[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING
物体计数在VQA任务中的应用
论文地址:https://github.com/Cyanogenoid/vqa-counting
项目地址:https://openreview.net/pdf?id=B12Js_yRb
摘要
Visual Question Answering (VQA) models have struggled with counting objects in natural images so far. We identify a fundamental problem due to soft attention in these models as a cause. To circumvent this problem, we propose a neural network component that allows robust counting from object proposals. Experiments on a toy task show the effectiveness of this component and we obtain state-of-theart accuracy on the number category of the VQA v2 dataset without negatively affecting other categories, even outperforming ensemble models with our single model. On a difficult balanced pair metric, the component gives a substantial improvement in counting over a strong baseline by 6.6%.
到目前为止,视觉问答(VQA)模型一直在努力对自然图像中的对象进行计数。由于这些模型的软性关注,我们确定了一个根本问题。为了解决这个问题,我们提出了一种神经网络组件,该组件允许从对象提议中进行可靠的计数。toy task的实验证明了该组件的有效性,并且我们在VQA v2数据集的数字类别上获得了最新的准确性,而不会负面影响其他类别,甚至在我们的单个模型中也无法达到合奏模型的效果。在一个困难的平衡对度量标准上,该组件在将强大的基线作为基础进行计数时可显着提高6.6%。
1. Introduction
考虑一下计算图1中的猫数的问题。解决该问题涉及几个粗略的步骤:
①了解该类型的实例看起来像什么
②在图像中找到它们
③并将它们加起来。
这是视觉问题解答(VQA)中的常见任务,即回答有关图像的问题,并且被认为是要求人类年龄最低才能回答的任务之一(Antol等人,2015)。然而,遇到的模型经常问题:当前基于自然图像的VQA模型难以成功地解决数据集偏差之外的任何计数问题(Jabri等人,2016)。?
造成这种情况的一个原因是
①:在广泛使用的软注意力机制中存在一个基本问题(第3节)。
②:与标准计数任务不同,没有要计数的对象的地面事实标签。再加上模型需要能够计算各种各样的对象,并且理想情况下,不应影响非计数问题的性能,VQA中的计数任务似乎非常具有挑战性。
为了使此任务更轻松,我们可以使用来自对象检测网络的对象建议(一个边界框和对象特征对)作为输入,而不是直接从像素中学习。在任何中等复杂的场景中,都会遇到重复计算重叠对象提案的问题。这是许多自然图像中存在的问题,导致在实际场景中计数不准确。我们的主要贡献是可分解的神经网络组件,可以解决该问题,因此可以学习计数(第4节)。与注意力机制一起使用时,此组件避免了柔和注意力的基本限制,同时又产生了强大的计数功能。我们提供了该组件有效性的实验证据(第5节)。在toy数据集上,我们证明了此组件可在各种情况下实现可靠的计数。在VQA v2开放式数据集的数字类别上(Goyal等人,2017),使用计数组件的相对简单的基线模型在不降低性能的情况下优于所有以前的模型-包括大型的最新方法。其他类别的效果
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第1张图片](http://img.e-com-net.com/image/info8/3267cd92ff1245e0bcdc0626f84fa523.jpg)
