CVPR 2022 | ST-MR:与Multiverse有何不同?(二)
(一)中有说ST-MR的整体架构与CVPR 2020 Multiverse的架构如出一辙,来看看为什么这么说。
ST-MR的模型架构如下,可以看到说Encoder部分是有两个分支,上分支为Graph Encoder,下分支为Location Encoder。名字上听起来还蛮唬人的,实际上上分支就是完成分类任务,即行人的最终位置落在特征图的哪个网格中;下分支实现的是一个回归任务,即调整行人最终位置与所落在网格中心点的偏差。对比一下ST-MR与Multiverse的架构图:
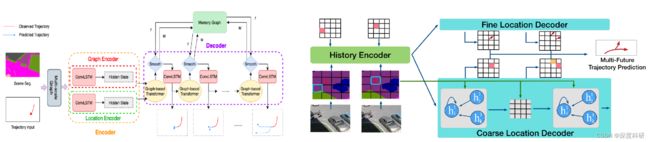 ST-MR(左)VS Multiverse(右)
ST-MR(左)VS Multiverse(右)
1. Classification
在ST-MR上分支,我们首先将行人的网格索引映射到一个18 x 32的网格图中,即(20,8,1)→(20,8,18,32,1)。然后,语义图 (20,8,36,64,11)经卷积提取特征后,与网格矩阵逐元素相乘,这一步实际上是将行人位置与语义场景信息相融合,得到行人更愿意出现在语义场景中的哪些位置。在ST-MR中的实现为公式(3),在Multiverse中的实现为公式(1):
(20,8,36,64,11)经卷积提取特征后,与网格矩阵逐元素相乘,这一步实际上是将行人位置与语义场景信息相融合,得到行人更愿意出现在语义场景中的哪些位置。在ST-MR中的实现为公式(3),在Multiverse中的实现为公式(1):
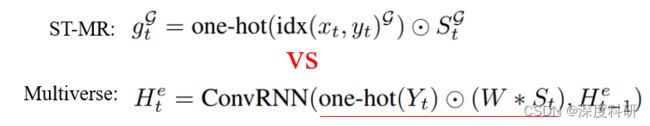
![]() 即为相乘得到的结果,其大小为(20,8,18,32,64)。将融合了行人信息与场景信息的矩阵
即为相乘得到的结果,其大小为(20,8,18,32,64)。将融合了行人信息与场景信息的矩阵![]() 喂给ConvLSTM进行编码,提取行人-场景交互的时空信息。需要注意的是:ConvLSTM的输入维度大小,x(n_samples, seq_len, H, W, channels)、h(n_samples, H, W, hidden_dim)、c(n_samples, H, W, hidden_dim)。另外需要注意的是:在Graph Encoder阶段我们只取ConvLSTM编码的最后一个时刻
喂给ConvLSTM进行编码,提取行人-场景交互的时空信息。需要注意的是:ConvLSTM的输入维度大小,x(n_samples, seq_len, H, W, channels)、h(n_samples, H, W, hidden_dim)、c(n_samples, H, W, hidden_dim)。另外需要注意的是:在Graph Encoder阶段我们只取ConvLSTM编码的最后一个时刻![]() 输入给Decoder,也即下图中的
输入给Decoder,也即下图中的![]() 。这一步在ST-MR中对应公式(1),在Multiverse中对应公式(1):
。这一步在ST-MR中对应公式(1),在Multiverse中对应公式(1):

Decoder阶段是由Graph-based Transformer与ConvLSTM交替组成,下一帧的输入来自上一帧预测的输出,如下图所示。这里要解释Graph-based Transformer实际上就是给Transformer Self attention穿上GAT的外衣。
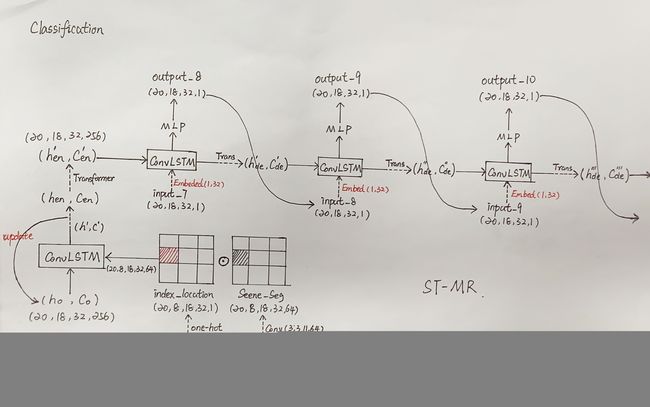 Classification
Classification
上述步骤在ST-MR中由公式(11)、(12)实现,在Multiverse中由公式(3)实现:

2. Regression
在ST-MR下分支中,输入是网格偏移坐标。网格偏移是指轨迹坐标与网格中心点的差值,求得差值(20,8,2)后我们将其以某种方式映射到一张特征图上(20,8,18,32,2)。这一步在ST-MR中对应公式(4),在Multiverse中对应公式(5):
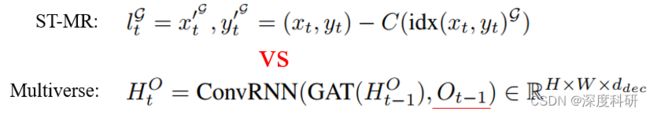
将网格偏移坐标输入给ConvLSTM,也就是下分支Location Encoder。与分类中类似,我们只取ConvLSTM最后一个时刻的输出,也即下图中的![]() 。这一步在ST-MR中对应公式(2),在Multiverse中对应公式(5):
。这一步在ST-MR中对应公式(2),在Multiverse中对应公式(5):
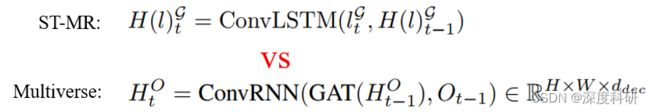
Decoder阶段是由只由ConvLSTM组成,同样,下一帧的输入来自上一帧预测的输出,如下图:
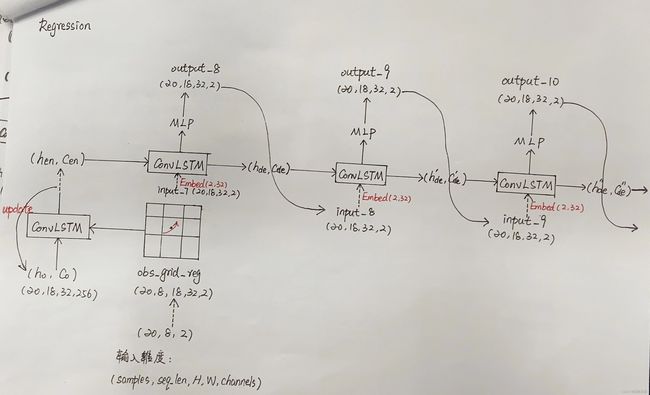 Regression
Regression
上述步骤在ST-MR中由公式(12)实现,在Multiverse中由公式(5)实现:

ST-MR最大的创新在于Memory Replay,实际上这是一个时间步缓存器,叠加来自上一步的输出,交给下一时间步作为输入。OK,ST-MR模型架构就解读到这里,如果不是大面积借鉴,应该是一篇不错的文章。