模式识别作业--人脸识别(python+PCA+pytorch神经网络)
模式识别作业–人脸识别(python+PCA+pytorch)
1、实验原理
该实验通过PCA降维+BP神经网络的算法实现对人脸数据集中人脸数据的识别
2、实验步骤
1、图片预处理
首先将测试集和训练集图片转化为灰度图,为了减少背景对实验结果的影响,使用OpenCV中继承好的CascadeClassifier级联分类器从原始的灰度图中识别并将人脸切取出来并保存。由于人脸的不规则性所以切取出来的人脸数据图片的大小并不一致,所以将图片reshape为200×200的像素大小。
2、PCA降维
经过预处理后的图片已经有统一的格式,都有200×200个像素,即40000个特征,我们的目标是通过PCA算法建立映射空间将原始数据映射到低维空间中从而实现对初始数据的降维,并保存降维后的训练数据和测试数据,便于后期神经网络的分类运算,步骤如下:
1、设有n训练集中的图片,每张训练集图片的像素为c=a×b(200×200)
2、将每张图片的ab矩阵转换c维列向量的形式构成n列的矩阵X(c×n)
3、对矩阵X进行均值、中心化操作、并求得协方差矩阵
4、求取协方差矩阵的特征值并取k个特征值(k:取值于使累计贡献率>90%的特征值数量)所对应的特征向量V(特征脸)。
5、将K个特征向量合并成特征空间T(c×k)
6、将原始数据矩阵投射到该特征空间得到降维矩阵。
3、BP神经网络实现对图像的分类
使用pytorch框架构建神经网络,并进行训练分类,步骤如下:
1、重写Getloader类,使用Dataloader迭代器处理训练数据和测试数据,构建用于模型训练和测试的数据结构,便于后期的使用和扩展。
2、构建一个k×200×350×500×625的神经网络。(k为将为后的图片的特征数,即输入神经元的个数,200、300、500为隐藏层的神经元个数,625为输出神 经元的个数)
3、用训练数据训练模型。
4、用测试训练集的数据进行分类并计算分类的准确性。
3、实验过程详解
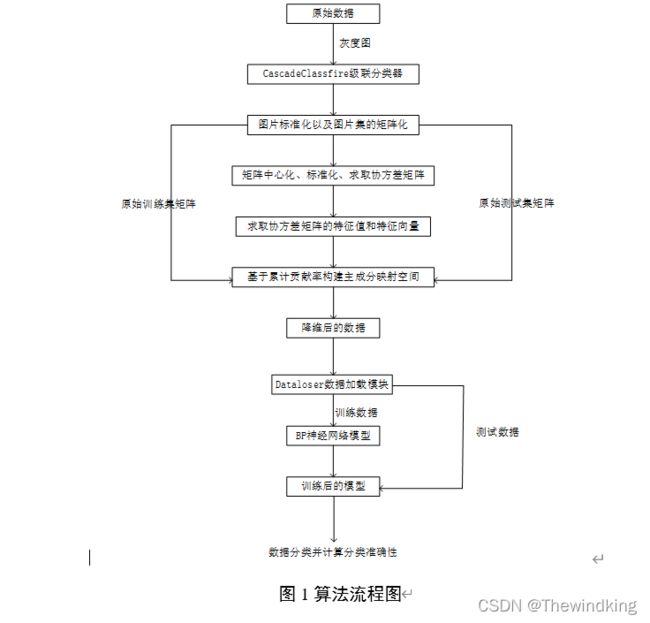
1、人脸识别的基本流程
2、读入数据库并剪切人脸
main.py
# 该程序用于剪切人脸,并存储为灰度图
import os
import cv2
import time
def getAllPath(dirpath, *suffix):
PathArray = []
for r, ds, fs in os.walk(dirpath):
for fn in fs:
if os.path.splitext(fn)[1] in suffix:
fname = os.path.join(r, fn)
PathArray.append(fname)
return PathArray
# 从源路径中读取所有图片放入一个list,然后逐一进行检查,把其中的脸扣下来,存储到目标路径中
def readPicSaveFace(sourcePath, targetPath, *suffix):
try:
ImagePaths = getAllPath(sourcePath, *suffix)
# 对list中图片逐一进行检查,找出其中的人脸然后写到目标文件夹下
count = 1
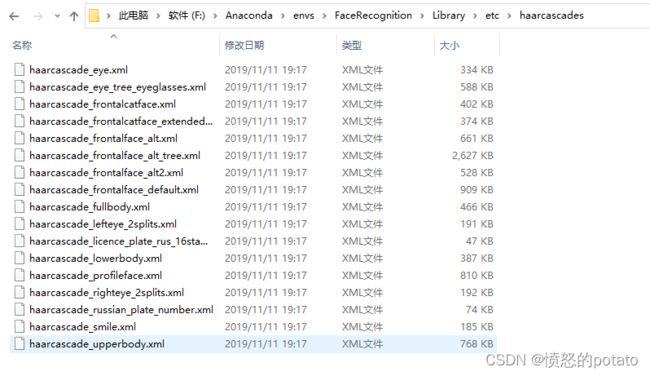
# haarcascade_frontalface_alt2.xml为库训练好的分类器文件,下载opencv,安装目录中可找到
path = "haarcascade_frontalface_alt2.xml" # 级联分类器的地址,换成自己的
face_cascade = cv2.CascadeClassifier(path)
for imagePath in ImagePaths:
# 读灰度图,减少计算
filename = os.path.split(imagePath)[1]
img = cv2.imread(imagePath, cv2.IMREAD_GRAYSCALE)
if type(img) != str:
faces = face_cascade.detectMultiScale(img)
# (x, y)代表人脸区域左上角坐标;
# w代表人脸区域的宽度(width);
# h代表人脸区域的高度(height)。
for (x, y, w, h) in faces:
# 设置人脸宽度大于128像素,去除较小的人脸
if w >= 128 and h >= 128:
# 扩大图片,可根据坐标调整
X = int(x)
Y = int(y)
W = min(int((x + w)), img.shape[1])
H = min(int((y + h)), img.shape[0])
f = cv2.resize(img[Y:H, X:W], (W - X, H - Y))
f = cv2.resize(f, (200, 200))
cv2.imwrite(targetPath + os.sep + filename, f)
count += 1
except IOError:
print("Error")
#当try块没有出现异常的时候执行
else:
print('Find ' + str(count - 1) + ' faces to Destination ' + targetPath)
if __name__ == '__main__':
start = time.time()
sourcePath = r'G:\FaceRcogImg\TrainSourceImg'# 原始训练数据文件地址,换成自己的
targetPath = r'G:\FaceRcogImg\TrainFaceData'# 处理后的训练图片的文件存储地址
readPicSaveFace(sourcePath, targetPath, '.jpg', '.JPG', 'png', 'PNG')
sourcePath = r'G:\FaceRcogImg\TestSourceImg'# 原始测试数据文件地址,换成自己的
targetPath = r'G:\FaceRcogImg\TestFaceData'# 处理后的测试图片的文件存储地址
readPicSaveFace(sourcePath, targetPath, '.jpg', '.JPG', 'png', 'PNG')
end = time.time()
print('程序运行时间是:{}'.format(end-start))
此程序用于将原始图片进行人脸剪切并将其图片大小标准化为200×200的像素大小的格式。该过程耗时较长,大概需要10分钟左右。(图5是成程序运行成果)剪切的结果如下图所示。