图1 :有关计算猫咪数量的简化示例。浅色猫被检测到两次,并导致重复的建议。这显示了从注意力权重a到图形表示A的转换,以及该组件的最终目标,每个真实对象只有一个提议。有4个建议(顶点)捕获3个基础对象(虚线组)。有3个相关建议(权重为1的黑色)和1个无关建议(权重为0的白色)。红色边缘标记重复建议之间的对象内边缘,蓝色边缘标记对象之间的主要重复边缘。在图形形式中,对象组,边缘的颜色和顶点的阴影仅用于说明目的;该模型没有直接访问这些对象的权限
2. Related Work
通常,贪婪非最大抑制(NMS)是用来消除重复边界盒。使用它作为模型的一部分的主要问题是它的梯度是分段常数。
各方面不同的变体,例如Azadi等(2017),Hosang等。 (2017),以及亨德森和法拉利(2017)的存在。主要区别在于,由于我们对计数感兴趣,因此我们的组件无需针对保留哪些边界框做出离散决策;它输出计数功能,而不是较小的边界框。我们的组件还可以轻松集成到标准的VQA模型中,这些模型可以轻柔地使用注意力,而无需更改其他网络体系结构,并且无需使用真正的边界框进行监督即可使用。
本文模型提高的原因和其他别的论文的计数方法存在的不足
在我们应用我们的方法的VQA v2数据集(Goyal等人,2017)上,在计数问题方面仅取得了很少的进展。准确性的主要提高是由于在安德森(Anderson)等人提出的视觉处理管道中使用了对象建议。 (2017)。他们的对象建议网络使用单数和复数形式的类进行训练,例如“tree”与“trees”,这仅允许在感兴趣区域合并后在对象特征中出现原始计数信息。我们的方法的不同之处在于,我们不依赖输入中存在的计数功能,而是使用对象提案中注意力图中存在的信息来创建计数功能。这样做的好处是,它能够计算注意力机制所能分辨的任何事物,而不是仅计数属于具有多种形式的预定类集合的对象。 (2018)在VQA v2和Visual Genome的计数问题子集上训练了具有强化学习损失的顺序计数机制。它们的精度略有提高,并且可以获取其模型计算的可解释对象集,但是由于它们的损失不适用于非计数问题,因此尚不清楚其方法是否可以集成到传统VQA模型中。由于他们根据自己的数据集进行评估,因此无法轻易将其结果与VQA中的现有结果进行比较。例如Santoro等人的方法。 (2017)和Perez等。 (2017)可以成功地依靠合成CLEVR VQA数据集(Johnson et al。,2017),而无需界定框和监督要计数的对象的位置。他们还使用了更多的训练数据(CLEVR训练集中有大约250,000个问题,而VQA v2训练集中有50,000个问题),简单得多的对象和综合性问题结构。更多基于Lempitsky&Zisserman(2010)的传统方法可以学习生成目标密度图,通过对其进行积分来计算计数。在这种情况下,Cohen等人。 (2017年)利用卷积接受域的重叠来提高计数性能。 Chattopadhyay等。 (2017)使用一种方法将图像划分为较小的不重叠的块,每个块都单独计数,最后合并在一起。在这两种情况下,卷积接受域或块都可以看作是边界框的集合,边界框的位置固定。请注意,尽管Chattopadhyay等人。 (2017)在VQA中的一小部分计数问题上评估了他们的模型,培训设置方面的主要差异使其结果无法与我们的工作相提并论。
3.Problems with soft attention
本节的主要内容是,使用注意力机制之后获得的特征向量不足以进行计数。注意图本身应该被使用,这就是我们在计数组件中所做的。VQA中的模型一直受益于在图像上使用软注意(Mnih等,2014; Bahdanau等,2015),通常用浅层卷积网络实现它学习在特征图中的每个空间位置输出特征向量的权重,该权重首先进行归一化,然后用于在空间位置上执行加权总和以生成单个特征向量。但是,软空间注意力严重限制了模型进行计数的能力。
软注意力限制模型计数能力的原因案例
请考虑为两个图像计算猫的数量的任务:在干净的背景上显示一只猫的图像以及由两个并排组成的图像第一张图片的副本。我们将描述的内容既适用于空间特征图又适用于对象建议集,但为简单起见,我们将重点放在后一种情况。使用对象检测网络,我们在第一幅图像中检测到一只猫,在第二幅图像中检测到两只猫,从而为所有三个检测生成相同的特征向量。然后,注意机制为同一只猫的所有三个实例分配相同的权重。
用于注意力权重的通常归一化是softmax函数,该函数将权重归一化为1。这就是问题所在:第一个图像中的猫的归一化权重为1,但是第二个图像中的两只猫现在每个都归一化重量为0.5。在加权和之后,我们有效地将第二张图像中的两只猫平均为一只猫。结果,在加权和之后获得的特征向量在两个图像之间完全相同,并且我们已经从关注图中丢失了有关可能计数的所有信息。任何将权重归一化为1的方法都会遇到这个问题。
