逐行讲解CRF实现命名实体识别(NER)
文章标题
- 本文概述
- NER介绍
- 代码详解
-
- 任务
- 导入库
- 加载数据集
- 构造特征字典
- 数据处理
- 模型训练
- 模型验证
- 模型参数
- 备注
- 随机搜索RandomizedSearchCV
本文概述
使用sklearn_crfsuite的CRF工具做中文命名实体识别(NER), 获取中文原始数据集,处理成sklearn_crfsuite所需要的格式,代码有详细注释,若有遗漏或不详细可评论补充。
本文使用CLUE Fine-Grain NER中文数据集,数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(goverment),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)。
数据集详情介绍:https://www.cluebenchmarks.com/introduce.html
数据集下载链接:https://storage.googleapis.com/cluebenchmark/tasks/cluener_public.zip
本文github代码位置:https://github.com/ZejunCao/NER_baseline
代码参考:https://sklearn-crfsuite.readthedocs.io/en/latest/tutorial.html
评价指标详细介绍:https://blog.csdn.net/qq_41496421/article/details/127196850?spm=1001.2014.3001.5502
NER介绍
命名实体识别(Named Entitie Recognition,NER)是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术中必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体。命名实体识别一般分为3大类(实体类、时间类、数字类)和7小类(人名、地名、组织机构名、时间、日期、货币和百分比)。由于有些命名实体不符合一般规律性,难以分离,所以通常在分词任务中单独进行识别处理。
通常在任务中针对某一实体进行识别,例如对地名进行识别
我来到哈尔滨
O O O B M E
代表的含义为:
| 标注 | 含义 |
|---|---|
| B | 当前词为地理命名实体的首部 |
| M | 当前词为地理命名实体的内部 |
| E | 当前词为地理命名实体的尾部 |
| S | 当前词单独构成地理命名实体 |
| O | 当前词不是地理命名实体或组成部分 |
NER标注的方式有很多种,如BIO、BIOE以及BIOES等。
代码详解
任务
本文NER任务使用BIO三位标注法,即:
B-begin:代表实体开头
I-inside:代表实体内部
O-outside:代表不属于任何实体
其后面接实体类型,如 ‘B-name’,‘I-company’。
下文使用jupyter notebook进行代码讲解,github中的代码为.py文件,代码详解大多放在代码段注释中。
导入库
import json
import sklearn_crfsuite
from sklearn_crfsuite import metrics
加载数据集
由于该json文件含多条并列数据,不能直接json.loads读取,需使用for循环逐条读取
json_data = []
with open(path, 'r') as fp:
for line in fp:
json_data.append(json.loads(line))
json_data

# 将数据处理成CRF库输入格式
def data_process(path):
# 读取每一条json数据放入列表中
# 由于该json文件含多个数据,不能直接json.loads读取,需使用for循环逐条读取
json_data = []
with open(path, 'r') as fp:
for line in fp:
json_data.append(json.loads(line))
# 读取到的json_data中每一条数据的格式为
'''
{'text': '浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,',
'label': {'name': {'叶老桂': [[9, 11]]}, 'company': {'浙商银行': [[0, 3]]}}}
'''
# 'name': {'叶老桂': [[9, 11]]} 代表text文本中的索引9-11是'叶老桂',其实体为'name'
# 目标是将json文件处理成如下格式
'''
[['浙', '商', '银', '行', '企', '业', '信', '贷', '部', '叶', '老', '桂', '博', '士', '则', '从', '另', '一',
