使用spark处理天气数据并可视化
1.爬取河南省2011年-2019年天气数据
file_path:城市列表路径,该文件在我博客资源中
fileName:爬取结果保存路径
import io
import sys
import requests
import os
import bs4
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #改变标准输出的默认编码, 防止控制台打印乱码
target_year_list = ["2011", "2012", "2013", "2014", "2015", "2016", "2017", "2018","2019"]
target_month_list = ["01", "02", "03", "04", "05", "06", "07", "08", "09", "10", "11", "12"]
#得到一个以城市名拼音为键,城市名为名的数据字典,{"ZHENGZHOU":"郑州","KAIFENG":"开封",...}
def get_city_dict(file_path):
city_dict = {}
with open(file_path, 'r',encoding='UTF-8') as file:
#line_list = f.readline()
for line in file:
line = line.replace("\r\n", "")
city_name = (line.split(" ")[0]).strip()
city_pinyin = ((line.split(" ")[1]).strip()).lower()
#赋值到字典中...
city_dict[city_pinyin] = city_name
return city_dict
file_path = "D:/PP/weather/city.txt"
city_dict = get_city_dict(file_path) #从指定文件city.txt读取城市信息,调用get_city_dict
#得到全部url,格式:url = "http://www.tianqihoubao.com/lishi/beijing(城市名)/month/201812(年月).html"
def get_urls(city_pinyin):
urls = []
for year in target_year_list:
for month in target_month_list:
date = year + month
urls.append("http://www.tianqihoubao.com/lishi/{}/month/{}.html".format(city_pinyin, date))#每年每月每个地市
return urls
#用BeautifulSoup解析每个url返回的网页,以得到有用的数据
def get_soup(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status() # 若请求不成功,抛出HTTPError 异常
# r.encoding = 'gbk'
soup = BeautifulSoup(r.text, "html.parser")
return soup
# except HTTPError:
# return "Request Error"
except Exception as e:
print(e)
pass
#保存解析后的网页数据
def get_data(url):
print(url)
try:
soup = get_soup(url)
all_weather = soup.find('div', class_="wdetail").find('table').find_all("tr")
data = list()
for tr in all_weather[1:]:
td_li = tr.find_all("td")
for td in td_li:
s = td.get_text()
# print(s.split())
data.append("".join(s.split()))
res = np.array(data).reshape(-1, 4)
return res
except Exception as e:
print(e)
pass
#数据保存到本地csv文件
def saveTocsv(data, city):
'''
将天气数据保存至csv文件
'''
fileName = 'D:/PP/weather/' + city_dict[city] + '_weather.csv'
result_weather = pd.DataFrame(data, columns=['date', 'tq', 'temp', 'wind'])
# print(result_weather)
result_weather.to_csv(fileName,index=False, header=(not os.path.exists(fileName)), encoding='gb18030') #mode='a'追加
print('Save all weather success!')
#主函数
if __name__ == '__main__':
for city in city_dict.keys(): #读城市字典的键
print(city, city_dict[city])
data_ = list()
urls = get_urls(city) #urls保存了所有城市的所有年月的url
for url in urls:
try:
data_.extend(get_data(url)) # 列表合并,将某个城市所有月份的天气信息写到data_
except Exception as e:
print(e)
pass
saveTocsv(data_, city) # 保存为csv
2.在jupyter notebook中使用spark预处理
jupyter notebook和spark安装和部署参考以下链接: 厦门大学数据库实验室.