多重瞥见(Larochelle&Hinton,2010)——注意机制输出的注意权重集或注意的几个步骤(Yang等,2016; Lu et al。,2016)并没有解决这个问题。每个瞥见或步骤都不能将每个对象分开,因为赋予一个特征向量的注意力权重不取决于要关注的其他特征向量。尽管迄今为止尚未发现对后者的计数能力有明显改善,但Hard注意(Ba等,2015; Mnih等,2014)和structured注意(Kim等,2017)可能是解决问题的办法。 (Zhu et al。,2017)。 Ren&Zemel(2017)通过限制注意力一次只在一个边界框内工作来规避问题,这与我们使用对象建议特征的方法非常相似,如果不对权重进行归一化,则输出特征的规模取决于检测到的对象数。在一张有10只猫的图像中,输出特征向量将按比例放大10。由于深度神经网络通常对比例非常敏感-体重初始化和激活的比例通常被认为非常重要(Mishkin&Matas,2016)并且分类者必须了解所有特征的联合缩放与计数有某种关系,这种方法对于计数对象是不合理的。 Teney等人证明了这一点。 (2017),他们提供了乙状结肠归一化的证据,这不仅会稍微降低非数字问题的准确性,而且也无助于计数。
4.Counting Component 计算组件
在本节中,我们描述了一种从注意力权重进行计数的可区分机制,同时还处理了重叠的对象提议以减少对象重复计数的问题。这涉及一些重要的细节,以产生尽可能准确的计数。图1展示了主要思想,图2和图3展示了两个主要步骤。我们的这个组件不仅可以计数还可以继续利用软注意力的好处。我们处理重叠对象提案的关键思想是将这些对象提案转换为基于重叠方式的图形。然后,我们以特定方式删除和缩放边缘,以便恢复对基础对象数量的估计。
我们的总体策略是主要针对完全重叠或完全不同的完美注意图和边界框的不现实极端情况设计组件。通过引入一些参数并且仅使用可微分的运算,我们使模块能够在这些极端情况下的正确行为之间进行插值,以处理更实际的情况。
这些参数负责以适合给定数据集的方式处理注意力权重和部分边界框重叠的变化。为此,我们使用了几个分段线性函数f1,…。 。 。 ,f8作为激活函数(在附录A中定义),用域和范围[0,1]近似任意函数。学习了这些函数的形状,以处理处理重叠提案所必需的特定非线性相互作用。通过它们的参数化,我们强制fk(0)= 0,fk(1)= 1,并且它们是单调递增的。前两个属性是必需的,以便我们明确处理的极端情况保持不变。在这些情况下,fk仅应用于0或1的值,因此可以安全地忽略激活函数以了解组件如何处理它们。通过强制单调性,我们可以确保,例如,注意图中的增加值永远不会导致计数减少的预测。
4.1 INPUT
给定对象提案的一组功能,注意力机制会根据问题为每个提案产生权重。计数组件将n个最大关注权重a = [a1,…,an] T及其对应的边界框b = [b1,…,bn] T作为输入。我们假设权重位于区间[0,1]中,这可以通过应用逻辑函数轻松实现。
我们的两个假设
①:在我们明确处理过的极端情况下,我们假设当第i个提案包含相关对象时,注意力机制将为ai分配值为1,否则将其分配0。这与通常的软注意力机制所学的内容一致,因为它们会为相关输入产生更高的权重。
②:我们还假设两个对象建议完全重叠(fully Overlap)(在这种情况下,它们必须显示相同的对象,因此获得相同的注意力权重),或者它们完全不同(fully distinct)(在这种情况下,它们显示不同的对象)。
请记住,尽管我们进行这些假设以使行为的推理更容易,但是在不应用假设的情况下,激活函数中的学习参数旨在处理更现实的情况。
现在,问题不再是部分重叠(partially overlapping)提案,而是变成以可区分的方式处理基础对象的精确重复(extract duplicate)提案。
4.2 Deduplication
我们首先将注意力权重向量a转换为更容易利用边界框的图形表示。因此,我们计算注意权值的外积,得到注意矩阵
A ∈ R n × n A ∈R^{n×n} A∈Rn×n可解释为加权有向图的邻接矩阵。在这个图中,第i个顶点表示与ai相关的对象建议,并且任意一对顶点(i,j)之间的边的权值为 a i a j a_ia_j aiaj。在 a i a_i ai实际上为0或1的极端情况下,products等同于逻辑和操作符。由此可以得出,只包含满足 a i = 1 a_i = 1 ai=1的顶点的子图是一个具有自循环的完全有向图。

例如:[a1,a2,a3,a4,a5]=[1,0,1,0,1]则包含a1,a3,或者a5的子图是一个完全有向图,如下:
