明亮如星研旅(5)——Robust Classification with Convolutional Prototype Learning
文章目录
- 一、简述
- 二、主要内容
-
- 2.1 框架的网络结构
- 2.2 前馈预测与反馈训练
- 2.3多分类损失函数
-
- 2.3.1 Minimum classification error loss (MCE)
- 2.3.2 Margin based classification loss (MCL)
- 2.3.3 Distance based cross entropy loss (DCE)
- 2.4 Generalized CPL with prototype loss
- 三、实验
-
- 3.1 Experiments and analysis on MNIST
- 3.2 Experiments and analysis on CIFAR-10
- 3.3 Experiments and analysis on OLHWDB
- 3.4 Experiments for rejection
- 3.5 Experiments for class-incremental learning
- 3.6 Experiments with small sample size
- 3.7 Experiments with multiple prototypes
- 四、结论
这里继续呈上一篇基于深度学习的手写字体识别的文章(【Paper】 Yang H M , Zhang X Y , Yin F , et al. Robust Classification with Convolutional Prototype Learning[J]. 2018.)。
这篇文章发表在2018年的CVPR,与其说这是一篇关于文字识别的文章,不如说是调整卷积网络结构的文章。近几年学术界逐渐发现传统的卷积神经网络的缺陷,通过生成对抗样本,使得原来的样本图片经较少改动(人眼完全区分不出来),在网络中得到完全不同的结果,而且有很高的置信度。
一、简述
针对前面提到的鲁棒性问题进行研究,作者发现了问题主要出在用于分类的softmax。作者提出了卷积原型学习(CPL),利用每个类的原型来代表每个类,定义不同的多分类评价函数,来训练网络。除此之外又提出了原型损失(PL)作为正则化项,使得评价函数既考虑类间的间隔又考虑类内的紧致性。
卷积原型学习可以看作是一个高斯分布假设下的生成模型,每个原型代表一个类,使得模型其有较好的拒绝能力,也能胜任类别增加学习。其实所谓的原型学习,我们应该学过不少基础的方法,只是换了个说法,例如K-mean聚类算法、LVQ算法等等,就是用某个样本来代表一个类呗,这里作者将原型学习同深度学习结合起来了。
