来自同济子豪兄的无私分享-关于YOLOv1模型的学习(一)
https://www.bilibili.com/video/BV15w411Z7LG?p=4https://www.bilibili.com/video/BV15w411Z7LG?p=4 https://www.bilibili.com/video/BV15w411Z7LG?p=4
https://www.bilibili.com/video/BV15w411Z7LG?p=4
感谢子豪兄的无私分享
感谢子豪兄的开源奉献精神
前言:之前利用yolov3模型,迫于没有好设备的现状,在不使用类似于pycharm或者VScode这种IDE的情况下,实现了在本地数据集上的运行。通过120个epoch,将7000多的loss降到了400左右
回顾:
我主要实现了对于本地数据集的读取以及相关信息提取。主要写了
1.文件改名函数
2.数据集分割函数
3.bbox反解函数
4.标注提取函数
并没有对网络结构做任何更改。虽然一般的建议是,不需要改变模型的结构,通过调整超参就可以得到符合我们预期的模型。但是,基于当前模型选择的多样,熟悉模型的结构还是很有必要
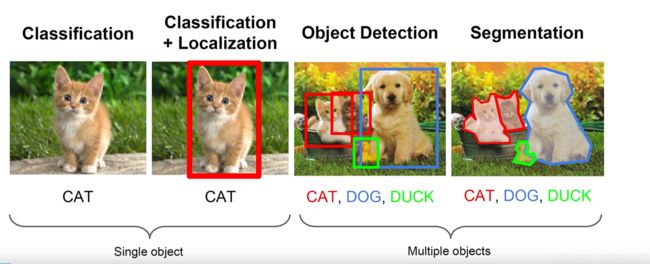
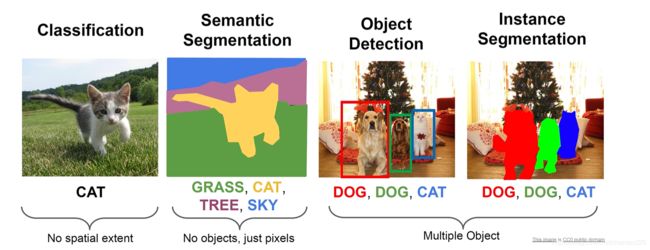
机器视觉
单目标:分类,定位
多目标:目标检测,分割
分割:语义分割,实力分割
做一些单词区分
detection 意味着你能看到目标。比如手势识别,骨干识别,keypoint detection
recognition 意味着你能认识目标。比如它是车,人,或动物。目标检测,object recognition
identification 意味着你能分辨目标。能找出同一类下的不同,比如它是什么车。
bounding box 边界框
目标检测的分类
有无“区域建议”,即是否主动提取候选框
YOLOV1的结构
background:基于VOC数据集,20个类别

PS:比如说在第一层卷积池化,到第二层卷积池化,为什么第二层卷积池化的输入变成了112*112*192。 112是因为池化的降维作用,192是因为图像的3通道以及上一层中filter的数量64,192 = 64*3
第三到第四层出现了级联卷积
最后输出7*7*30的有结构的张量,这其中包含多个结果,需要进一步解析
形式结构
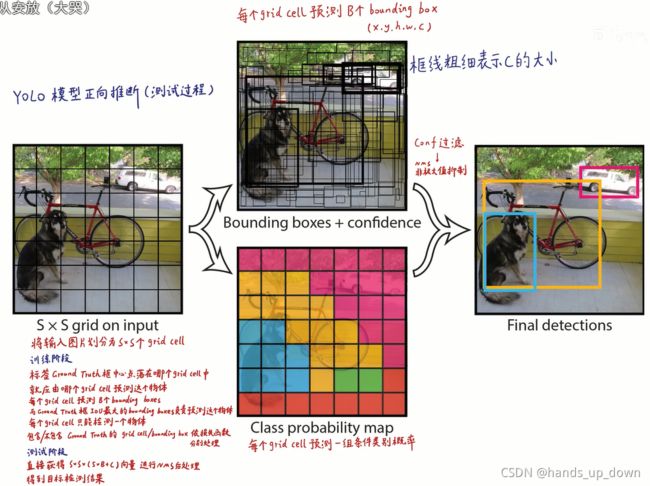
1.将图像按7*7划分网格
2.每个网格最终要预测两个候选框,无论大小,只要其中心落在网格内即可。返回的信息中包括置信度,即该预测框中是物体(object)的概率 P(object),用预测框线的粗细来表征
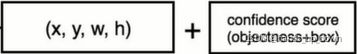
3.每个网格还预测一组条件类别概率,与相应的置信度一乘,就得到该类别的概率。这与概率论是一致的
条件类别概率如图