A = [ a 1 , a 2 , a 3 , a 4 , a 5 ] T [ a 1 , a 2 , a 3 , a 4 , a 5 ] = ( 1 0 1 0 1 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 1 0 1 0 1 ) \boldsymbol{A} =[a_1,a_2,a_3,a_4,a_5]^T[a_1,a_2,a_3,a_4,a_5] = \left( \begin{array}{cccc} 1 & 0 &1 & 0 & 1\\ 0 & 0 & 0 & 0 & 0 \\ 1 & 0 &1 & 0 & 1\\ 0 & 0 & 0 & 0 & 0 \\ 1 & 0 &1 & 0 & 1\\ \end{array} \right) A=[a1,a2,a3,a4,a5]T[a1,a2,a3,a4,a5]=⎝⎜⎜⎜⎜⎛1010100000101010000010101⎠⎟⎟⎟⎟⎞
对应的图如下:
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第2张图片](http://img.e-com-net.com/image/info8/73e631580c2f411c848d4c497a97350b.jpg)
在这个表示中,我们的目标是消除边,在概念上,潜在的真实对象(而不是提议对象)是完整子图的顶点。
为了将这个图转换成一个计数,回想一下,在一个带有自循环的完整有向图中,边的数量 ∣ E ∣ |E| ∣E∣与顶点的数量 ∣ V ∣ |V| ∣V∣有关—— ∣ E ∣ = ∣ V ∣ 2 |E| = |V|^2 ∣E∣=∣V∣2。 ∣ E ∣ |E| ∣E∣可以通过对邻接矩阵中的项求和来计算(sum(A) = 9), ∣ V ∣ |V| ∣V∣就是这个计数。
注意: 当 ∣ E ∣ |E| ∣E∣被设为 A A A的和时, ∣ E ∣ \sqrt{|E|} ∣E∣ = ∑ i a i \sum_ia_i ∑iai=(a1+a2+a3+a4+a5=3)成立。这个方便的属性意味着,当所有建议都完全不同时,组件可以输出与默认情况下简单地对原始注意权重求和相同的结果(当边的数量等于A的和时,其实A就是01矩阵,和的数就是原始注意权重列表中1的个数,就是原始注意权重求和的结果)
为了实现我们的目标,需要消除两种类型的重复边缘:对象内边缘和对象间边缘(意思是消除自循环的边和两顶点间的重复边?)
4.2.1 Intra-object edges
第一步:首先,我们消除了单个底层对象的重复建议之间的对象内边缘。
为了比较两个边界框,我们使用通常的相交-合并(IoU)度量。我们定义距离矩阵 D ∈ R n × n D∈R^{n×n} D∈Rn×n为
D D D也可以解释为一个邻接矩阵。它表示一个到处都有边的图,除非边连接的两个边界框会重叠

通过将距离矩阵与注意力矩阵逐元素相乘,可以删除对象内边缘(如图2)
图2:通过用距离矩阵 D D D掩蔽注意矩阵 A A A的边来去除对象内边缘(intra-object edges)。黑顶点现在形成了一个没有自循环的图。这个自循环需要在以后再加回来。
这个图中[a1,a2,a3,a4]=[1,1,1,0] A = [ a 1 , a 2 , a 3 , a 4 ] T [ a 1 , a 2 , a 3 , a 4 ] = ( 1 1 1 0 1 1 1 0 1 1 1 0 0 0 0 0 ) \boldsymbol{A} =[a_1,a_2,a_3,a_4]^T[a_1,a_2,a_3,a_4] = \left( \begin{array}{cccc} 1 & 1 &1 & 0 \\ 1 & 1 &1 & 0 \\ 1 & 1 &1 & 0 \\ 0 & 0 & 0 & 0 \\ \end{array} \right) A=[a1,a2,a3,a4]T[a1,a2,a3,a4]=⎝⎜⎜⎛1110111011100000⎠⎟⎟⎞
D = ( 0 1 1 1 1 0 0 1 1 0 0 1 1 1 1 0 ) \boldsymbol{D} = \left( \begin{array}{cccc} 0& 1 &1 & 1 \\ 1 &0 &0 & 1 \\ 1 &0 &0 &1 \\ 1 & 1 & 1 & 0 \\ \end{array} \right) D=⎝⎜⎜⎛0111100110011110⎠⎟⎟⎞
A ^ = A ∗ B = ( 0 1 1 0 1 0 0 0 1 0 0 0 0 0 0 0 ) \hat A = A*B= \left( \begin{array}{cccc} 0& 1 &1 & 0\\ 1 &0 &0 & 0\\ 1 &0 &0 &0 \\ 0 & 0& 0& 0 \\ \end{array} \right) A^=A∗B=⎝⎜⎜⎛0110100010000000⎠⎟⎟⎞