二、主要内容
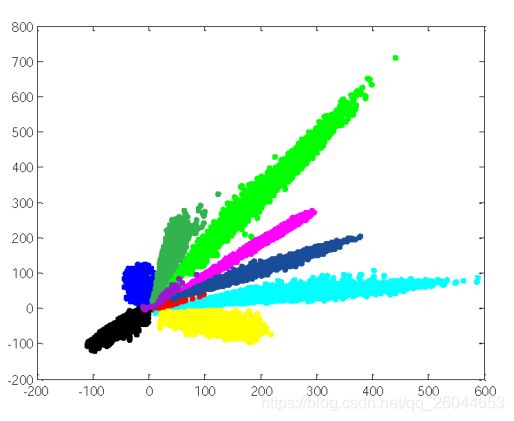
从传统卷积神经网络训练结果看,不同类别不是呈现圆形,而是椭圆长条形,而且都聚合在一起,这导致同类样本的距离甚至大于不同类别样本的距离,即类间差异小于类内差异,这就导致模型的鲁棒性不佳。
作者取消了模型的softmax层,自己定义损失函数,从数据中学得最能代表每一类的原型。损失函数设计时同时考虑到:1、类内聚合度;2、类间分离性;将样本映射到原型附近的类特征空间
2.1 框架的网络结构
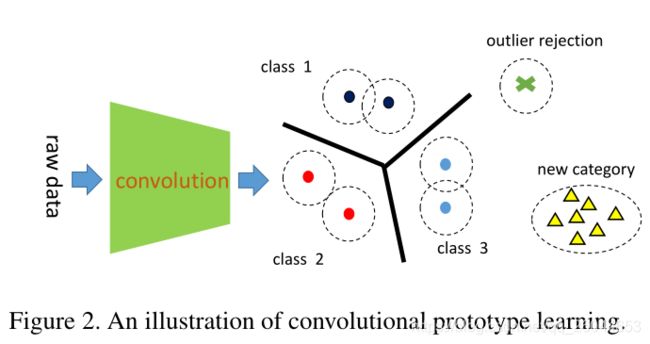 左边的CNN是用于提取特征,右边用原型来进行分类,可能存在新类的样本,也可能存在噪声样本。这里用 f ( x ; θ ) f(x;\theta) f(x;θ)代表特征提取器, x x x是训练样本, θ \theta θ是CNN的参数。对于原型为 m i j m_{ij} mij,其中 i ∈ { 1 , 2 , . . . , C } i\in \{1,2,...,C\} i∈{1,2,...,C}代表类别数, j ∈ { 1 , 2 , . . . K } j\in\{1,2,...K\} j∈{1,2,...K}代表每个类别的原型数。
左边的CNN是用于提取特征,右边用原型来进行分类,可能存在新类的样本,也可能存在噪声样本。这里用 f ( x ; θ ) f(x;\theta) f(x;θ)代表特征提取器, x x x是训练样本, θ \theta θ是CNN的参数。对于原型为 m i j m_{ij} mij,其中 i ∈ { 1 , 2 , . . . , C } i\in \{1,2,...,C\} i∈{1,2,...,C}代表类别数, j ∈ { 1 , 2 , . . . K } j\in\{1,2,...K\} j∈{1,2,...K}代表每个类别的原型数。
2.2 前馈预测与反馈训练
一个样本分类为最近的原型所属的类别: x ∈ x \in x∈ class arg max i = 1 C g i ( x ) \arg \max _{i=1}^{C} g_{i}(x) argmaxi=1Cgi(x),其中
g i ( x ) = − min j = 1 ∥ f ( x ; θ ) − m i j ∥ 2 2 g_{i}(x)=-\min _{j=1}\left\|f(x ; \theta)-m_{i j}\right\|_{2}^{2} gi(x)=−j=1min∥f(x;θ)−mij∥22反馈训练要求CNN与原型学习能够同时训练,即模型框架的损失函数要对参数 θ \theta θ与 M M M能够进行复合链式法则求导。
2.3多分类损失函数