from pyspark.sql import Row
import pandas as pd
from pyspark.sql import SparkSession
from pyspark import SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.types import *
spark=SparkSession.builder.appName("lz").config("spark.driver.memory", "2g").getOrCreate()
sc = SparkContext.getOrCreate()
# 对于每一行用逗号分隔的数据,使用 csv 模块进行解析并转为 Row 对象,得到可以转为 DataFrame 的 RDD
df = [0 for i in range(18)]
rdd = [0 for i in range(18)]
k = 0
city_list = ["郑州","开封","洛阳","平顶山","安阳","鹤壁","新乡","焦作","濮阳","许昌","漯河","三门峡","商丘","周口","驻马店","南阳","信阳","济源"]
for city in city_list:
FileName = 'file:///home/hadoop/Documents/' + city + '_weather.csv'
print (FileName)
rdd[k] = sc.textFile(FileName,use_unicode='utf-8')
header = rdd[k].first()#第一行 print(header)
rdd[k] = rdd[k].filter(lambda row:row != header)#删除第一行
rdd[k] = rdd[k].map(lambda line: line.split(","))
df[k] = rdd[k].map(lambda line: Row(date=line[0],
tq=line[1],
temp=line[2],
wind=line[3])).toDF()
k+=1
#allweather_mdf[0].select('temp').show(10)
file:///home/hadoop/Documents/郑州_weather.csv
file:///home/hadoop/Documents/开封_weather.csv
file:///home/hadoop/Documents/洛阳_weather.csv
file:///home/hadoop/Documents/平顶山_weather.csv
file:///home/hadoop/Documents/安阳_weather.csv
file:///home/hadoop/Documents/鹤壁_weather.csv
file:///home/hadoop/Documents/新乡_weather.csv
df[0].show(5)
±----------±------±----±--------------+
| date| temp| tq| wind|
±----------±------±----±--------------+
|2011年01月01日| 1℃/-7℃| 晴/阴|无持续风向微风/无持续风向微风|
|2011年01月02日|-1℃/-7℃|小雪/阵雪|无持续风向微风/无持续风向微风|
|2011年01月03日| 2℃/-6℃| 多云/晴|无持续风向微风/无持续风向微风|
|2011年01月04日| 4℃/-5℃| 晴/晴|无持续风向微风/无持续风向微风|
|2011年01月05日| 4℃/-7℃|多云/多云|西北风4-5级/西北风4-5级|
±----------±------±----±--------------+
only showing top 5 rows
#转换日期列格式、温度列除去符号"℃"
from pyspark.sql.functions import *
for k in range(18):
df[k] = df[k].withColumn('date',regexp_replace(df[k]['date'],"年","-"))
df[k] = df[k].withColumn('date',regexp_replace(df[k]['date'],"月","-"))
df[k] = df[k].withColumn('date',regexp_replace(df[k]['date'],"日",""))
df[k] = df[k].withColumn('temp',regexp_replace(df[k]['temp'],"℃",""))
#日期列转换为date类型
from pyspark.sql.types import DateType
for k in range(18):
df[k] = df[k].withColumn('date', df[k]['date'].cast(DateType()))
#分割列
for k in range(18):
df[k] = df[k].withColumn("最高气温", split("temp", "\/")[0])\
.withColumn("最低气温", split("temp", "\/")[1])
df[k] = df[k].withColumn("白天天气", split("tq", "\/")[0])\
.withColumn("夜间天气", split("tq", "\/")[1])
df[k] = df[k].withColumn("白天风向风力", split("wind", "\/")[0])\
.withColumn("夜间风向风力", split("wind", "\/")[1])
df[k] = df[k].drop('temp','tq','wind')
df[10].show(5)
±---------±—±---±—±---±-------±-------+
| date|最高气温|最低气温|白天天气|夜间天气| 白天风向风力| 夜间风向风力|