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第3张图片](http://img.e-com-net.com/image/info8/f9fb1cbe68504e918221862879b0ccf4.jpg)
A ^ \hat A A^不再有自循环了,所以我们需要在后面把它们加回来以满足 ∣ E ∣ = ∣ V ∣ 2 |E| = |V|^2 ∣E∣=∣V∣2。请注意,我们开始使用前面提到的激活函数来处理 A A A和 d d d的区间(0,1)中的中间值。它们调节了不接近于0或1的注意力权重的影响以及部分重叠的影响
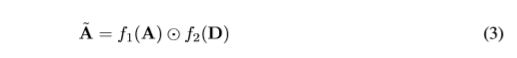
4.2.2 Inter-object edges
第二步:我们消除了不同底层(underlying)对象的重复建议之间的对象边界——对象间边缘
主要思想(如图3所示)是计算与每个单个对象相关联的投标的数量,然后按该数量缩小其相关边缘(与该顶点相连的顶点)的权重。如果一个对象有两个提议,则涉及这些提议的边应按0.5缩放()。本质上,这是对每个基础对象内的投标求平均值,因为我们仅使用边缘权重之和来计算最后的计数。从概念上讲,这可将一个对象的多个提议减少到所需的一个。由于我们不知道某个对象属于多少个提案,因此我们必须对此进行估算。我们通过使用相同对象的提议相似的事实来做到这一点。
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第4张图片](http://img.e-com-net.com/image/info8/1f0a764b6ffe42668dcc1bc09012ee00.jpg)
图3:删除重复inter-object边缘通过计算每个顶点的比例因子和扩展 A ^ ′ \hat A' A^′相应。 A ^ ′ \hat A' A^′是 A ^ \hat A A^自循环已经添加。一个顶点的比例因子是通过计算有多少顶点向外延伸到同一个顶点集;右边的两个建议的所有边都被缩放了0.5(由黑色变成灰色)。这可以看作是平均每个对象内的建议,相当于在一个总和下删除重复的建议。
请记住, A ^ \hat A A^在同一对象的建议之间没有自环或边。结果,当且仅当提议相同时, A ^ \hat A A^中的两个非零行相同。如果两行至少在一个条目中不同,则一个提案与另一个提案不重叠的提案重叠,因此它们必须是不同的提案
这意味着,为了比较行,我们需要一个相似度函数,该函数满足以下条件:当行与行没有任何差异时,取值为1;如果行与行至少有一处不同,取值为0。我们定义了建议i和j之间可微的相似性
其中:
与 A ^ \hat A A^相同,除了具有不同的激活函数。
比较提案i与j的行,在初始实验中,此术语代替
对于不准确的边界框更具有鲁棒性
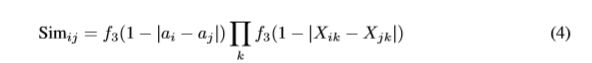
请注意,当只有一个提议要计数时, f 3 ( 1 − ∣ a i − a j ∣ ) f_3(1- |a_i -a_j| ) f3(1−∣ai−aj∣)项处理边缘情况。由于 X X X没有自环,因此在这种情况下 X X X仅包含零,这导致与 a i = 1 a_i = 1 ai=1对应的行与 a j ! = i = 0 a_{j != i} = 0 aj!=i=0的行错误地相似。通过比较该术语的注意力权重。
现在,我们可以检查两个提议的相似程度,计算任何行与任何其他行相同的次数,并为每个顶点 i i i计算比例因子 s i s_i si
计算的时间复杂度 s = [ s 1 , . . . , s n ] T s = [s_1,...,s_n ]^T s=[s1,...,sn]T是 Θ ( n 3 ) Θ(n^3) Θ(n3),由于有 n 2 n^2 n2行对和 Θ ( n ) Θ(n) Θ(n)操作来计算任何一对行的相似度,

由于这些缩放因子适用于每个顶点,因此我们必须使用来将 s s s扩展为矩阵外部乘积,以便缩放每个顶点的传入和传出边缘。我们还可以重新添加自环,也需要按 s s s进行缩放。然后,计数矩阵 C C C为
其中diag(·)将一个向量展开成一个对角矩阵,该向量在对角上

自循环的缩放涉及到一个不明显的细节,回想一下被删除的对角线,当从 A A A到 A ^ \hat A A^时,包含条目 f 1 ( a 点 乘 a ) f_1(a点乘 a) f1(a点乘a)。但是请注意,我们将对角线缩放为s而不是 ( s 点 乘 s ) (s点乘s) (s点乘s)。
这是因为对象间边缘的数量与每个对象的建议数量成二次关系,而自循环的数量仅成线性关系
4.3 Output
在总和的作用下,C现在相当于一个包含所有相关对象的自循环的完整图,而不是像最初期望的那样包含相关建议