2.3.1 Minimum classification error loss (MCE)
首先是最小分类误差损失,这个损失函数我之前的博客明亮如星研旅(3)—— Discriminative Learning Quadratic Discriminant Function for Handwriting Recognition介绍过,前面以类条件密度函数的相反数作为度量距离,这里就直接用 l 2 l_2 l2范数作为度量距离 μ y ( x ) = ∥ f ( x ) − m y i ∥ 2 2 − ∥ f ( x ) − m r j ∥ 2 2 \mu_{y}(x)=\left\|f(x)-m_{y i}\right\|_{2}^{2}-\left\|f(x)-m_{r j}\right\|_{2}^{2} μy(x)=∥f(x)−myi∥22−∥f(x)−mrj∥22然后带入得到损失函数 l ( ( x , y ) ; θ , M ) = 1 1 + e − ξ μ y l((x, y) ; \theta, M)=\frac{1}{1+e^{-\xi \mu_{y}}} l((x,y);θ,M)=1+e−ξμy1而且这个损失函数是关于 M M M和 θ \theta θ可导(后面都证明这个导数存在性,模型是可统一训练)
∂ l ∂ f = 2 ξ l ( 1 − l ) ( m r j − m y i ) \frac{\partial l}{\partial f}=2 \xi l(1-l)\left(m_{r j}-m_{y i}\right) ∂f∂l=2ξl(1−l)(mrj−myi) ∂ l ∂ m y i = 2 ξ l ( 1 − l ) ( m y i − f ( x ) ) \frac{\partial l}{\partial m_{y i}}=2 \xi l(1-l)\left(m_{y i}-f(x)\right) ∂myi∂l=2ξl(1−l)(myi−f(x)) ∂ l ∂ m r j = 2 ξ l ( 1 − l ) ( f ( x ) − m r j ) \frac{\partial l}{\partial m_{r j}}=2 \xi l(1-l)\left(f(x)-m_{r j}\right) ∂mrj∂l=2ξl(1−l)(f(x)−mrj)
2.3.2 Margin based classification loss (MCL)