±---------±—±---±—±---±-------±-------+
|2011-01-01| 3| -5| 多云| 阴|无持续风向≤3级|无持续风向≤3级|
|2011-01-02| 0| -6| 阴| 阴|无持续风向≤3级|无持续风向≤3级|
|2011-01-03| 2| -7| 多云| 多云| 无持续风向微风| 无持续风向微风|
|2011-01-04| 3| -6| 晴| 晴| 无持续风向微风| 无持续风向微风|
|2011-01-05| 3| -7| 晴| 晴|无持续风向≤3级|无持续风向≤3级|
±---------±—±---±—±---±-------±-------+
only showing top 5 rows
3.到此完成数据预处理,以下开始数据可视
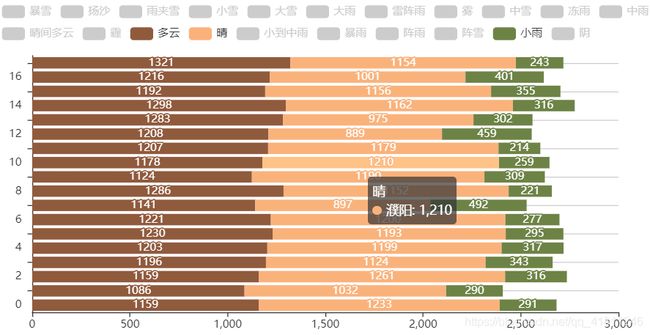
(1)天气现象的数量汇总(条形图)
#各地市的天气状况汇总
city_list = ["郑州","开封","洛阳","平顶山","安阳","鹤壁","新乡","焦作","濮阳","许昌","漯河","三门峡","商丘","周口","驻马店","南阳","信阳","济源"]
df_tianqi = [0 for i in range(18)]
for k in range(18):
df_tianqi[k] = df[k].select(df[k]["白天天气"])
df_tianqi[k] = df_tianqi[k].groupBy(df_tianqi[k]["白天天气"]).count()
df_tianqi[k] = df_tianqi[k].withColumn("city",lit(city_list[k]))
df_all =df_tianqi[0]
for k in range(17):
df_all = df_all.unionAll(df_tianqi[k+1])#合并各地市的天气类型统计结果
#所有地市天气类型
import numpy as np
tq_types = df_all.select(df_all["白天天气"]).filter(df_all["白天天气"]!= '-').distinct()#所有天气类型去重
types_list = tq_types.select("白天天气").collect()
types_list = np.ravel(types_list)#列表降维
#以各地市所有天气类型透视各地市“白天天气”列
df_x = df_all.groupBy('city')\
.pivot('白天天气', types_list)\
.agg(sum('count'))\
.fillna(0)
from pyspark.sql.types import ShortType
for x in types_list:
df_x = df_x.withColumn(x, df_x[x].cast(ShortType()))
city = df_x.select("city").collect()
city = np.ravel(city)#列表降维
from pyecharts import Bar
bar = Bar()
for x in types_list:
print(x)
a_type = df_x.select(x).collect()
a_type = np.ravel(a_type)
bar.add(x, city, a_type, is_label_show=True,is_stack=True, label_pos='inside', is_convert=True)
print(a_type)
a_type = []
bar.render('./各地天气条形图.html')
bar
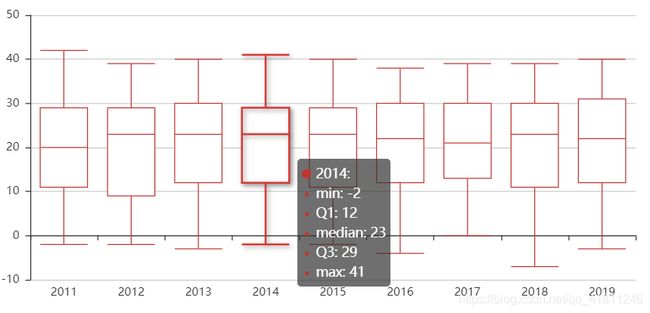
(2)各年份白天气温的箱线图
#添加年份列
import pyspark.sql.functions as f
for k in range(18):
df[k] = df[k].withColumn('年份',f.year(f.to_timestamp('date', 'yyyy/MM/dd')))
#清洗“最高气温”列,去掉空值
from pyspark.sql.types import ByteType
for k in range(18):
df[k] = df[k].filter(df[k]["最高气温"] != '')
df[k] = df[k].filter(df[k]["最高气温"] != 'NaN').withColumn("最高气温", df[k]["最高气温"].cast(ByteType()))
#从原数据框提取“最高气温”列到列表
df_year = [0 for i in range(9)]
for m in range(9):
year_now = m+2011
df_year[m] = df[0].filter(df[0]["年份"] == year_now).select("最高气温")
for k in range(17):
temp = df[k+1].filter(df[k+1]["年份"] == year_now).select("最高气温")
df_year[m] = df_year[m].unionAll(temp)
#将dataframe转化为列表
import numpy as np
y_axis = [[] for i in range(9)]
for m in range(9):
temp1 = df_year[m].select("最高气温").collect()
y_axis[m] = np.ravel(temp1)
#绘箱线图
from pyecharts import Boxplot
boxplot = Boxplot()
x_axis = [i+2011 for i in range(9)]
_yaxis = boxplot.prepare_data(y_axis) # 可以实现转换数据,将原数据列表计算:均值,四分之一...