为了把 C C C变成一个计数 c c c,我们设 ∣ E ∣ = ∑ i , j C i j |E| =\sum_{i,j}C_{ij} ∣E∣=∑i,jCij如前所述,然后
我们通过实验证明,当我们的极端情况假设成立时, c c c始终是一个整数,等于正确的计数,而不管重复的对象提议的数量

为了避免在对象数量较大时出现伸缩性问题,我们将这个单一特性转换为几个类,每个类对应一个可能的数量。因为我们只使用具有最大n个权值的对象建议,所以预测的计数c最多可以是 n n n。我们定义输出为 o = [ o 1 , . . . , o n ] T o = [o_1,...,o_n]^T o=[o1,...,on]T
如下:
当 c c c是一个整数时,这会导致一个向量在计数的索引处为1,其他地方为0,并且当计数落在两个整数之间时,两个对应的单热向量之间有一个线性插值。

4.3.1 Output Confidence
最后,我们可以考虑用接近0或接近1的 a a a和 D D D的值进行预测,这样会比很多接近0.5的值更可靠——毕竟我们是显式地处理这些值的。为了体现这一思想,我们在区间[0,1]中用置信值对 o o o进行标度。
我们定义 p a p_a pa和 p D p_D pD是到0.5的平均距离。选择0.5并不重要,因为模块可以通过更改 f 6 ( x ) = 0.5 和 f 7 ( x ) = 0.5 f_6(x) = 0.5和f_7(x) = 0.5 f6(x)=0.5和f7(x)=0.5来更改它
则置信度缩放分量的输出为:
总之,我们只使用可扩散的操作来删除对象建议,并获得代表预测计数的特征向量。这样就可以很容易地集成到任何具有软注意力的模型中,使模型能够从注意力图中计数。
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第5张图片](http://img.e-com-net.com/image/info8/188a814198be4e709453501bb81bae6d.jpg)
5. 实验
5.1 Toy task
首先,我们设计一个简单的玩具任务来评估计数能力。该数据集仅用于评估计数的性能。因此,我们将跳过任何不直接相关的处理步骤,例如输入图像的处理。附录D中给出了来自此数据集的样本。分类任务是根据一组边界框和相关的关注权重来预测真实对象的整数计数 c ^ \hat c c^,该对象均匀地绘制为0到10(含0和10)。将10个边长为 l ∈ ( 0 , 1 ] l∈(0,1] l∈(0,1]的正方形边界框放置在边长为单位的正方形图像中,从 U ( 0 , 1 − l ) U(0,1- l) U(0,1−l)均匀绘制其左上角的x和y坐标,以使这些框l用于控制边界框的重叠:较大的 l l l导致固定数量的对象被更紧密地包装,从而增加了重叠的机会。是真正的边界框。边界框的分数是它与任何真实边界框的最大 I o U IoU IoU重叠。然后,注意力权重是分数和从 U ( 0 , 1 ) U(0,1) U(0,1)得出的噪声值之间的线性插值,其中 q ∈ [ 0 , 1 ] q∈[0,1] q∈[0,1]控制权衡取舍q是注意力噪声参数:当q为0时,没有噪声,当q为1时,没有信号;增大q也会间接模拟边界框的不精确放置我们将计数组件与简单的基线进行比较,该基线简单地将注意力总和对权重进行求和,然后使用公式8将总和转换为特征向量。这两个模型之后都进行了线性投影,投影到0至10级(含0和10)以及softmax激活。他们使用Adam(Kingma&Ba,2015)进行了1000次迭代的交叉熵损失训练,学习率为0.01,批处理大小为1024。
图4中显示了在将q固定为各种值的同时改变l的结果,反之亦然。无论l和q如何,在大多数情况下,计数组件的性能都比基线好,通常情况下明显如此。特别是当噪声低时,该组件可以非常成功地处理l的高值,这表明它实现了对重叠提案提高鲁棒性的目标。只要重叠部分受到限制,该组件还可以适当地处理中等噪声水平。当l和q都很高时,性能与基线紧密匹配,这可能是由于这些参数设置的难度很高,因此几乎没有信息可以提取
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第6张图片](http://img.e-com-net.com/image/info8/3c8ca64b14304b7fb3f5bc05025bf2ef.jpg)
我们还可以查看激活函数本身的形状(如图5和附录C所示),以了解行为随数据集参数的变化如何变化。为简单起见,我们将描述限制在两个最容易解释的函数上f1表示注意力权重,f2表示边界框距离。