基于间隔的分类损失同SVM定义了一个分类间隔,从而提高分类的鲁棒性。 l ( ( x , y ) ; θ , M ) = [ d ( f ( x ) , m y i ) − d ( f ( x ) , m r j ) + m ] + l((x, y) ; \theta, M)=\left[d\left(f(x), m_{y i}\right)-d\left(f(x), m_{r j}\right)+m\right]_{+} l((x,y);θ,M)=[d(f(x),myi)−d(f(x),mrj)+m]+其中 m r j m_{rj} mrj表示最靠近类中最相似的原型, m m m代表间隔,为了统一数量级,即统一到[0-1]之间,进一步改进为:
l ( ( x , y ) ; θ , M ) = [ d ( f ( x ) , m y i ) − d ( f ( x ) , m r j ) d ( f ( x ) , m y i ) + d ( f ( x ) , m r j ) + m ] + l((x, y) ; \theta, M)=\left[\frac{d\left(f(x), m_{y i}\right)-d\left(f(x), m_{r j}\right)}{d\left(f(x), m_{y i}\right)+d\left(f(x), m_{r j}\right)}+m\right]_{+} l((x,y);θ,M)=[d(f(x),myi)+d(f(x),mrj)d(f(x),myi)−d(f(x),mrj)+m]+ 相应的又验证了一下导数存在性。
2.3.3 Distance based cross entropy loss (DCE)
基于距离的交叉熵损失以距离为度量,重新定义交叉熵损失。与softmax相似,其也可以作为分类的置信度。
p ( x ∈ m i j ∣ x ) = e − γ d ( f ( x ) , m i j ) ∑ k = 1 C ∑ l = 1 K e − γ d ( f ( x ) , m k l ) p\left(x \in m_{i j} | x\right)=\frac{e^{-\gamma d\left(f(x), m_{i j}\right)}}{\sum_{k=1}^{C} \sum_{l=1}^{K} e^{-\gamma d\left(f(x), m_{k l}\right)}} p(x∈mij∣x)=∑k=1C∑l=1Ke−γd(f(x),mkl)e−γd(f(x),mij)相应的损失函数为 l ( ( x , y ) ; θ , M ) = − log p ( y ∣ x ) l((x, y) ; \theta, M)=-\log p(y | x) l((x,y);θ,M)=−logp(y∣x)其中 p ( y ∣ x ) = ∑ j = 1 K p ( x ∈ m y j ∣ x ) p(y | x)=\sum_{j=1}^{K} p\left(x \in m_{y j} | x\right) p(y∣x)=∑j=1Kp(x∈myj∣x)为相应标记类的概率和。