由此,我们也就得到了yolov1输出的7*7*30tensor的结构:30 = 2个勾选框*每个候选款的5条信息+20个类别条件概率(基于VOC数据集的20个类别)
如图所示

非常形象,每个1*1*30的向量就是1个grid cell的输出
总的来看,两阶段目标检测算法给出超过2000个区域建议,这远远高于YOLO这种单阶段算法。yolo的预测检测框的数量还是太少了,由此她的缺陷之一就是对于小目标和密集目标的识别率偏低。
预测结果的后处理
其流程如图

1.从输出的7*7*30 tensor中提取每个预测框的信息。前面已经说了,每个grid cell都给出两个bounding box,实质上就是给出两组同样格式的向量[bbox_x_center, bbox_y_center, bbox_height, bbox_weight, confidence_object].每个bbox都需要提取出一个20*1的向量,因为虽然说grid cell只给出一组20个条件类别概率,但是每个bbox 的置信度是不同的,都要去乘所属grid cell给出的条件类别概率。最终,我们得到98个20*1的向量。如图
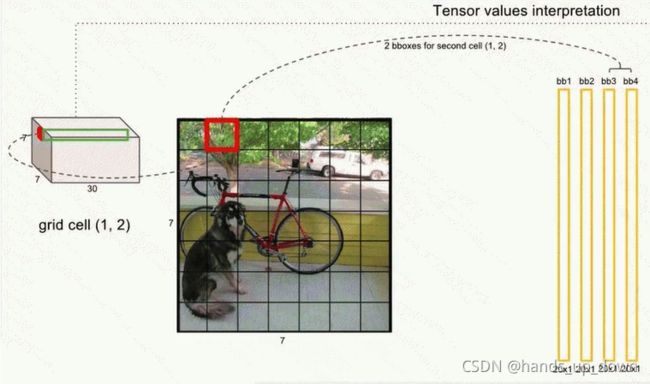
2.从98个预测框中挑选出我们需要的预测框。假设每个预测框的20*1向量的第一个元素是狗的概率,我们需要做的如图所示:
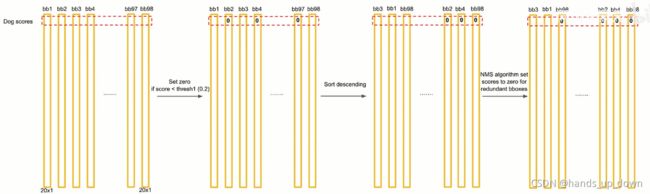
先是要![]() 设置一个门限值,概率至少要达到多少,才能生效
设置一个门限值,概率至少要达到多少,才能生效
然后![]() 排序,按照降序排列
排序,按照降序排列
之后 做NMS,处理冗余的预测框,处理上一步排序序列处于高位的数据
做NMS,处理冗余的预测框,处理上一步排序序列处于高位的数据
QUESTIONMARK:
我们排序是做的横向对比,表示在这98个预测框中狗的概率最高的有哪些,这并不代表这个预测框就是狗。比如bbox48的狗概率最高,但bbox48不一定是狗,因为在他自己的全类别概率中狗的概率不一定最高。
bbox是什么,是由全类别概率中的最大值来决定的
bbox是不是冗余的,需要做上述的横向对比(即多个bbox都选中了同一个目标,总归是只留一个)
我们看到,似乎是先处理冗余,再确定bbox的类别
3.如何进行NMS(non-maximum suppression),处理冗余检测框(选中同一个目标的检测框)
注意,上一步排序的结果表示,那些选中了目标的检测框通常排在前面,这当中既包括冗余框,也包括同一类别的目标。比如说图像中有两条狗
IoU:检测框的交并比。以此来判断检测框是否选中同一目标
有点类似于冒泡排序,按轮次进行比较,每轮比较完成之后,下一轮比较从下一个不为0的bbox开始。
经由我们前面的分析,此步骤只是在处理冗余预测框,因此剩下的检测框可能出现这样的情况,一个预测框选中了目标,一个预测框是空的 。
这没有关系,之后的处理才确定检测框选中目标的类别
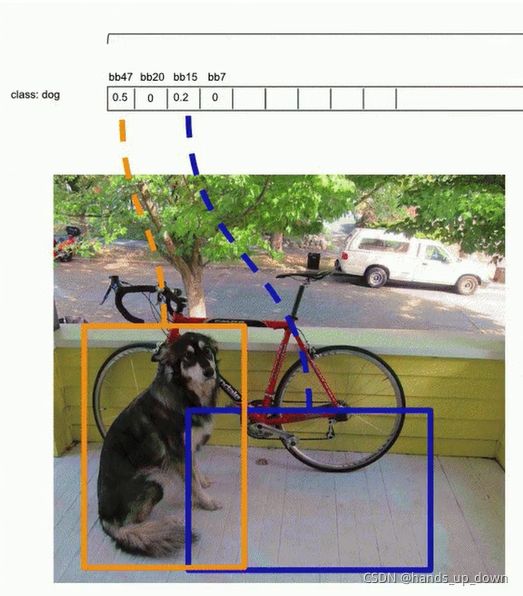
Tips:判断某一步的作用
以概率的threshold为依据,处理类别问题
以IoU为依据,处理冗余预测框问题
4.进行每一个bbox 20*1向量的纵向对比。
前面步骤已经将某一类别的同一目标的冗余清除
紧接着对纵向排序,取最大者。如图:

