【目标检测】用Faster R-CNN训练自己的数据集
目录
一、环境准备
二、训练过程
三、推理过程
一、环境准备
我这里的环境是ubuntu18.04系统,colab + python3.7
二、训练过程
1、下载Faster R-CNN源码 ,我这里使用的源码是pytorch版本的 ,原作者的是tensorflow版本。在这里贴上代码地址。
https://github.com/chenyuntc/simple-faster-rcnn-pytorch https://github.com/chenyuntc/simple-faster-rcnn-pytorch.git
https://github.com/chenyuntc/simple-faster-rcnn-pytorch.git
2、安装扩展包
下载的源码中有一个 requirements.txt文件,列出了需要安装的扩展包名字。如果是在本地可以在cmd中直接运行以下代码:
pip install -r requirements.txt
如果是在colab环境下面,因为已经自带了torch和torchvision 我们只需要安装作者在Install
dependencies 里面列出的包。命令如下:
pip install visdom scikit-image tqdm fire ipdb matplotlib torchnet
3、修改训练参数
打开源码的utils文件夹下的config.py文件,修改其中一些重要参数,如:
--caffe-pretrain=False: use pretrain model from caffe or torchvision (Default: torchvison)--plot-every=n: visualize prediction, loss etc everynbatches.--env: visdom env for visualization--voc_data_dir: where the VOC data stored--use-drop: use dropout in RoI head, default False--use-Adam: use Adam instead of SGD, default SGD. (You need set a very lowlrfor Adam)--load-path: pretrained model path, default None, if it's specified, it would be loaded.
 4、替换数据集
4、替换数据集
源码中的数据集存放路径见上图 voc_data_dir 参数,我们将自己的数据集按照文件夹结构替换存放在VOCDevkit中。Annotations存放的是标签的XML文件,JPEGImages存放的是自己的数据集所有图片,ImageSets\Main文件夹下保存的是test.txt、train.txt、trainval.txt、val.txt,分别是测试集、训练集、训练验证集、验证集的标签文件名号。可以按照下图的结构制作自己的数据集。

考虑到源码中没有数据集划分程序,这里把划分代码贴出来,替换成自己的各个文件路径后直接运行就可以自动生成所需的txt文件啦。 核心代码如下:
import os
import random
trainval_percent = 0.0
train_percent = 0.0
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
5、修改目标类别
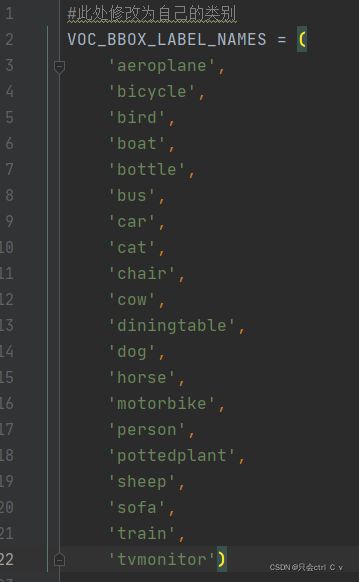
打开data目录下的voc_dataset.py文件,第137行VOC_BBOX_LABEL_NAMES表示目标检测的类别,将其修改为自己数据集的类别。
6、开始训练
在运行train.py 文件之前,另开一个终端运行
nohup python -m visdom.server &
可以在http://
运行
python train.py train --env='fasterrcnn' --plot-every=100
进行14个epoch的训练。

训练完成后会在根目录的checkpoints目录下生成权重文件

三、推理过程
找到源码下的demo.ipynb文件
在终端或命令行输入里面的代码,做如下修改:
img = read_image('预测的图片的路径')
img = t.from_numpy(img)[None]修改utils文件夹下的vis_tool.py 里面的VOC_BBOX_LABEL_NAMES 为自己的类别。
最后执行预测代码 源码给了两种预测的方法,取决于训练的时候加载的vgg16预训练权重是caffe框架的还是pytorch的。如果是pytorch 的就执行下面的代码。
trainer.load('训练好的权重路径')
opt.caffe_pretrain=False # this model was trained from torchvision-pretrained model
_bboxes, _labels, _scores = trainer.faster_rcnn.predict(img,visualize=True)
vis_bbox(at.tonumpy(img[0]),
at.tonumpy(_bboxes[0]),
at.tonumpy(_labels[0]).reshape(-1),
at.tonumpy(_scores[0]).reshape(-1))
这次内容就分享到这里了,希望与各位老师和小伙伴们交流学习~