GAN的训练技巧提升(WGAN、LSGAN、EBGAN、WGAN—GP算法)附代码
GAN的训练技巧提升(WGAN、LSGAN、EBGAN、WGAN—GP算法)附代码
- 生成对抗网络的几个问题描述
-
- 什么是信息熵?
- 计算信息熵
- 对抗网络损失函数
- Least Squares GAN(LSGAN)
-
- JS散度问题——不可度量
- Wasserstein GAN(WGAN)
- WGAN推土距离
- 寻找最佳铲土策略
- 平滑度量
- WGAN损失函数
- 权重裁剪
- Improved GAN(WGAN—GP)
-
- WGAN—GP的损失函数
- WGAN—GP约束惩罚
- WGAN算法步骤
- EBGAN
-
- 自动编码器介绍
- EBGAN网络结构
- 主要网络模块代码编写
-
- 初始化判别器代码
- 初始化生成器代码
- 初始化训练方法关键代码
-
- DCGAN损失函数初始化代码
- LSGAN损失函数初始化代码
- WGAN损失函数初始化代码
- WGAN—GP损失函数初始化代码
- 训练结果
-
- LSGAN
- WGAN
- WGAN—GP
- 总结
- 参考文献
- 其他
生成对抗网络的几个问题描述
什么是信息熵?
我们用熵来度量数据是有序还是无序的

计算信息熵
信息熵是度量系统混乱程度的量:
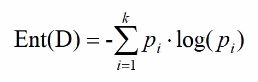
其中Pi表示某事件发生的概率,信息熵最小是0,表示完全确定,最大为log(概率为1),表示所有情况等可能发生(完全无序)
对抗网络损失函数
![]()
最佳判别器的公式如下
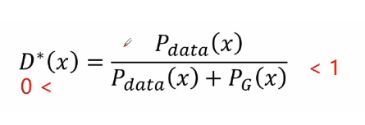
将D*(x)带入交叉熵损失函数中可得JS散度(具体推导过程可见第一篇关于GAN的博客):
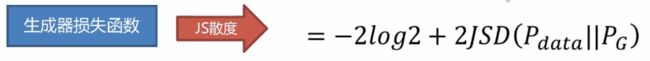
Least Squares GAN(LSGAN)

通过原始论文摘要我们可以提取出以下关键信息:
前面的研究已经证明GAN网络非常的好,对于普通的GAN网络,判别器作为一个分类器使用的是一个Sigmoid激活函数进行交叉熵损失函数这样一个关系。作者发现这种损失函数可能会导致梯度消失这样一个问题,为了克服这种问题,我们使用最小均方误差损失函数去替代交叉熵损失函数去进行研究。
综上所述:LSGAN的任务就是用线性激活函数代替Sigmoid激活函数(回归任务代替分类任务)
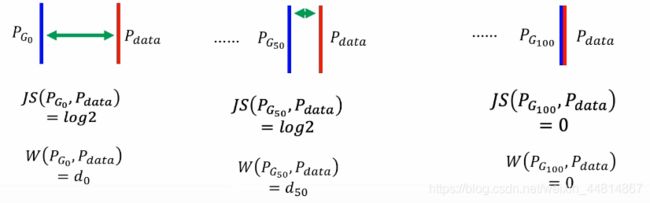
JS散度问题——不可度量
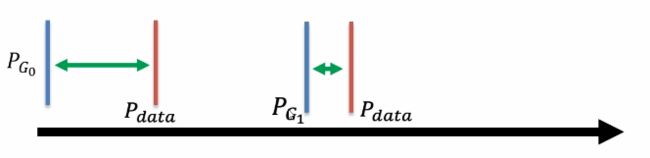
生成数据跟真实数据之间,使用JS散度去度量这两个数据之间的距离,但是无论这两个距离是什么情况,只要不重叠,JS散度一直都是Log2,只有当这两个数据重合的时候,JS散度才为0。很显然当这两个分布不重叠的时候,二分类正确率却一直为100%,没有办法区别一个好的程度这样一个过程,所以这样就显得没有实际意义。
Wasserstein GAN(WGAN)
Earth Mover“s Distance(推土距离):
假设分布p是一块土,另外一个分布Q是目标。推土距离就是将一块土p推到Q的平均距离。
WGAN推土距离

寻找最佳铲土策略

一个”移动计划“是一个矩阵,矩阵中每个元素是从一个位置移动到另一个位置的量.