由此,我们就导出了推理阶段的结果
QUESTIONMARK:能不能先做纵向处理,再做横向处理???
肯定是不能的。如果是先纵向,每个预测框的处理都是孤立的,并且纵向处理之后就直接确定了这个框的类别,没有再做横向处理的可能了,也没有办法清理预测同一目标的冗余
训练阶段中LOSS的计算
Q:最多只能分出49类??
训练阶段的输出:和前面所讲的类似,区别就在于训练阶段不处理冗余检测框,输出每个grid cell的两个预测框,并给出相应的类别概率
现在已知,每个grid cell都有两个bbox:
1.由谁去拟合标注??以IoU为依据,谁与标注的IoU大,谁就拟合
2.未拟合的预测框应该做什么??尽量将相应类别的概率置0
3.每个grid cell什么时候去做拟合??当存在标注的中心点落在grid cell的时候。如果没有,则对应的两个预测框都进入未拟合状态
LOSS function的定义:
ground truth = 真实数据(即标注)



YOLO的 loss 的构建借助了残差,而在做分类项目的CNN时,我们一般使用误差。误差和残差的区分如下:
误差:即观测值与真实值的偏离,误差大小可以衡量测量的准确性,系统误差与测量方案有关
残差:观测值与拟合值的偏离,残差大小可以衡量预测的准确性,与数据本身的分布特性,回归方程的选择有关
反正要看一个模型是否合适,看误差;要看所取样本是否合适,看残差;
YOLO 的loss function 是基于回归思想来做的,分为5个部分:
基于回归思想应该怎么理解??
其中,一方面要给检测物体(拟合标注)的误差更高的权重,另一方面带上标的x表示预期输出

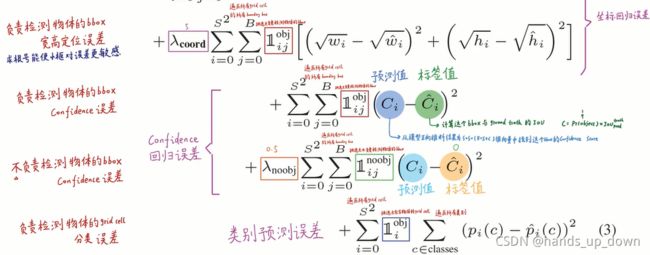
再论yolo1的Loss function:
经过后面对yolo2\yolo3的损失函数的研究,现在我大概明白了一些
首先,整个loss function是在平方和误差的基础上构建,每次计算Loss都需要遍历所有预测框
虽然原文以及子豪兄都没有讲或者是做明确说明,但我认为yolo1是存在正负样本的选区的,每种误差项都包含0、1参数,选取标准十分简单,就是比较同属于一个grid cell的两个预测框的置信度的大小,大的负责预测物体,小的不负责拟合标注
我之前就有一个问题:为什么一个grid cell只能预测一个类???
现在我的判断是,由于loss function中对于置信度误差的设计,它会将负责拟合标注的预测框的置信度向1收敛,而不负责的预测框则向0收敛,在正常训练的情况下必然导致一个结果,不负责拟合标注的预测框的置信度越来越小。
而在预测后处理阶段,我们会先设置一个置信度阈值以过滤置信度过低、不能被称之为预测框的bbox,这样一来一个grid cell最多只剩下一个预测框可用,如果这个预测框不是冗余,那么这个grid cell就成功预测了一个类
TIPS:我又想了一点,我的某些疑问其实是脱离了yolo1的设计,模型的收敛方向我认为应该是由loss function来决定的,如果loss function没有涉及相关的误差项或者某些参数的收敛方向,那么他就肯定达不到那样的效果,你不能对模型有不切实际的期待。应该说,我的某些疑问是用于现在修改loss function的,而不是解释现有的模型
从前向网络的结构来看,他其实是允许同一个grid cell的不同预测框预测不同的目标,并没有施加直接的限制,也不存在一个grid cell只能预测一个类的限制。不然的话,我们输出的所有预测框怎么会使这样