'个', '角', '度', '对', '五', '道', '门', '槛', '进', '行', '了', '解', '读', '。', '叶', '老', '桂', '认',
'为', ',', '对', '目', '前', '国', '内', '商', '业', '银', '行', '而', '言', ','],
['B-company', 'I-company', 'I-company', 'I-company', 'O', 'O', 'O', 'O', 'O', 'B-name', 'I-name',
'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O',
'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']]
'''
data = []
# 遍历json_data中每组数据
for i in range(len(json_data)):
# 将标签全初始化为'O'
label = ['O'] * len(json_data[i]['text'])
# 遍历'label'中几组实体,如样例中'name'和'company'
for n in json_data[i]['label']:
# 遍历实体中几组文本,如样例中'name'下的'叶老桂'(有多组文本的情况,样例中只有一组)
for key in json_data[i]['label'][n]:
# 遍历文本中几组下标,如样例中[[9, 11]](有时某个文本在该段中出现两次,则会有两组下标)
for n_list in range(len(json_data[i]['label'][n][key])):
# 记录实体开始下标和结尾下标
start = json_data[i]['label'][n][key][n_list][0]
end = json_data[i]['label'][n][key][n_list][1]
# 将开始下标标签设为'B-' + n,如'B-' + 'name'即'B-name'
# 其余下标标签设为'I-' + n
label[start] = 'B-' + n
label[start + 1: end + 1] = ['I-' + n] * (end - start)
# 对字符串进行字符级分割
# 英文文本如'bag'分割成'b','a','g'三位字符,数字文本如'125'分割成'1','2','5'三位字符
texts = []
for t in json_data[i]['text']:
texts.append(t)
# 将文本和标签编成一个列表添加到返回数据中
data.append([texts, label])
return data

构造特征字典
- sklearn-crfsuite输入数据支持多种格式,这里选择字典格式;
- 单个CRF与BiLSTM+CRF不同,BiLSTM会自动生成输入序列中每个字符的发射概率,而单个CRF的发射概率则是通过学习将特征映射成发射概率,sklearn_crfsuite会自动提取特征,类似于xgboost;
- sklearn-crfsuite的数据输入格式采用字典格式,类似于做特征工程,CRF将这些特征映射成发射概率;
'''
序列中的每一个字符处理成如下格式:
{'bias': 1.0,
'word': '商',
'word.isdigit()': False,
'word.is_english()': False,
'-1:word': '浙',
'-1:word.isdigit()': False,
'-1:word.is_english()': False,
'+1:word': '银',
'+1:word.isdigit()': False,
'+1:word.is_english()': False}
'''
def word2features(sent, i):
# 本代码采用大小为3的滑动窗口构造特征,特征有当前字符、字符是否为数字或英文等,当然可以增大窗口或增加其他特征
# 特征长度可以不同
word = sent[i][0]
features = {
'bias': 1.0,
'word': word,
'word.isdigit()': word.isdigit(),
'word.is_english()': is_english(word),
}
# 如果不是序列的第一个字符
if i > 0:
word = sent[i - 1][0]
features.update({
'-1:word': word,
'-1:word.isdigit()': word.isdigit(),
'-1:word.is_english()': is_english(word),
})
else:
# 若该字符为序列开头,则增加特征 BOS(begin of sentence)
features['BOS'] = True
# 如果不是序列的最后一个字符
if i < len(sent) - 1:
word = sent[i + 1][0]
features.update({