原始数据

处理后的照片
由于采用级联分类器进行剪切,会不可避免的出现下图的干扰结果,但是在所有的处理后的图像中该种类的图像个数很少,并不会影响最终的实验结果,这里我们忽略其对实验的影响(或者可以手动删除)。

3、pca特征提取
首先我们要先将图片集转换为矩阵形式
ImgPaths, label = getAllPath(sourcePath, *suffix)
imageMatrix = []
count = 0
for imgpath in ImgPaths:
count += 1
img = cv2.imread(imgpath, cv2.IMREAD_GRAYSCALE)
# 灰度图矩阵
mats = np.array(img)
# 将灰度矩阵转换为向量
imageMatrix.append(mats.ravel())
imageMatrix = np.array(imageMatrix)# imageMatrix是图片矩阵;n X 40000 ,n为图片个数
接着按行求图片矩阵的均值,即这个训练集的平均脸,
# 矩阵转置后每一列都是一个图像,40000 X n,对行求均值
imageMatrix = np.transpose(imageMatrix)
imageMatrix = np.mat(imageMatrix)
# 原始矩阵的行均值
mean_img = np.mean(imageMatrix, axis=1)
# 此处用于显示平均脸,如果想要存储到本地,可以自主添加文件存储代码
mean_img1 = np.reshape(mean_img, IMAGE_SIZE)
im = Image.fromarray(np.uint8(mean_img1))
im.show()
平均脸图片如下图所示

