【YOLOv3从头训练 数据篇】
YOLOv3从头训练 数据篇
- 前言
- 数据下载
- 数据可视化
- 标签生成
- 生成训练路径文件
- 结语
前言
最近在忙着怎么从头实现YOLOv3,从网上找了很多教程,也在GitHub上面找到了挺多的代码的,有些能看懂有些看不懂,看不懂的原因有两个,一个是自己太菜了,对pytorch的使用不熟悉;另一个是自己太菜了,YOLO系列的论文只读个大概,读过之后又忘记了,一些实现细节自己也不会。
看网上的代码以及视频,大多是从YOLOv3的代码和结构开始,很少有讲到关于使用的数据集和标签是怎么得来的。一开始看B站上面的大佬敲代码的时候,就觉得好牛逼,中途一看到数据处理部分,顿时一愣,虽然知道它用的是上面数据集,但是不知道怎么来的,这可不行,没有数据代码怎么跑的起来。没办法,出来混总是要还的,以前没有用过COCO数据集,现在就得补上,好了,废话就到这里,下面开始正题吧。
数据下载
先放上COCO数据集的官方下载地址:
COCO数据集官方下载地址
官网里面的数据集有好几个,自己向用哪个就下载哪个好了,官网对于COCO 数据集的介绍也是挺详细的。自己多花点时间看就行了,本人是在服务器上运行代码,因为同学正好有COCO 2017的数据集,所以就不用下载到本地再上传到服务器了。
在GitHub上面找代码的时候,发现有一个工程里面有下载数据集的脚本,通过用wget的方式直接下载到服务器上面,因为我也没有用过,不知道效果怎么样,这里提供一下脚本的连接,用过wget的应该都能看懂:
wget方式直接下载到服务器
本人用的数据集为2017 Train images和2017 Val images对应的标签文件为2017Train/Val annotations。两个images压缩包解压缩之后得到的是图片,而annotations解压缩之后得到的是6个后缀为.json的文件,这些标签的对应什么内容官网也有很详细的解释,因为YOLOv3用于目标检测,所以对应的文件为instances_train2017.json和instances_val2017.json。附上官网的解释:
COCO数据集官方解释
网上也有人详细的整理了一下,附上知乎的文章:
COCO数据集标注详解
数据可视化
得到数据之后,看看图片长什么样,看看标签和图片结合之后长什么样,因此就有了这一部分。本来是没有打算弄这一部分的,因为在GitHub上面找代码的时候发现找到的代码用标签的方式和官网介绍的有点不对,于是就想看一下效果,如果在数据处理这里出错了后面造成更大的错误就很难找了。
先上代码
import json
import cv2
import os
# COCO2017 各个类别的id
COCO_LABELS = {1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle', 5: 'airplane', 6: 'bus', 7: 'train', 8: 'truck',
9: 'boat', 10: 'traffic light', 11: 'fire hydrant', 13: 'stop sign', 14: 'parking meter', 15: 'bench',
16: 'bird', 17: 'cat', 18: 'dog', 19: 'horse', 20: 'sheep', 21: 'cow', 22: 'elephant', 23: 'bear',
24: 'zebra', 25: 'giraffe', 27: 'backpack', 28: 'umbrella', 31: 'handbag', 32: 'tie', 33: 'suitcase',
34: 'frisbee', 35: 'skis', 36: 'snowboard', 37: 'sports ball', 38: 'kite', 39: 'baseball bat',
40: 'baseball glove', 41: 'skateboard', 42: 'surfboard', 43: 'tennis racket', 44: 'bottle',
46: 'wine glass', 47: 'cup', 48: 'fork', 49: 'knife', 50: 'spoon', 51: 'bowl', 52: 'banana',
53: 'apple', 54: 'sandwich', 55: 'orange', 56: 'broccoli', 57: 'carrot', 58: 'hot dog',
59: 'pizza', 60: 'donut', 61: 'cake', 62: 'chair', 63: 'couch', 64: 'potted plant',
65: 'bed', 67: 'dining table', 70: 'toilet', 72: 'tv', 73: 'laptop', 74: 'mouse', 75: 'remote',
76: 'keyboard', 77: 'cell phone', 78: 'microwave', 79: 'oven', 80: 'toaster', 81: 'sink', 82: 'refrigerator',
84: 'book', 85: 'clock', 86: 'vase', 87: 'scissors', 88: 'teddy bear', 89: 'hair drier', 90: 'toothbrush'}
def viewLabels(image_path, json_path):
with open(json_path) as annos:
# annotations = json.load(annos)['annotations']
all_an = json.load(annos)
annotations = all_an['annotations']
category = all_an['categories']
c_name = {}
for i in category:
if i['id'] not in c_name:
c_name[i['id']] = i['name']
print(c_name)
# label = json.load(json_path)
# print(len(annotations[1]))
# print(annotations[1])
# view image use index
# image_id = annotations[0]['image_id']
# bbox = annotations[0]['bbox']
# x, y, w, h = bbox
# single_image = os.path.join(image_path, str(image_id).zfill(12) + '.jpg')
# image = cv2.imread(single_image)
# anno_image = cv2.rectangle(image, (int(x), int(y)), (int(x + w), int(y + h)), (0, 255, 255), 2)
# cv2.imshow('demo', anno_image)
# cv2.waitKey(5000)
# view images include person
for i in range(len(annotations)):
# if annotations[i]['category_id'] != 1:
# continue
image_id = annotations[i]['image_id']
