使用条件向量的轻量级增强网络-CSRNet分享
目录
论文简介
网络介绍
工作原理说明
网络代码
试验结果
消融试验
base network
condition network
modulation stragegy
总结
论文简介
论文题目:Conditional Sequential Modulation for Efficient Global Image Retouching
论文地址:https://arxiv.org/pdf/2009.10390.pdf
代码地址:https://github.com/hejingwenhejingwen/CSRNet
文章使用了一个条件向量,通过加入条件向量,可以较大幅度提升效果,同时可以控制图像增强的效果,在不同风格间进行切换。另外,网络可以做到很小,轻量级,对大分辨率的图像处理的速度也会较快。
网络介绍
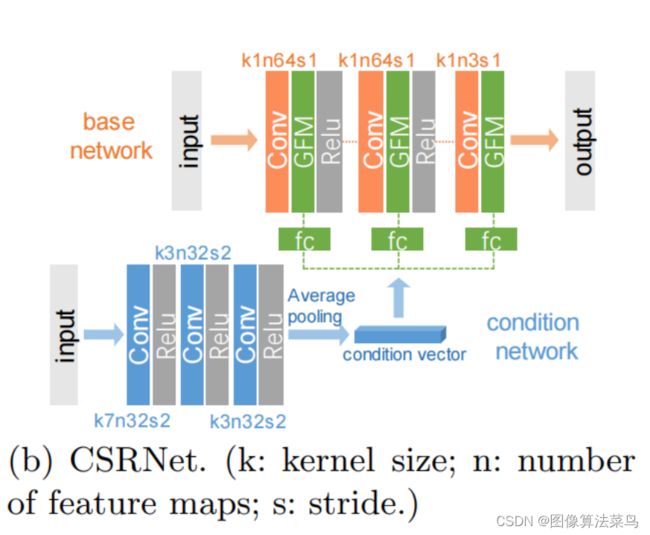
文章使用轻量级网络来做图像增强处理,如图所示,网络分成base network和condition network,base network很轻量,只有三层卷积层,且是1x1的卷积核,通道数为64,参数量很小,计算量也不大;condition network使用小网络,得到一个条件向量,其实就是为了得到图像的某些全局特征,如果是大图,可以把图先做下采样,然后再经过condition network得到条件向量;条件向量再经过3个FC模块,得到scale和shift系数,分别作用到base network的特征图上,该步骤称为GFM,其公式如下。
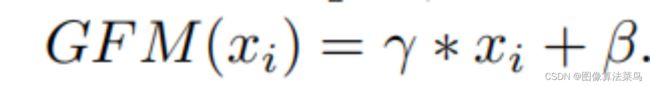
文章的主要创新点为条件向量的引入,这里的条件向量是由图像本身,经过小网络得到的,可以扩展到外部输入的条件向量,这样网络的效果就具有了一定的肯定性,需要不同风格时,base network可以不动,只要修改条件向量即可。
工作原理说明
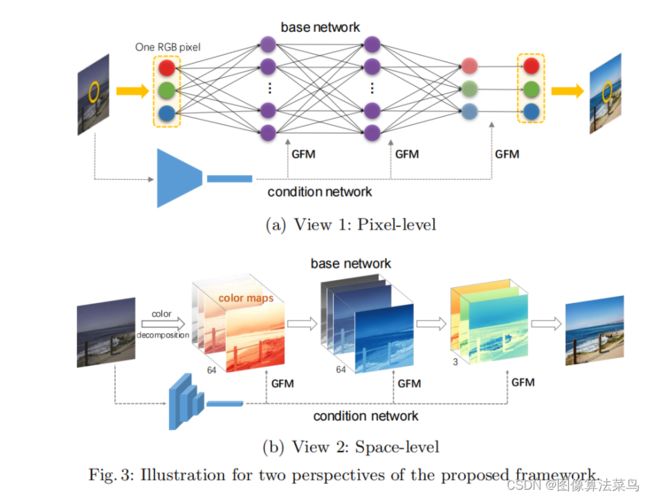
从像素级来解释该过程,就是把RGB图,经过多层感知机,得到中间特征量,特征量与条件向量做GFM操作,经过三层操作,再把特征量变成了RGB 。
从颜色空间角度来解释该过程,就是把图像的RGB空间,转到了另外的颜色空间,在这个颜色空间,通过GFM操作,对颜色空间特征进行某种变换,缩放和平移,经过三次该操作,最后又转回了RGB空间。
网络代码
import functools
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
class Condition(nn.Module):
def __init__(self, in_nc=3, nf=32):
super(Condition, self).__init__()
stride = 2
pad = 0
self.pad = nn.ZeroPad2d(1)
self.conv1 = nn.Conv2d(in_nc, nf, 7, stride, pad, bias=True)
self.conv2 = nn.Conv2d(nf, nf, 3, stride, pad, bias=True)