boxplot.add("", x_axis, _yaxis)
boxplot
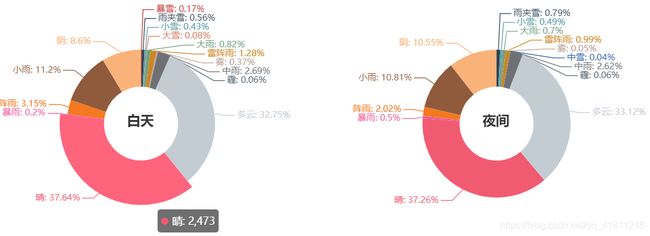
(3)统计2017 年河南省天气现象类型(饼状图)
#提取各地级市2017年数据
df_2017 = [0 for i in range(18)]
for k in range(18):
df_2017[k] = df[k].withColumn('年份',f.year(f.to_timestamp('date', 'yyyy/MM/dd')))
df_2017[k] = df_2017[k].filter(df_2017[k]["年份"]==2017)
#提取"白天天气","夜间天气"两列
df_baitian = [0 for i in range(18)]
df_yejian = [0 for i in range(18)]
for k in range(18):
df_baitian[k] = df_2017[k].select(df_2017[k]["白天天气"])
df_yejian[k] = df_2017[k].select(df_2017[k]["夜间天气"])
#拼接数据框后统计
df_temp1 = df_baitian[0]
df_temp2 = df_yejian[0]
for k in range(17):
df_temp1 = df_temp1.unionAll(df_baitian[k+1])
df_temp2 = df_temp2.unionAll(df_yejian[k+1])
df_temp1 = df_temp1.groupBy(df_temp1["白天天气"]).count()
df_temp2 = df_temp2.groupBy(df_temp2["夜间天气"]).count()
#对两列数据框转化到列表后,绘图
from pyecharts import Pie, Grid
df_temp1_typ = df_temp1.select(df_temp1["白天天气"]).rdd.collect()
df_temp1_num = df_temp1.select(df_temp1["count"]).rdd.collect()
pie1 = Pie("白天", title_pos="33%", title_top="40%")
pie1.add("", df_temp1_typ, df_temp1_num, radius=[25, 50], center=[35, 44], legend_pos="10%", legend_top="45%", legend_orient="horizontal",is_label_show=True)
df_temp2_typ = df_temp2.select(df_temp2["夜间天气"]).rdd.collect()
df_temp2_num = df_temp2.select(df_temp2["count"]).rdd.collect()
pie2 = Pie("夜间", title_pos="73%", title_top="40%")
pie2.add("", df_temp2_typ, df_temp2_num, radius=[25, 50], center=[75, 44], is_label_show=True, is_legend_show=False)
grid = Grid("天气类型情况",width=1200)
grid.add(pie1)
grid.add(pie2)
grid