'+1:word': word,
'+1:word.isdigit()': word.isdigit(),
'+1:word.is_english()': is_english(word),
})
else:
# 若该字符为序列结尾,则增加特征 EOS(end of sentence)
features['EOS'] = True
return features
# 判断字符是否是英文
def is_english(c):
if ord(c.lower()) >= 97 and ord(c.lower()) <= 122:
return True
else:
return False
- 输入的sent为如下格式,i为当前字符的索引:

- 与下面函数一起使用
# 该段文本序列多长就遍历多少次,i为当前字符索引,将每个字符的特征字典做成列表返回
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
# 遍历每一组文本序列
X_train = [sent2features(s[0]) for s in train]
数据处理
train = data_process('./data/cluener_public/train.json')
valid = data_process('./data/cluener_public/dev.json')
print('训练集长度:', len(train))
print('验证集长度:', len(valid))
X_train = [sent2features(s[0]) for s in train]
y_train = [sent2labels(s[1]) for s in train]
X_dev = [sent2features(s[0]) for s in valid]
y_dev = [sent2labels(s[1]) for s in valid]
print(X_train[0][1])

模型训练
参数配置
- algorithm:lbfgs法求解该最优化问题,此外还有l2sgd、ap、pa、arow
- c1:L1正则系数
- c2:L2正则系数
- max_iterations:迭代次数
- verbose:是否显示训练信息
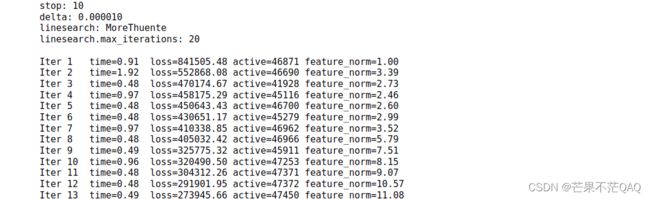
crf_model = sklearn_crfsuite.CRF(algorithm='lbfgs', c1=0.1, c2=0.1, max_iterations=100,
all_possible_transitions=True, verbose=True)
# 由于sklearn版本的问题会报错:AttributeError: 'CRF' object has no attribute 'keep_tempfiles'
# 使用异常处理不会影响训练效果
try:
crf_model.fit(X_train, y_train)
except:
pass
模型验证
模型输出的precision、recall、F1-score及micao、macro、weighted评价指标介绍可查看博客手推多分类precision(精确率)、recall(召回率)、F1分数
labels = list(crf_model.classes_)
# 由于大部分标签都是'O',故不去关注'O'标签的预测
labels.remove("O")
y_pred = crf_model.predict(X_dev)
# 计算F1分数,average可选'micro','macro','weighted',处理多类别F1分数的不同计算方法
# 此metrics为sklearn_crfsuite.metrics,但必须from sklearn_crfsuite import metrics
# 如import sklearn_crfsuite后使用sklearn_crfsuite.metrics(y_dev, y_pred, average='weighted', labels=labels)会报错
# 也可使用sklearn.metrics.f1_score(y_dev, y_pred, average='weighted', labels=labels)),但要求y_dev和y_pred是一维列表
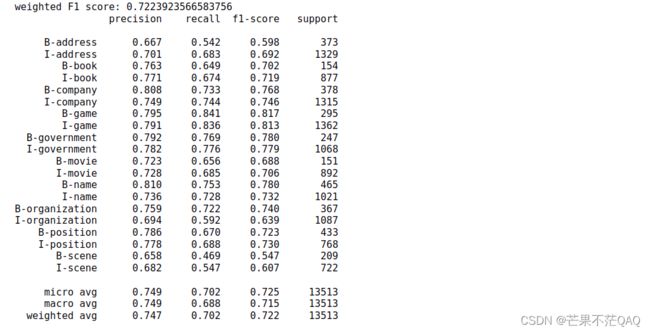
print('weighted F1 score:', metrics.flat_f1_score(y_dev, y_pred,
average='weighted', labels=labels))
# 排好标签顺序输入,否则默认按标签出现顺序进行排列
sorted_labels = sorted(labels, key=lambda name: (name[1:], name[0]))
# 打印详细分数报告,包括precision(精确率),recall(召回率),f1-score(f1分数),support(个数),digits=3代表保留3位小数
print(metrics.flat_classification_report(