2.4 Generalized CPL with prototype loss
这里提出了GCPL,即加入正则化项
p l ( ( x , y ) ; θ , M ) = ∥ f ( x ) − m y j ∥ 2 2 p l((x, y) ; \theta, M)=\left\|f(x)-m_{y j}\right\|_{2}^{2} pl((x,y);θ,M)=∥f(x)−myj∥22其中 m y j m_{y j} myj代表GT类中最相似的原型,联合两项最后得到GCPL的损失函数为
loss ( ( x , y ) ; θ , M ) = l ( ( x , y ) ; θ , M ) + λ p l ( ( x , y ) ; θ , M ) \operatorname{loss}((x, y) ; \theta, M)=l((x, y) ; \theta, M)+\lambda p l((x, y) ; \theta, M) loss((x,y);θ,M)=l((x,y);θ,M)+λpl((x,y);θ,M)其实这个损失函数有两类损失度量,左边的 l l l描述了类间间隔损失,右边的 p l pl pl描述了类内紧致性损失,这个的损失函数刻画,相比于Softmax+cross entropy损失有较大的优势。
三、实验
实验中采用前人设计好的CNN网络,比较采用Softmax+cross entropy 和 原型学习 两种方式,对实验结果的影响,也验证GCPL具有拒绝以及类增加学习能力。值得注意,实验中每个类都使用一个原型,即 K = 1 K=1 K=1。
3.1 Experiments and analysis on MNIST
在这个实验中采用的网络是LeNet++,具体结构如下(之所以选择这个网络,个人觉得这个网络能把最后的特征降到两维,可以通过图表表示出来)
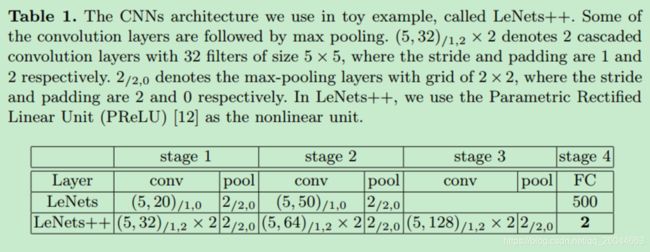
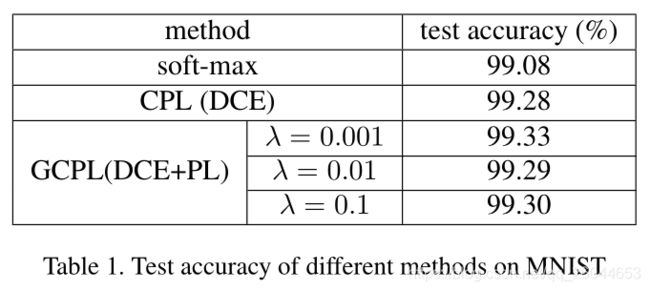
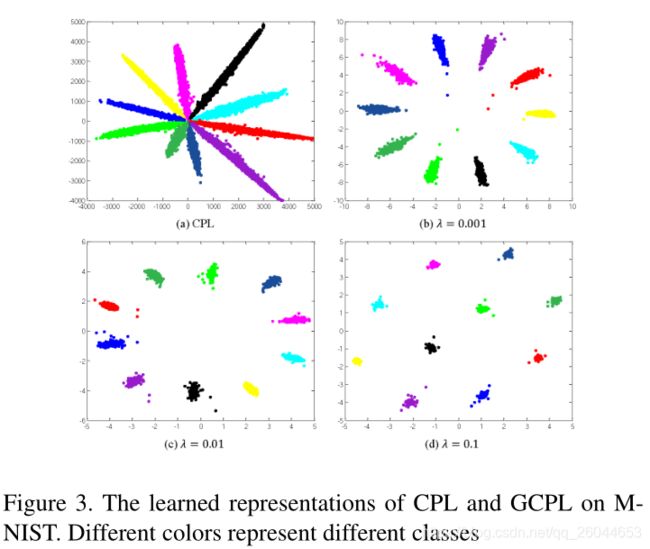
可以看到CPL与GCPL有更高的准确率(尽管提高不多),从聚类图可以看到,加入PL之后聚类结果十分可观。
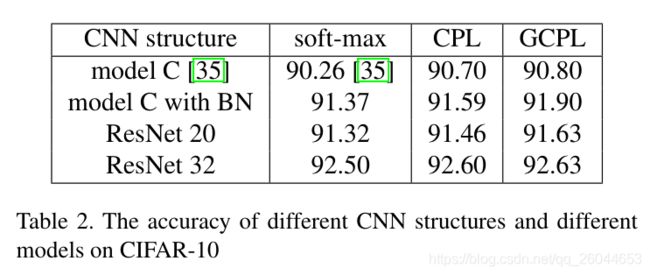
3.2 Experiments and analysis on CIFAR-10
这里的CNN使用Mode C,具体结构如下: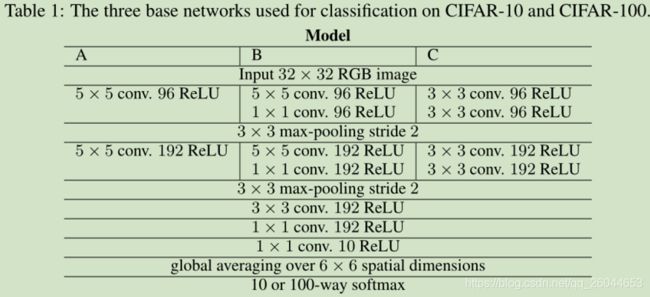
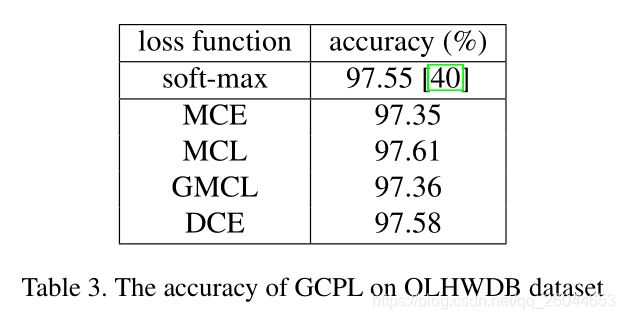
3.3 Experiments and analysis on OLHWDB