推土距离:穷举所有Π,选出最小的γ作为最优策略
平滑度量
对于JS散度描述数据分布之间的距离,这里我们用推土机距离去度量得到以下更好更平滑的一个度量效果
WGAN损失函数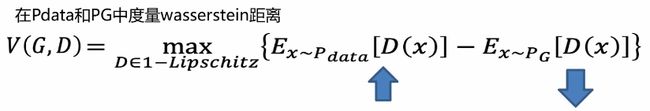
在WGAN中,判别器不需要标记为0和1,只需要对于真实数据,D(x)尽量输出正数,对于伪造数据尽可能的输出负数即可。且判别器D必须平滑约束,如果没有约束的话,判别器D训练将无法收敛。那么如何实现这项约束?
权重裁剪
平滑约束的实现的条件:

对于上节所提出的问题,其实就是梯度不要过大限制,采用权重裁剪这样一个方案。

Improved GAN(WGAN—GP)

对于WGAN—GP原始论文摘要的阅读我们可得到以下关键信息:
WGAN进一步提升了训练的稳定程度,但是仍然会产生一些低质量的数据或在某些设置中出现错误的收敛。这篇文章的作者发现是因为经常使用权重裁剪这种方法可能会导致一些错误的问题,因此作者提出惩罚梯度标准差这种方法替代权重裁剪来达到一个更好的效果。
WGAN—GP的损失函数
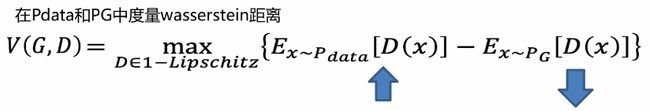

总之将这个约束加到总的损失函数中,这样一个惩罚项称之为梯度惩罚如下:
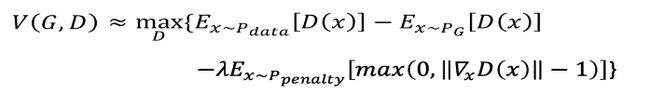
WGAN—GP约束惩罚

对于真实数据跟生成数据两个分布之间连线,取其平均值可作为约束的数据,只有对真实数据和生成数据之间的区域的分布给予梯度约束,该区域才能影响Pg如何影响到Pdata。一步一步的移动,不断取平均值不停移动这样一个过程,那么这一段区域的数据就称为惩罚数据。该区域的最大梯度等于1即可,相关实验证明该方法收敛更快且更优秀,
WGAN算法步骤

