机器学习之特征提取(上)
目录
- 1.什么是特征提取
- 2.字典特征提取
- 3.英文特征提取
- 4.小结
1.什么是特征提取
定义: 将任意数据(如文本或图像)转换为可用于机器学习的数字特征。
2.字典特征提取
举个: 我们对以下数据进行特征提取。
数据字典:
[{‘Name’:‘Lucy’, ‘Score’:80},
{‘Name’:‘Tony’, ‘Score’:95},
{‘Name’:‘John’, ‘temperature’:73}]
流程分析:
(1)实例化DictVectorizer
(2)调用fit_transform方法输入数据并转换
具体实现:
from sklearn.feature_extraction import DictVectorizer
def dict():
# 1.获取数据
data = [{'Name':'Lucy', 'Score':80},
{'Name':'Tony', 'Score':95},
{'Name':'John', 'Score':73}]
# 2.字典特征提取
# 2.1 实例化
transfer = DictVectorizer(sparse = False)
# 2.2 转换
res = transfer.fit_transform(data)
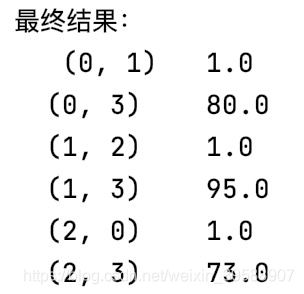
print("最终结果:\n", res)
# 2.3 获取具体属性名
names = transfer.get_feature_names()
print("各属性名:\n", names)
if __name__ == '__main__':
dict()
输出结果:
当sparse = False时

当sparse = True时
思考:在数据存储方面,哪种方式节省空间?
这就不得不讲到sparse矩阵的优势了。
(1)节省空间。当sparse = False时,如果数据量大时,每行需要存储很多个0值。十分浪费空间。当sparse = True时,只存储有数字的位置,就可以节省空间。
(2)sparse矩阵可以提高读取效率,哪个位置有值,直接定位就能找到,而在sparse = False的情形下需要逐个遍历,此时时间复杂度就提高了。
补充:one-hot编码
| Number | Name | Score |
|---|---|---|
| 1 | Lucy | 80 |
| 2 | Tony | 95 |
| 3 | Tony | 73 |
转化为:
| Number | John | Lucy | Tony |
|---|---|---|---|
| 1 | 0 | 1 | 0 |
| 2 | 0 | 0 | 1 |
| 3 | 1 | 0 | 0 |
将每个类别生成一个布尔列,这些列中可以为每个样本取值1。故称为one-hot编码。
3.英文特征提取
举个: 通过对以下数据进行特征提取,实现统计每个单词出现的频率。
数据:
[“The more we do, the more we can do; the more busy we are, the more leisure we have.”]
流程分析:
(1)实例化CountVectorizer
(2)调用fit_transform方法输入数据并转换
具体实现:
from sklearn.feature_extraction.text import CountVectorizer
def english_count():
# 1.获取数据
data = ["The more we do, the more we can do; the more busy we are, the more leisure we have."]
# 2.文本转换
transfer = CountVectorizer()
res = transfer.fit_transform(data)
# 3.查看
names = transfer.get_feature_names()
print("特征名字:\n",names)
print("最终结果: \n",res)
if __name__ == '__main__':
english_count()
输出结果:

思考:如果想要以行的形式展示结果又该如何实现呢?
按照字典特征提取的实例,是否可以设置sparse = True来实现?
transfer = CountVectorizer(sparse=True)
运行结果:
![]()
事实证明,没办法通过sparse = True的方式进行转换。但是,可以通toarray()的方式实现。
# 3.查看
names = transfer.get_feature_names()
print("特征名字:\n",names)
print(res.toarray())
print("最终结果:\n",res)
运行结果:

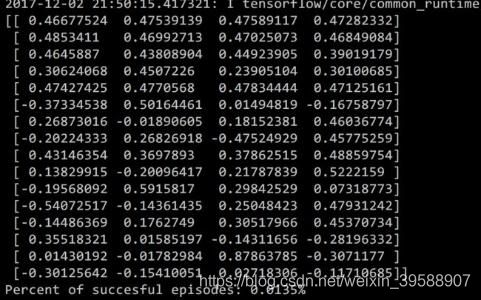
最终结果的第一行表示more这个单词在句子中共出现了4次。但是如果某个单词不需要统计又要如何实现呢?
transfer = CountVectorizer(stop_words=["the"])
运行结果:

4.小结
本次内容主要是机器学习之特征提取 ,我们可以实现字典的特征提取、文本的特征提取以及图像的特征提取。
思考:中文的特征提取如何实现呢?