self.conv3 = nn.Conv2d(nf, nf, 3, stride, pad, bias=True)
self.act = nn.ReLU(inplace=True)
def forward(self, x):
conv1_out = self.act(self.conv1(self.pad(x)))
conv2_out = self.act(self.conv2(self.pad(conv1_out)))
conv3_out = self.act(self.conv3(self.pad(conv2_out)))
out = torch.mean(conv3_out, dim=[2, 3], keepdim=False)
return out
# 3layers with control
class CSRNet(nn.Module):
def __init__(self, in_nc=3, out_nc=3, base_nf=64, cond_nf=32):
super(CSRNet, self).__init__()
self.base_nf = base_nf
self.out_nc = out_nc
self.cond_net = Condition(in_nc=in_nc, nf=cond_nf)
self.cond_scale1 = nn.Linear(cond_nf, base_nf, bias=True)
self.cond_scale2 = nn.Linear(cond_nf, base_nf, bias=True)
self.cond_scale3 = nn.Linear(cond_nf, 3, bias=True)
self.cond_shift1 = nn.Linear(cond_nf, base_nf, bias=True)
self.cond_shift2 = nn.Linear(cond_nf, base_nf, bias=True)
self.cond_shift3 = nn.Linear(cond_nf, 3, bias=True)
self.conv1 = nn.Conv2d(in_nc, base_nf, 1, 1, bias=True)
self.conv2 = nn.Conv2d(base_nf, base_nf, 1, 1, bias=True)
self.conv3 = nn.Conv2d(base_nf, out_nc, 1, 1, bias=True)
self.act = nn.ReLU(inplace=True)
def forward(self, x):
cond = self.cond_net(x)
scale1 = self.cond_scale1(cond)
shift1 = self.cond_shift1(cond)
scale2 = self.cond_scale2(cond)
shift2 = self.cond_shift2(cond)
scale3 = self.cond_scale3(cond)
shift3 = self.cond_shift3(cond)
out = self.conv1(x)
