DBNet 论文笔记
白翔老师组、旷视科技、上交 2019年发表在AAAI上的一篇文字检测论文,提出的模型简称DBNet
DBNet 中的 DB是 Differentiable Binarization 的缩写,翻译为可微分的二值化。在 DBNet 中,分割结果的二值化后处理可以随着模型一起训练,得到一个自适应的阈值。自适应的阈值也可以使得后处理变得简单,提升进度,也提高速度。
我理解整体的思路是预测收缩核心区,并且通过自适应阈值提高边缘的准确性。预测时用收缩核心区反向扩张得到完整文字框。
开源代码:https://github.com/MhLiao/DB
介绍
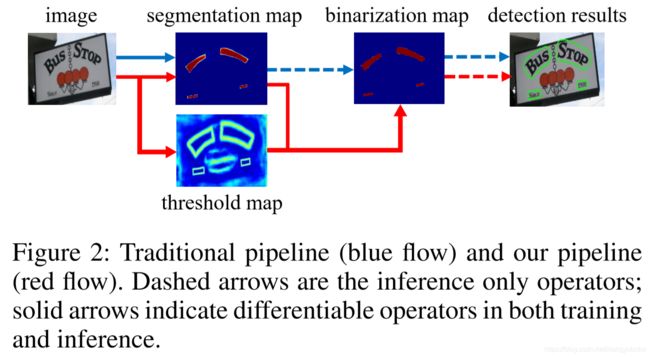
以往基于分割的文字检测都是走蓝色线,先得到分割的 score map,然后根据一些启发式算法,对 score map 做二值化,最后得到分割结果。作者新提出来的是走红色线,把二值化操作融合到模型中一起优化。因此,每一个像素的阈值都能被自适应的预测出来,并且具有很好的前景、背景区分度。传统的二值化过程不可微分,作者提出来了一个可微分的二值化(DB)。
相关工作
整套算法的结构如下图:

首先,图片输入到带 FPN 的主干网络,然后处理到最终特征图 F。从 F 里计算出 probability map 和 threshold map,根据这两个 map 计算出 approximate map。在训练阶段,这三个 map 都会被训练计算 loss,其中 probability map 和 approximate map 使用相同的 ground truth。在推理阶段,可以直接通过 probability map 或者 approximate map,经过膨胀,得到最终结果。
可微分的二值化
一般的二值化是通过先定义一个阈值来对 probability map 的值做二值化。但这样就不可微分,没办法连同模型一起训练。所以作者提出一个近似的函数:

整体看,就是 sigmoid 函数的变化。T 是从网络中学习到的自适应阈值。k 是方法因子,经验上设置为50。k越大,这个函数就越窄,越接近于陡峭跳变。作者还提到,自适应的阈值不仅能有效分割前景背景、还有有效分开相互靠近的字段。
作者从计算梯度时候的反向传播来解释这个 DB 模块有如此功效。以二分类的交叉熵为损失函数:
L=-y'logy - (1-y')log(1-y)
把 DB 的 f(x)=1/(1+e^-kx) 带入预测的 y,那么可以得到正样本和负样本的损失分别是:
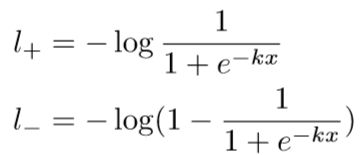
经过求导,可以得到对正负样本的导数为:

结合 DB 模块本身的定义一起看:
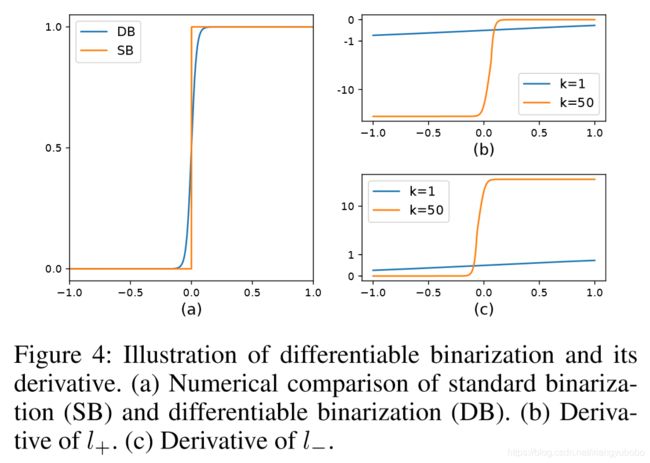
图(a)的DB和SB写反了。从图上可以看出来:
- 梯度会随着放大系数 k 而成倍放大
- 对于样本极性分错的情况,的梯度要远大于分对的情况
- x = Pij - Tij,对于 P 的梯度会受 T 的影响,能比较好的区分前景背景
自适应阈值
自适应的阈值图更类似于文字边界图。

从图上看,对于图(c),即使没有阈值图的监督,预测出来的阈值图也能比较好的区分出来,没有文字、文字边界、文字核心的几个区域。而图(d)则表示出加上文字边界图的损失,通过阈值图得到的边界则更加精细。
网络结构中还使用了可变性卷积(Deformable convolution)。可变性卷积能获得比较好的长宽比,这点正好适合文字检测任务。
标签生成
标签生成的方式和 PSENet 比较相似。对于一张图上的文字区域的外接多边形框,定义成边的集合:
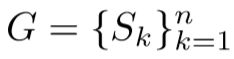
n表示有n条边。和 PSENet 一样,用 Vatti clipping 算法收缩成 Gs。收缩的距离和 PSENet 的计算方法一致:
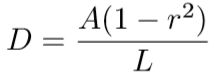
L 是多边形变长,A是多边形面积,r 经验性的设置为0.4。上文说到,阈值图更近似于边框阈图,作者采用了相同的方法生成。首先用相同的距离D做扩张,得到 Gd。把 Gs 和 Gd 之间的部分看做文字区域的边界区。然后利用两者到之间 G 的距离来计算标签。整个标签生成如下图:

损失函数
损失函数 L 由3部分组成:
![]()
Ls 表示 probability map,Lb 表示 binary map,Lt 表示 threshold map。 α 和 β 设置为1和10。对 Ls 和 Lb 使用二分类交叉熵,并且都使用相同的收缩标注。为了类别平衡,作者增加了对负样本的挖掘:
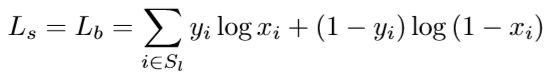
Sl 是按照正负样本 1:3 的比例采样的集合。不过也看到很多使用 Dice 损失计算这个部分的实现。
Lt 使用 L1 损失计算膨胀区域的像素:

Rd 表示膨胀区域的像素,y∗ 是 threshold map 的标签。
推理阶段,可以使用 probability map 或者 approximate binary map 来产生最后的文字框。一般说来,直接使用 probability map 效率更高一些。之后的后处理有如下3步:
- 用 0.2 的阈值卡一下,生成真正的二值图
- 将二值图区域联通
- 再次使用 Vatti clipping 扩大预测的收缩区域。扩张距离可以认为是和收缩距离计算反向:

A‘ 是预测区域的面积,L’ 是预测区域的周长,r’ 设置为1.5。