochs=5, validation_split=0.2)
test_loss, test_acc = model.evaluate(test_images_norm, test_labels)
print('test_loss:{}, test_acc{}'.format(test_loss, test_acc))
# 保存模型
# model.save('ConV_DT.h5')
上面代码主要训练了一个CNN模型,之后保存为ConV_DT.h5,方便下一步使用。
2、载入已经训练好的模型,提取图像特征并和数值型数据拼接
新建另外一个py文件,这部分代码主要实现利用已经构建好的模型,重新输入训练图片,来输出Flatten层的输出,之后和数值型数据拼接,也就是iris数据集,这部分的代码如下:
import pandas as pd
import tensorflow as tf
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
# 查看数据大小
# print(train_images.shape)
# print(test_images.shape)
# 数据集归一化
train_images_norm = train_images / 255.0
test_images_norm = test_images / 255.0
train_images_reshape = train_images.reshape([-1, 28, 28, 1])
test_images_reshape = test_images.reshape([-1, 28, 28, 1])
# print(test_images_reshape[0].shape)
# 读取iris数据
iris = load_iris()
data = iris.data
labels = iris.target
# 载入模型
model = tf.keras.models.load_model('ConV_DT.h5')
# 输出flatten层的输出
representation_model = tf.keras.models.Model(inputs=model.input, outputs=model.get_layer('flatten').output)
flatten_output = representation_model.predict(train_images_reshape)
print(type(flatten_output))
print(flatten_output.shape)
print(flatten_output[0].shape)
# 由于IRIS数据集长度为150行,因此我们也选取Fashion_MNIST数据集的前150行,来做数据融合
df_1 = pd.DataFrame(flatten_output[:150, :])
df_2 = pd.DataFrame(data)
all_data = pd.concat([df_1, df_2], axis=1, join='outer')
print(all_data.values)
print('--------------')
print(all_data.shape)
这部分代码的输出为:
1875/1875 [==============================] - 4s 1ms/step
<class 'numpy.ndarray'>
(60000, 1600)
(1600,)
[[ 1.83051303e-02 -1.34976834e-01 -2.31863484e-02 ... 3.50000000e+00
1.40000000e+00 2.00000000e-01]
[-6.31221123e+01 2.14652161e+02 -2.21633682e+01 ... 3.00000000e+00
1.40000000e+00 2.00000000e-01]
[ 3.02642097e+01 2.99987674e-01 1.92712307e+00 ... 3.20000000e+00
1.30000000e+00 2.00000000e-01]
...
[ 1.02550278e+02 2.27436676e+02 3.78363113e+01 ... 3.00000000e+00
5.20000000e+00 2.00000000e+00]
[-5.90932703e+00 8.05619736e+01 -4.51921177e+00 ... 3.40000000e+00
5.40000000e+00 2.30000000e+00]
[-1.93223495e+01 1.43665100e+02 -4.19176483e+01 ... 3.00000000e+00
5.10000000e+00 1.80000000e+00]]
--------------
(150, 1604)
我们可以看到,图片经过CNN特征提取后共提取了1600个特征,之后和iris的个特征拼接输出为1604个特征。
3、利用新的特征进行预测
这部分就是简单的利用机器学习模型或者神经网络来进行数据融合后的预测,此处我们选用的为决策树(DT),具体代码如下:
x_train, x_test, y_train, y_test = train_test_split(all_data.values, test_labels, test_size=0.3)
dt = DecisionTreeClassifier(max_depth=10)
dt.fit(x_train, y_train)
score = dt.score(x_test, y_test)
print(score)
这部分代码的输出为:
0.6
四、总结
本篇文章主要提供一种图像和数值型数据融合的思路和关键代码,具体的准确性不高是因为选取的例子,仅供参考,实际应用中还要考虑图像的归一化、去噪、随机旋转、图像增强等,对于融合后的数据,仍需要进行特征工程,以及模型超参数的调整,来实现准确性的进一步提升。