上图是我们自己训练的一个很离谱的结果,至少可以直接看出的一点是cat和dog两个预测框不应该通过NMS,无论是哪一个类别
再仔细看了yolo1关于后处理的原理,我们在进行两次阈值筛选的时候,一共要进行20轮
每次假设所有的预测框都是某一类,先做置信度阈值筛选,再做nms阈值筛选
不同类别之间是不进行比较的,不管是置信度还是nms,所以yolo1对于不同类别的预测框的位置、重叠是没有限制的
包括预测后处理也没有直接的限制,预测后处理只是对模型的输出结果做了两次筛选
真正能对模型训练方向起作用的只有loss function,而且也不是硬编码那样直接的规则,我们还只能利用loss function逐步对我们的目标进行逼近
再仔细分析yolo1的loss function的结构:基于我当前的理解
定位回归误差只是为了让预测框的尺寸和位置更加接近标注框的尺寸和位置
置信度误差的目标在于使同一个grid cell的两个预测框的置信度一个朝1一个朝0收敛,这样一来两个预测框谁负责拟合标注就更为清晰
分类误差的目标在于使输出的条件类别概率更接近标注的概率分布
QUESTIONMARK:两个bbox的confidence 都很高或者都很低
感受野:之前的理解是错的,这TM的是输出的feature map的尺寸
CVPR2016报告
原作者描述的YOLOv1的原理:
prediction stage
1.split the image into the grid
2.each cell predicts boxes and confidences:P(object)就是说预测框包含物体的概率
3.each cell also predicts a class probability(一组条件类别概率) which conditioned on object:P(concern class|object)
4.combine the box and class predictions
5.do NMS and threshold detections
提到和RCNN的区别:
RCNN较之YOLOv1,有更大的可能将背景识别为物体,虽然他有更多的检测框。怎么实现的呢??还有就是YOLO的泛化能力会更强,为什么?
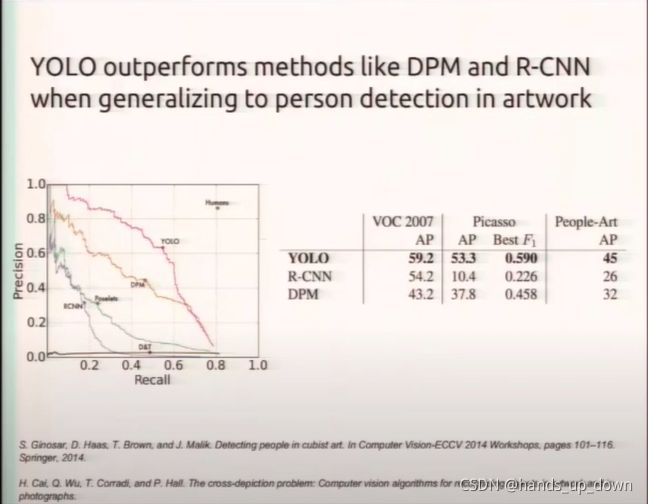
一个解释是,RCNN每个预测框的计算是独立的,管中窥豹;而YOLO隐式地从整个图像中学习特征。怎么理解?
training stage:
1.match example to the right cell.从标注中提取bbox的信息,选择一个预测框来匹配物体(拟合)

2.adjust the cell's class prediction,以IoU来决定选择哪一个预测框来拟合标注
这里又提到了当前的grid cell划分下,最多只能识别49类物体。
理由是一个grid cell一次只能表示一个类。因为他的类别由从属于她的标注决定
有人又有另一个提法,是说最多同时预测49类
yolo2就有了anchor来优化bbox的尺寸,有一些先验的尺寸可供使用。比如宽胖的框预测汽车,高瘦的框预测行人
3.find the best one, adjust it, increase the confidence
前面也说了,拟合标注的预测框的置信度增加,不拟合的将置信度置0
4.some cell don't have any ground truth detection(ground truth:真实数据,标注)

现在,yolo的创造者专注于yolo在某些边缘设备上的部署
边缘设备:这是一个相对于物联网的概念,在物联网中,边缘设备的核心是充当入口点或出口点,并控制两个网络之间边界或周边的数据流。对于使用不同协议的网络,除了连接之外,边缘设备还提供流量转换。
传统的边缘设备包括边缘路由器、路由交换机、防火墙、多路复用器和其他广域网(WAN)设备。
现在像安防摄像头、自动驾驶自行车、自主飞行无人机等都可以被视作边缘设备、
稚晖君多次在他的项目中使用华为的边缘计算平台,昇腾芯片
延伸阅读
《object detection in 20 years: a survey》这里为什么又是用的detection?