当增加边长时,f1的“台阶”高度降低以补偿通常更大的程度重叠的边界框。
对于f2可以看到类似的效果:当l较低时-需要部分成对的距离–当部分重叠很有可能是伪造时–会考虑变化,并且考虑到l较高时建议将其视为不同的足够小的距离。
在l的最大值处,由于所有事物都与所有事物重叠,因此在剩余的重叠中几乎没有信号,这解释了为什么f2返回这些参数的默认线性初始化。
当改变噪声量时,无噪声f1类似于阶跃函数,其中阶跃开始时接近x = 1,并且在阶跃之后取接近1的值。由于在没有噪音的情况下,一个真实的建议将始终具有1的权重,
因此可以安全地将任何低于此建议的零归零。随着噪声的增加,x和f1(x)的这一步都远离1,从而在边界框属于真实对象时捕获不确定性。对于较低的q,f2认为一对建议对于较低的距离是不同的,而对于较高的q,f2遵循更呈S形的形状。可以通过模型来解释这一点,该模型通过要求更长的距离才能将提案视为完全不同,从而将精确的边界框放置的不确定性考虑在内。
图5:对于数据集中变化的边界框边长(左)或噪声(右),经过训练的激活函数f1(注意权重)和f2(边界框距离)的形状在0.01步长中变化。最佳彩色观看效果
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第7张图片](http://img.e-com-net.com/image/info8/7d318bca192b4e6f96cf70763588a0db.jpg)
5.1.1 Results
5.2 VQA
VQA v2 (Goyal et al., 2017)是VQA v1数据集(Antol et al., 2015)的更新版本,该数据集更加注意通过平衡对来减少数据集的偏差:对于每个问题,将识别出该问题答案不同的一对图像。这个数据集上的标准精度度量通过对所有10个选择-9个人类答案子集的min(1/3agreeing,1)进行平均来解释人类答案中的分歧,其中同意是人类回答中同意给定答案的数量。这可以证明等于min(0.3同意,1)没有平均。
我们使用了Kazemi & Elqursh(2017)的强VQA基线的改进版本作为基线模型(详见附录B)。我们没有对该基线进行任何调整,以最大限度地提高它与计数模块基线之间的性能差异。为了用计数组件来扩充这个模型,我们在softmax归一化之前提取第一次注意瞥见(基线中有两个)的注意权重,然后将它们输入到计数组件中运用logistic函数。由于Anderson等人(2017)的对象建议特征从每幅图像10到100不等,使用的top-n建议的数量自然是10。组件的输出被线性投影到分类器的隐含层的同一空间,然后再进行ReLU激活,批量归一化,加上隐含层的特征
5.2.1 Results
表1,在官方的VQA v2排行榜上显示结果。与基线结果相比,我们的组件的基线在数字问题上具有明显更高的准确性,而不会影响其他类别的准确性。尽管我们的单模型基线大大低于最先进的水平,但通过简单地添加计数成分,我们在数字类别上甚至优于Zhou等人(2017)的8模型集合。我们期待在加入他们的技术来提高注意力权重的质量时,数字的准确性会有进一步的提高,特别是在目前最先进的模型遭受我们在第3节中提到的计数问题的时候。在附录E中显示了一些计数组件中的输入和激活的定性例子。
表1:主要模型的VQAv2结果及我们的结果。标记为(en .)的条目是模型的集合。在本文写作时,我们的带有计数模块的模型在所有条目中排名第三。这里列出的所有模型都使用了对象建议特性,并在训练集和验证集上进行了训练。性能最好的集成模型使用额外的预先训练过的单词嵌入,而我们并不使用。
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第8张图片](http://img.e-com-net.com/image/info8/9a3283376e434ac6acaf9bfefdd066b5.jpg)
我们还在表2所示的VQA v2验证集上评估了我们的模型。这使我们仅考虑数字问题中的计数问题,因为数字问题包括诸如“几点了?”之类的问题。也一样我们将以“多少”开头的任何问题视为计数问题。正如我们预期的那样,在计数问题子集上使用计数模块的好处通常要比在数量问题上更高。此外,我们尝试一种方法,我们将注意力模块的平均值作为评分,然后通过单次编码剩余的提案数量,简单地用NMS替换计数模块。基于NMS的方法使用的IoU阈值为0.5,并且没有基于验证集性能的评分阈值,在基线上不会有所改善,这表明NMS的分段梯度是学习VQA计数的主要问题,反之,能够通过计数模块进行区分有很大的好处。