out = out * scale1.view(-1, self.base_nf, 1, 1) + shift1.view(-1, self.base_nf, 1, 1) + out
out = self.act(out)
out = self.conv2(out)
out = out * scale2.view(-1, self.base_nf, 1, 1) + shift2.view(-1, self.base_nf, 1, 1) + out
out = self.act(out)
out = self.conv3(out)
out = out * scale3.view(-1, self.out_nc, 1, 1) + shift3.view(-1, self.out_nc, 1, 1) + out
return out从代码看,和公式有点不一样的是,GFM是out = out*scale + shift + out,而不是out=out*scale + shift,当然,二者是等价的。
试验结果
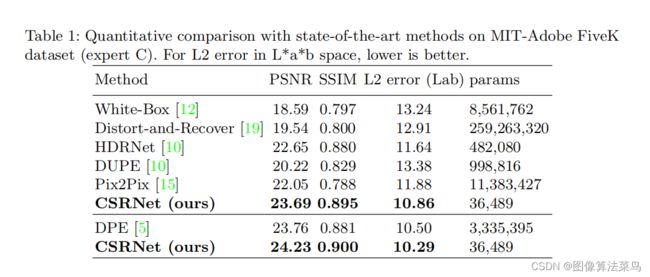
训练时,loss就采用了简单的l2 loss,在FiveK数据集上进行了训练,和一些其他的算法进行了比较,得到客观指标优于其他几张算法,而网络的参数量很小,可以大分辨率的图都可以。
消融试验
论文做了三个方面的消融试验。
base network
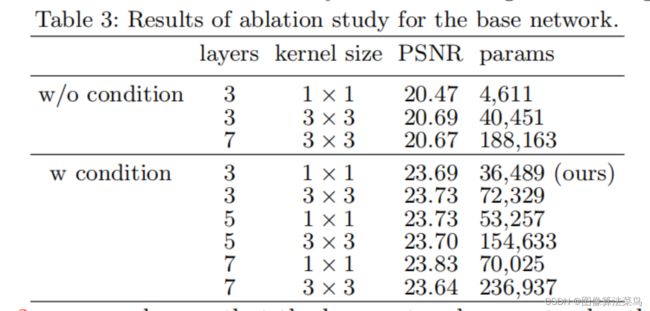
base network的消融试验,没有condition network时,增加卷积核大小,或者加深网络(参数量增大),得到的客观指标差不多,有condition network时,增大卷积核或者加深网络,客观指标也差异不大,加深网络稍微有点提升,所以使用1x1的卷积核即可。
condition network
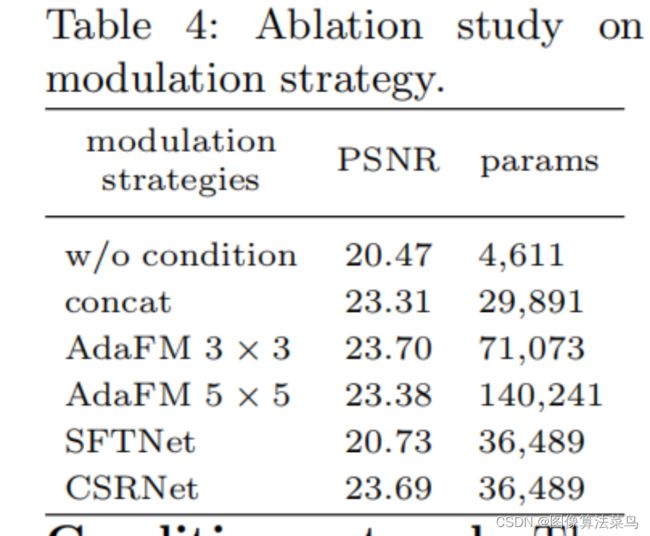
没有条件向量,效果会下降很多,使用SFTNet(跟位置有关的信息量),效果并没多少提升,而使用全局的某些特征,是可以较大提升效果的,直接concat也可以提升,但相比GFM的scale和shift要差一些,AdaFM(使用了卷积核,GFM是卷积核为1的情况)的方式相比GFM提升也不大,所以作者认为GFM是最好的。
modulation stragegy
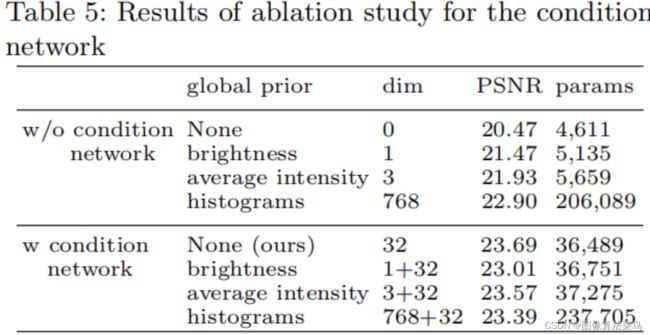
对比多种全局信息,从试验中得到,histograms大于average intensity大于brightness,但还是使用condition network学出来的32个特征量最好,如果把这些特征量再加上另外三种全局信息,效果并没有提升,所以认为condition network学习到的全局信息是最好的。
总结
我认为论文还是有一定的创新性和实用性的,创新性主要体现在了条件向量的使用,该方法时可以借鉴的,可以当作外部输入向量来控制效果的风格。实用性主要是可以做大分辨率图像的增强处理,网络的参数量很小,计算量也还好,相当于几次滤波,条件网络可以用来处理小分辨率的图像,该部分计算量比较小。