4、计算协方差矩阵和特征向量
此处我们将样本中心化之后(减去平均脸)
# 均值中心化
imageMatrix = imageMatrix - mean_img
# W是特征向量, V是特征向量组 (3458 X 3458)
imag_mat = (imageMatrix.T * imageMatrix) / float(count)
W, V = np.linalg.eig(imag_mat)
# V_img是协方差矩阵的特征向量组
V_img = imageMatrix * V
此处需要介绍一下求取协方差矩阵和特征向量的取巧之处,按照协方差矩阵公式,
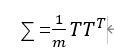
可知协方差矩阵的维度为40000 X 40000,这意味着求取协方差的特征值和特征向量的运算量会很大,我自己电脑上会超出内存。所以我们进行一些转化,推导如下图所示。

所以我们先求取![]()
的特征向量,然后根据上面的推导求出协方差的特征向量。这大大减少了建立投影子空间的运算量。
下面是按照对应特征值降序排序后所得的部分特征脸的图片






我们可以发现前面三张特征脸看上去要比后面三张特征脸“清楚”得多,也就是说前三张特征脸所包含的“信息”要比后三张所包含的“信息”多。其实这是由于这些特征向量对应的特征值的大小不同造成的,特征值越大,则人脸越“清晰”。
5、选取部分特征值
从前面我们知道有些特征脸所携带的“信息”十分少,那么我们可以将所得到的所有特征脸按照特征值的大小排序,选取累计贡献值大于90%的前k个特征脸,这样一来在尽可能小的影响模型精度的情况下对特征空间降维。
# 降序排序后的索引值
axis = W.argsort()[::-1]
V_img = V_img[:, axis]
number = 0
x = sum(W)
for i in range(len(axis)):
number += W[axis[i]]
if float(number) / x > 0.9:# 取累加有效值为0.9
print('累加有效值是:', i) # 前62个特征值保存大部分特征信息
break
# 取前62个最大特征值对应的特征向量,组成映射矩阵
V_img_finall = V_img[:, :62]
最后的结果是前62 个特征脸可以保留90%的人脸信息,这62个特征向量就构成了我们需要的特征空间,所以降维后的人脸信息维度是62。
我们将降维后的测试集和训练集图片信息保存为.csv文件,便于后续神经网络分类
# 降维后的训练样本空间
projectedImage = V_img_finall.T * train_imageMatrix
np.savetxt('pca_train_matrix.csv', projectedImage, delimiter=',')
6、BP神经网络分类
此处构建的是很简单的BP神经网络,不再详细赘述,可以看代码中的注释,写的还是很详细的。其他的主要是重写了GetLoader类方法,用于多线程的处理训练数据,用以加速伸进网络的训练时间。
# 定义GetLoader类,继承Dataset方法,并重写__getitem__()和__len__()方法
class GetLoader(torch.utils.data.Dataset):
# 初始化函数,得到数据
def __init__(self, data_root, data_label):
self.data = data_root
self.label = data_label
# index是根据batchsize划分数据后得到的索引,最后将data和对应的labels进行一起返回
def __getitem__(self, index):
data = self.data[index]
labels = self.label[index]
return data, labels
# 该函数返回数据大小长度,目的是DataLoader方便划分,如果不知道大小,DataLoader会一脸懵逼
def __len__(self):
return len(self.data)
train_set_ = GetLoader(train_set, train_lable)
test_set_ = GetLoader(test_set, test_lable)
train_data = DataLoader(train_set_, batch_size=64, shuffle=True) # 训练数据
test_data = DataLoader(test_set_, batch_size=32, shuffle=False) # 测试数据
4、实验结果
最终识别的准确率为94%左右。

代码下载地址
数据下载地址提取码: 6pn5
5、写在最后
最好将main函数中用到的级联分类器haarcascade_frontalface_alt2.xml改成自己环境的安装目录中的,如下图所示(我是用anaconda配置的环境)