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第9张图片](http://img.e-com-net.com/image/info8/f814e40746b7474a8f35592ac1693e44.jpg)
此外,正如Teney等人(2017)所提出的,我们可以评估相对于平衡对的准确度:两个问题的VQA准确度均为1.0的平衡对的比率。这是一个更加困难的度量,因为它需要模型找到图像之间的微妙细节,而不是依赖于数据集中的问题偏差。首先,注意到所有平衡对的精度与它们各自的VQA精度相比是如何大大降低的。更重要的是,计数模块的绝对精度改进仍然充分体现在更具挑战性的度量上,这进一步证明了该组件可以正确地计数,而不是简单地拟合数据集的偏差。
在查看训练模型的激活函数时,如图9所示,我们发现它们的一些特征与玩具数据集的高噪声参数化是相同的。这表明,目前的注意机制和对象建议网络仍然非常不准确,这解释了可能是小的增加的表现。这提供了进一步的证据,表明相对于目前70%以上的顶级模型的整体VQA精度,平衡配对精度可能是更能反映当前VQA模型表现如何的衡量标准
6.总结
在了解了为什么VQA模型难以计数时,我们设计了一个计数组件,该组件通过可区分的边界框重复数据删除来缓解此问题。只要该组件仍像VQA v2上所有当前的顶级模型那样继续受到关注,就可以轻松地将该组件与VQA模型中的任何将来改进一起使用。它也可以在VQA之外使用:对于许多计数任务,只要有按建议的计分方式(例如学会使用),它就可以使基于对象建议的方法在没有地面真实对象的情况下工作。分类分数)和一对提案有多不同的概念。由于组件中的每个步骤都有明确的用途和解释,因此激活功能的学习权重也是可以解释的。计数组件的设计是一个示例,展示了如何通过将归纳偏差编码到深度学习模型中,在只有相对较少的监管信息的情况下如何解决诸如对任意对象进行计数之类的挑战性问题。请注意,VQA v2需要当前模型所没有的通用技能。为了在该数据集上取得进展,我们提倡着重于了解模型当前的缺点,并找到减轻这些缺点的方法。
7.附录
附录A
附录A:

附录B
附录B:
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第10张图片](http://img.e-com-net.com/image/info8/be395c1ef9c840fe94c572a02e258ce4.jpg)
附录C
附录C:
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第11张图片](http://img.e-com-net.com/image/info8/d88fac1903a744aa8a288c942826db9b.jpg)
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第12张图片](http://img.e-com-net.com/image/info8/a83311f5c0584e51bb47502f68491d46.jpg)
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第13张图片](http://img.e-com-net.com/image/info8/9fcf3eba06e1407f94c44d69b924d90e.jpg)
附录D
附录D:
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第14张图片](http://img.e-com-net.com/image/info8/05cf64e300aa47d3a7d971c75ba9ff9d.jpg)
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第15张图片](http://img.e-com-net.com/image/info8/aafc483d24b04eaaabc34e4ebb35b29f.jpg)
附录E:
附录E:
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第16张图片](http://img.e-com-net.com/image/info8/c1d6f98ae9ce4d0086ea23f0f02c5c23.jpg)
![[论文阅读笔记]:LEARNING TO COUNT OBJECTS IN NATURAL IMAGES FOR VISUAL QUESTION ANSWERING_第17张图片](http://img.e-com-net.com/image/info8/cb424006e251453da9898906050a3e19.jpg)