print(image_id)
bbox = annotations[i]['bbox']
x, y, w, h = bbox
single_image = os.path.join(image_path, str(image_id).zfill(12) + '.jpg')
image = cv2.imread(single_image)
anno_image = cv2.rectangle(image, (int(x), int(y)), (int(x+w), int(y + h)), (0, 255, 255), 2)
title_name = c_name.get(annotations[i]['category_id'])
print(c_name.get(annotations[i]['category_id']))
cv2.imshow(title_name, anno_image)
cv2.waitKey(5000)
if __name__ == "__main__":
image_path = r'your_path/COCO/train2017'
json_path = r'your_path/COCO/annotations/instances_train2017.json'
viewLabels(image_path, json_path)
这里存在一个巨坑,就是从instances_train2017.json和instances_val2017.json里面读取到的类别ID不是连续的,COCO数据集总共有80个类别,但是类别ID有超过80的,从GitHub上面找到的代码都是用的是连续的,发现这个不对劲之后,感觉说多了都是泪。如上面的代码所示,本人已经把标签里面的类别及其ID写成一个字典的形式了,希望这个坑看到的人不会再踩进去。
这里也附上我看的YOLOv3教程视频,之前用的代码就是里面的,踩的坑也是在其提供的代码里面:
【CV教程】【中字】如何使用 Pytorch 从头开始实现 YOLOv3
视频相关代码
另一个注意事项是annotations里面的bbox在GitHub上面找到的代码解释跟官方的不一样,按照官方的解释能正确的把目标放在框里面。
官网的解释:
annotation{
"id": int, "image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
categories[{
"id": int, "name": str, "supercategory": str,
}]
展示的效果如下:
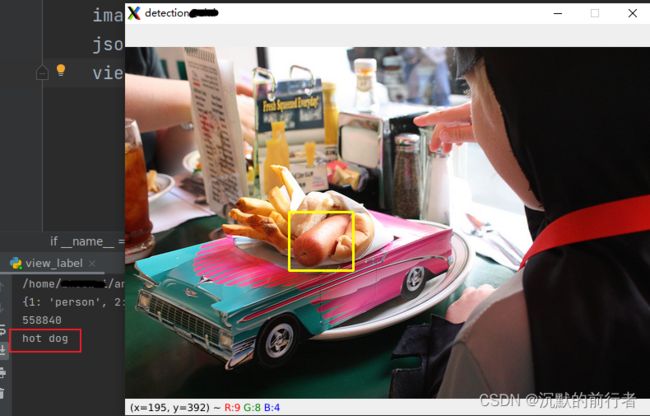
上面的图展示了输出类别以及用框标出来的目标。
参考链接:COCO数据集检测框可视化参考链接
标签生成
首先要明白的是,YOLOv3的标签格式是[class category, x, y, w, h]第一个为类别的id,也就是这个框里面的目标是什么类别,x和y为框的中心坐标,w和h为框的宽和高,在代码实现里面怕大的边界框影响比小的边界框影响大,因此要对这x,y,w,h进行归一化…另外,因为一张图片中存在多个目标,也就是说一张图片对应多个标签,因此一张图片的标签用一个txt文件进行保存。代码如下:
import os, sys, zipfile
import json
import glob
def convert(size, box):
# size[0]: image width; size[1]: image height use for normalization
dw = 1. / (size[0])
dh = 1. / (size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def get_coco_data(path):
data = json.load(open(path, 'r'))
imgs = data['images']
annotations = data['annotations']
print(len(imgs))
for img in imgs:
filename = img['file_name']
img_w = img['width']
img_h = img['height']
img_id = img['id']
ana_txt_name = filename.split('.')[0] + '.txt'
f_txt = open(os.path.join('/your_path/COCO/train_labels', ana_txt_name), 'w')
for ann in annotations:
if ann['image_id'] == img_id:
box = convert((img_w, img_h), ann['bbox'])
f_txt.write('%s %s %s %s %s\n' % (ann['category_id'], box[0], box[1], box[2], box[3]))
f_txt.close()
if __name__ == '__main__':
# 存储数据的类别和标签信息,每张图片对应一个txt文件
path = '/your_path/COCO/annotations/instances_train2017.json'
get_coco_data(path)
参考链接:
超详细的Yolo检测框预测分析
yolov3实现之coco数据集目标检测准备
生成训练路径文件
因为是跟着视频里面的大佬敲的代码,所以数据格式跟视频里面的保持一样,因此要生成一个训练文件,里面的每一行保存内容图片的保存路径 标签的保存路径(例如 xx/xx/ xx.jpg xx/xx/xx.txt)
代码如下:
def generate_txt(image_path, label_path, txt_name):
images = os.listdir(image_path)
save_path = r'/your_path/COCO/'
# print(os.path.join(save_path, txt_name))
f_txt = open(os.path.join(save_path, txt_name), 'w')
for i in images:
file_names = i.split('.')
image_id = file_names[0]
files = image_path + i + ' ' + label_path + image_id + '.txt'
f_txt.write(files + '\n')
f_txt.close()
if __name__ == '__main__':
image_path = r'/your_path/COCO/val2017/'
label_path = r'/your_path/COCO/val_labels/'
generate_txt(image_path, label_path, 'val.txt')
结语
数据准备阶段就到这里,文章主要为记录自己的工作和给自己一个梳理知识的时间,同时方便以后自己查找。视频里面的代码本人也在努力的看懂和手动实现,有进展本人会找时间更新。
本来想要完整的自己写一遍的,但是突然换了方向,变成了3D检测了,因此这个YOLOv3就只能到这里了,在这里说声抱歉。如果只是想跑成功起来,不关心中间的细节,建议可以在GitHub上搜索YOLOv3,第一个代码中训练自己的数据那部分就可以讲的很明白怎么运行的。
本人水平有限,如有错误敬请指出。最后,望不喜勿喷。