EBGAN
自动编码器介绍
自动编码器可以理解为这样一个对称的结构
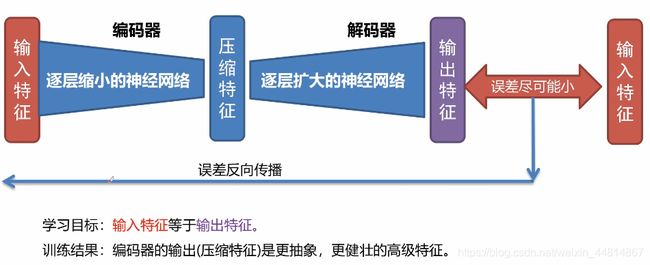
EBGAN网络结构
如果一个图片能够被重构的越好,那么他的质量就越高。在EBGAN中,使用自动编码器最为判别器D。生成器的网络结构不变,对于判别器,输入是一个真实的图像经过自动编码器进行训练,可以通过构造损失取确定图片的好坏,优点就是只通过真实图片进行预训练,不需要生成器。不像传统的GAN训练,不需要生成器跟判别器相互作用去判别一个二分类问题。对于EBGAN已经对真是数据进行了一个压缩重构,然后使用生成器的数据放到判别器中根据损失就可以判别生成数据的效果怎么样。
主要网络模块代码编写
初始化判别器代码
初始化判别器代码:
def _init_discriminator(self, input, isTrain=True, reuse=False):
"""
初始化判别器
:param input:输入数据op
:param isTrain: 是否训练状态
:param reuse: 是否可复用变量
:return: 判断op
"""
with tf.variable_scope('discriminator', reuse=reuse):
# hidden layer 1 input =[none,64,64,3]
conv1 = tf.layers.conv2d(input, 32, [3, 3], strides=(2, 2), padding='same') # [none,32,32,32]
bn1 = tf.layers.batch_normalization(conv1, training=isTrain)
active1 = tf.nn.leaky_relu(bn1) # [none,32,32,32]
# hidden 2
conv2 = tf.layers.conv2d(active1, 64, [3, 3], strides=(2, 2), padding='same') # [none,16,16,64]
bn2 = tf.layers.batch_normalization(conv2, training=isTrain)
active2 = tf.nn.leaky_relu(bn2) # [none,16,16,64]
# hidden 3
conv3 = tf.layers.conv2d(active2, 128, [3, 3], strides=(2, 2), padding="same") # [none,8,8,128]
bn3 = tf.layers.batch_normalization(conv3, training=isTrain)
active3 = tf.nn.leaky_relu(bn3) # [none,8,8,128]
# hidden 4
conv4 = tf.layers.conv2d(active3, 256, [3, 3], strides=(2, 2), padding="same") # [none,4,4,256]
bn4 = tf.layers.batch_normalization(conv4, training=isTrain)
active4 = tf.nn.leaky_relu(bn4) # [none,4,4,256]
# out layer
out_logis = tf.layers.conv2d(active4, 1, [4, 4], strides=(1, 1), padding='valid') # [none,1,1,1]
return out_logis
;
初始化生成器代码
初始化生成器代码:
// An highlighted block
def _init_generator(self, input, isTrain=True, reuse=False):
"""
初始化生成器
:param input:输入op
:param isTrain: 是否训练状态
:param reuse: 是否复用变量
:return: 生成数据op
"""
with tf.variable_scope('generator', reuse=reuse):
# input [none,1,noise_dim]
conv1 = tf.layers.conv2d_transpose(input, 512, [4, 4], strides=(1, 1), padding="valid") # [none,4,4,512]
bn1 = tf.layers.batch_normalization(conv1, training=isTrain)
active1 = tf.nn.leaky_relu(bn1) # [none,4,4,512]
# deconv layer 2
conv2 = tf.layers.conv2d_transpose(active1, 256, [3, 3], strides=(2, 2), padding="same") # [none,8,8,256]
bn2 = tf.layers.batch_normalization(conv2, training=isTrain)
active2 = tf.nn.leaky_relu(bn2) # [none,8,8,256]
# deconv layer 3
conv3 = tf.layers.conv2d_transpose(active2, 128, [3, 3], strides=(2, 2), padding="same") # [none,16,16,128]
bn3 = tf.layers.batch_normalization(conv3, training=isTrain)
active3 = tf.nn.leaky_relu(bn3) # [none,16,16,128]
# deconv layer 4
conv4 = tf.layers.conv2d_transpose(active3, 64, [3, 3], strides=(2, 2), padding="same") # [none,32,32,64]
bn4 = tf.layers.batch_normalization(conv4, training=isTrain)
active4 = tf.nn.leaky_relu(bn4) # [none,32,32,64]
# out layer
conv5 = tf.layers.conv2d_transpose(active4, 3, [3, 3], strides=(2, 2), padding="same") # [none,64,64,3]
out = tf.nn.tanh(conv5)
return out;
初始化训练方法关键代码
初始化训练方法关键代码:
def _init_train_methods(self):
"""
初始化训练方法:生成器与判别器损失,梯度下降方法,初始化session。
:return: None
"""
# 寻找生成器与判别器相关的变量
total_vars = tf.trainable_variables()
d_vars = [var for var in total_vars if var.name.startswith("discriminator")]
g_vars = [var for var in total_vars if var.name.startswith("generator")]
if self.mode == "lsgan":
self._init_lsgan_loss()
self.D_trainer = tf.train.RMSPropOptimizer(learning_rate=1e-4).minimize(self.D_loss, var_list=d_vars)