y_dev, y_pred, labels=sorted_labels, digits=3
))
模型参数
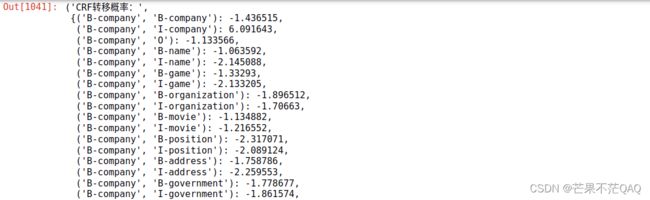
- 查看CRF转移概率
'CRF转移概率:', crf_model.transition_features_
- 查看CRF发射概率,每个特征对应每个输出观测值的概率
'CRF发射概率:', crf_model.state_features_

备注
如需使用此代码,不要无脑复制该网页的所有代码,可有选择的复制或直接下载github代码。
随机搜索RandomizedSearchCV
- 可使用随机搜索选取最优的c1,c2参数
from sklearn.metrics import make_scorer
from sklearn_crfsuite import metrics
# 新版本使用from sklearn.model_selection导入RandomizedSearchCV
from sklearn.model_selection import RandomizedSearchCV
import sklearn_crfsuite
import scipy
f1_scorer = make_scorer(metrics.flat_f1_score,
average='weighted', labels=labels)
# 定义指数分布,没有.pdf代表一个分布,使用.pdf可输出 输入数据对应值
# RandomizedSearchCV传入的params_space参数
# 若是一个分布,需要自带.rvs()函数,如scipy.stats.expon自带.rvs(),则按照分布的概率选取
# 若是一个列表,则等概率选取
params_space = {
'c1': scipy.stats.expon(scale=0.5),
'c2': scipy.stats.expon(scale=0.05),
}
# 重新定义模型
crf = sklearn_crfsuite.CRF(
algorithm='lbfgs',
max_iterations=100,
all_possible_transitions=True,
verbose=True
)
# 带交叉验证的随机搜索
rs = RandomizedSearchCV(crf,params_space,
cv=3, # 交叉验证折数
verbose=1, # 1:偶尔显示信息
n_jobs=-1, # 使用全部的处理器
n_iter=50, # 随机选取n_iter组参数,共训练n_iter*cv个周期
scoring=f1_scorer) # 评价指标
# 必须降低sklearn版本使之小于0.24,使用异常处理无法训练
rs.fit(X_train, y_train)
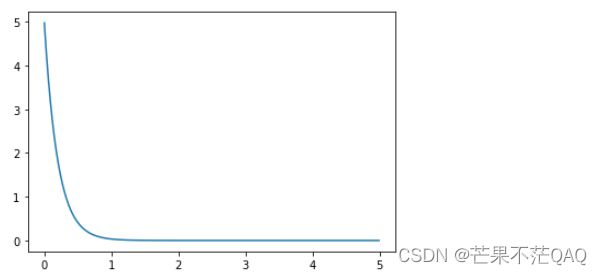
- 查看指数分布
import scipy
import matplotlib.pyplot as plt
import numpy as np
quantile = np.arange (0.001, 5, 0.01)
# (1/scale) * math.e ** (-x/scale)
y = scipy.stats.expon.pdf(quantile, scale=0.2)
plt.plot(quantile, y)
- 查看随机搜索后的参数
crf = rs.best_estimator_
print('best params:', rs.best_params_)
print('best CV score:', rs.best_score_)
print('model size: {:0.2f}M'.format(rs.best_estimator_.size_ / 1000000))

- 查看随机搜索中c1,c2分布情况
# .cv_results_是rs的属性,可查看搜索的参数组,每折训练结果等信息
_x = rs.cv_results_['param_c1']
_y = rs.cv_results_['param_c2']
_c = rs.cv_results_['mean_test_score']
fig = plt.figure()
fig.set_size_inches(6, 6)
ax = plt.gca()
ax.set_yscale('log')
ax.set_xscale('log')
ax.set_xlabel('C1')
ax.set_ylabel('C2')
ax.set_title("Randomized Hyperparameter Search CV Results (min={:0.3}, max={:0.3})".format(
min(_c), max(_c)
))
ax.scatter(_x, _y, c=_c, s=60, alpha=0.9)