本实验使用的网络结构同我之前的博客所介绍的网络明亮如星研旅(4)—— Online and offline handwritten Chinese character recognition
3.4 Experiments for rejection
该实验采用MNIST and CIFAR-10 两个数据集,其中CIFAR-10作为拒绝样本,使用3.1的网络得到如下的结果:
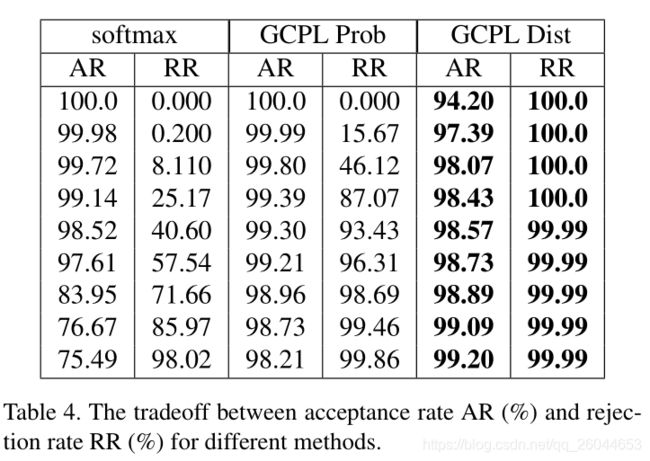
我们针对Distance based cross entropy loss (DCE)定义一个阈值,作为拒绝的标准。AR代表接受率,PR代表拒绝率,表格每一行是不同阈值下的结果,我们可以看到基于距离损失(DCE)的GCPL在这些域值,接受率和拒绝率均有较高的值。
3.5 Experiments for class-incremental learning
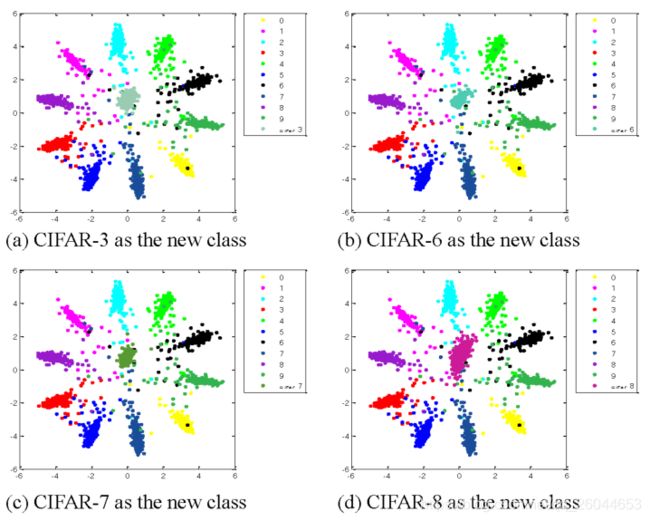
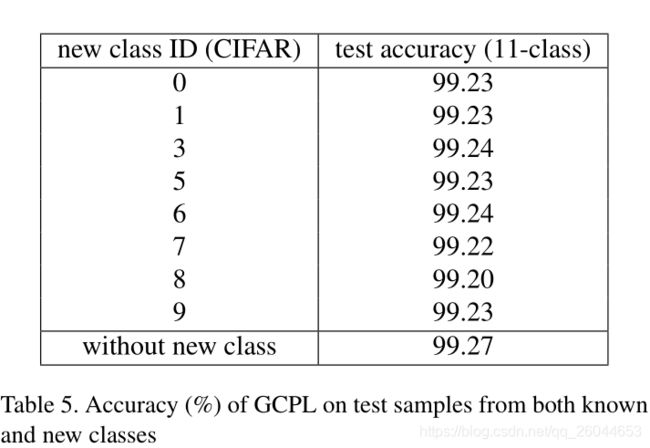
网络在MNIST训练集中训练,然后加入CIFAR中的一类,得到如上的结果,每个类之间区分性挺好。
3.6 Experiments with small sample size
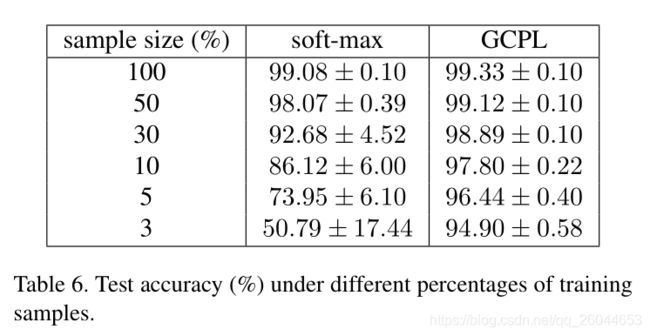
这里看到在小样本训练集下,GCPL仍然有较高的准确率,而且准确率下降较少,这个结果还是比较喜人的。
3.7 Experiments with multiple prototypes
前面提到GCPL每一类都只使用一个原型,在当前数据集下,发现原型数的增加,准确率反而下降了。文中说是在简单训练样本下,每个类用单一的高斯分布就能够较好的代表整个类了。对于更加复杂的建模,多原型可能有更好的准确性。

四、结论
优点:
- 发现了问题主要出在用于分类的softmax,提出了卷积原型学习(CPL),利用每个类的原型来代表每个类,定义不同的多分类评价函数来训练网络。
- 提出了原型损失(PL)作为正则化项,使得评价函数既考虑类间的间隔又考虑类内的紧致性。
- 卷积原型学习可以看作是一个高斯分布假设下的生成模型,每个原型代表一个类,使得模型其有较好的拒绝能力,也能胜任类增加学习。
缺点:
- 文章各种实验只使用了一个原型就能得到较好的结果,增加原型个数反而降低了准确率,未能完全体现原型学习的优势。
- 个别实验具体使用的损失函数未交代清楚。
思考:文章最后提到说,一开始样本的特征十分复杂,而经过CNN后,用单高斯分布模型就能很好的建模,所以导致多原型效果反而变差,那么是不是可以自己搭建一个小网络多原型的GCPL来进行学习分类哪,这样既加快速度又能保证较高的分类效率。