self.G_trainer = tf.train.RMSPropOptimizer(learning_rate=1e-4).minimize(self.G_loss, var_list=g_vars)
elif self.mode == "wgan":
self._init_wgan_loss()
self.clip_d = [p.assign(tf.clip_by_value(p, -0.1, 0.1)) for p in d_vars]
self.D_trainer = tf.train.RMSPropOptimizer(learning_rate=5e-5).minimize(self.D_loss, var_list=d_vars)
self.G_trainer = tf.train.RMSPropOptimizer(learning_rate=5e-5).minimize(self.G_loss, var_list=g_vars)
elif self.mode == "wgan-gp":
self._init_wgan_gp_loss()
self.D_trainer = tf.train.AdamOptimizer(
learning_rate=1e-4, beta1=0., beta2=0.9).minimize(self.D_loss, var_list=d_vars)
self.G_trainer = tf.train.AdamOptimizer(
learning_rate=1e-4, beta1=0., beta2=0.9).minimize(self.G_loss, var_list=g_vars)
# 初始化Session
self.sess = tf.InteractiveSession()
self.sess.run(tf.global_variables_initializer())
self.saver = tf.train.Saver(max_to_keep=1);
DCGAN损失函数初始化代码
DCGAN损失函数初始化代码:
// An highlighted block
def _init_dcgan_loss(self):
# 初始化DCGAN损失函数
self.D_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.real_logis, labels=tf.ones_like(self.real_logis)))
self.D_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.gen_logis, labels=tf.zeros_like(self.gen_logis)))
self.D_loss = self.D_loss_fake + self.D_loss_real
self.G_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=self.gen_logis, labels=tf.ones_like(self.gen_logis)));
LSGAN损失函数初始化代码
LSGAN损失函数初始化代码:
// An highlighted block
def _init_lsgan_loss(self):
# 初始化lsgan损失函数 均方误差损失
self.G_loss = tf.reduce_mean((self.gen_logis - 1) ** 2)
self.D_loss = 0.5 * (tf.reduce_mean((self.real_logis - 1) ** 2) + tf.reduce_mean((self.gen_logis - 0) ** 2));
WGAN损失函数初始化代码
WGAN损失函数初始化代码:
// An highlighted block
def _init_wgan_loss(self):
# 初始化wgan损失函数
self.D_loss = tf.reduce_mean(self.real_logis) - tf.reduce_mean(self.gen_logis)
self.G_loss = tf.reduce_mean(self.gen_logis);
WGAN—GP损失函数初始化代码
WGAN—GP损失函数初始化代码:
// An highlighted block
def _init_wgan_gp_loss(self):
# 初始化WGAN-gp损失函数
# 构造梯度标准差
tem_x = tf.reshape(self.x, [-1, self.img_w * self.img_h * self.img_c])
tem_gen_x = tf.reshape(self.gen_out, [-1, self.img_w * self.img_h * self.img_c])
eps = tf.random_uniform([64, 1], minval=0., maxval=1.)
x_inter = eps * tem_x + (1 - eps) * tem_gen_x # 真实数据与伪造数据平均值
x_inter = tf.reshape(x_inter, [-1, self.img_w, self.img_h, self.img_c])
grad = tf.gradients(self._init_discriminator(x_inter, isTrain=self.isTrain, reuse=True), [x_inter])[0]
grad_norm = tf.sqrt(tf.reduce_sum((grad) ** 2, axis=1))
penalty = 10
grad_pen = penalty * tf.reduce_mean((grad_norm - 1) ** 2)
self.D_loss = tf.reduce_mean(self.real_logis) - tf.reduce_mean(self.gen_logis) + grad_pen
self.G_loss = tf.reduce_mean(self.gen_logis);
训练结果
LSGAN
WGAN
WGAN—GP
总结
1.LSGAN不使用Sigmoid激活函数,使用线性激活函数替代Sigmoid激活函数进行线性回归。
2.WGAN进行权重裁剪,根据约束条件设置裁剪范围。
3.WGAN—GP对真实数据与生成数据取平均值后送入判别器计算梯度约束。
4.EBGAN就是使用自动编码器替代判别器预先对真实图片进行训练并重构压缩。
5.WGAN—GP效果最好,但是训练时间比较长。
参考文献
[1] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley,
S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems (NIPS), pp. 2672–2680,2014.
[2] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, X. Chen,
and X. Chen, “Improved techniques for training gans,” in Advances in
Neural Information Processing Systems (NIPS), pp. 2226–2234, 2016.
[3]M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein gan,”
arXiv:1701.07875, 2017.
其他
本文是在GAN、DCGAN的基础之上进行训练技巧的一个提升,LSGAN、WGAN、WGAN—GP、EBGAN等都是在不同的地方对训练的技巧进行一个改进并得到一个更好的训练效果。
本文代码:链接:https://pan.baidu.com/s/14No7ikUIbH2MvNp3DyNbLA
提取码:q5ol