基于Pytorch实现图像二分法(带源码)
图像二分法
- 使用模型 resnet18
- 代码 ai_warehouse/PytorchLearn/learn/twoCategory
- imageTrain为训练代码 imageTc为验证模型代码
- 实现功能:进行训练二分法模型并且保存,再使用此模型进行验证
流程解读
1.数据预处理
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
2.数据的读取
# 获取路径
BASEDIR = os.path.dirname(os.path.abspath(__file__))
# 获取data数据集的路径
data_dir = os.path.abspath(os.path.join(BASEDIR, "..", "..", "data", "hymenoptera_data"))
# 从目录中取出数据集 分训练数据集和验证数据集 dataset返回list不能作为模型的输入
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x]) for x in ['train', 'val']}
# 使用DataLoader进行数据集的加载torch.utils.data.DataLoader类可以将list类型的输入数据封装成Tensor数据格式,以备模型使用
dataloders = {x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=4,
shuffle=True,
num_workers=4) for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
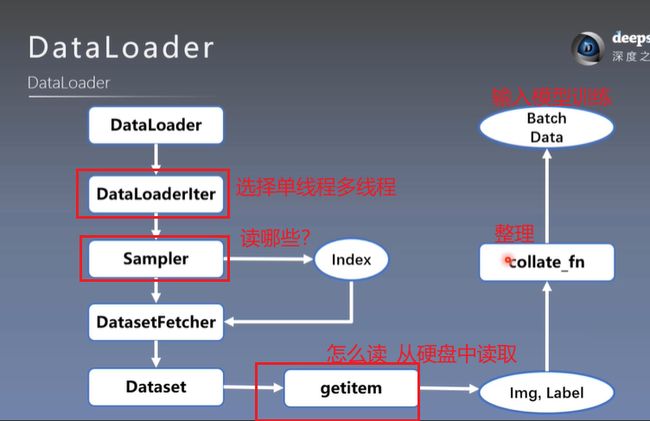
DataLoader,Dataset之间的关系
3.进行模型的选择是使用cpu还是Gpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
4.设置所使用的模型
model_ft = models.resnet18(pretrained=True)
num_ftrs = model_ft.fc.in_features
# PyTorch的nn.Linear()是用于设置网络中的全连接层的
model_ft.fc = nn.Linear(num_ftrs, 2)
if torch.cuda.is_available():
model_ft = model_ft.cuda()
else:
model_ft.cpu()
5.设置损失函数
criterion = nn.CrossEntropyLoss()
6.优化函数
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
7.学习率变化策略
scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
8.传入模型进行训练
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
viz = Visdom(env='my_wind')
best_model_wts = model.state_dict()
best_acc = 0.0
viz.line([[0.0,0.0]],
[0.],
win="train loss",
opts=dict(tittle='train_loss'))
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
scheduler.step()
model.train(True) # Set model to training mode
else:
model.train(False) # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0.0
# Iterate over data.
for data in dataloders[phase]:
# get the inputs
inputs, labels = data
# wrap them in Variable
if torch.cuda.is_available():
inputs = Variable(inputs.cuda())
labels = Variable(labels.cuda())
else:
inputs, labels = Variable(inputs), Variable(labels)
# zero the parameter gradients
optimizer.zero_grad()
# forward
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item()
running_corrects += torch.sum(preds == labels.data).to(torch.float32)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects / dataset_sizes[phase]
epoch_acc2 = epoch_acc.cpu().numpy()
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
if phase == 'train':
viz.line([[epoch_loss,epoch_acc2]],
[epoch],
win="train loss",
update='append')
viz.images(inputs,win="x")
# deep copy the model
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model.state_dict()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
path_state_dict = "./model_save.pkl"
# load best model weights
model.load_state_dict(best_model_wts)
# 对最好的模型进行保存
torch.save(best_model_wts,path_state_dict)
return model
参考资料
可视化工具Visdom
-
安装
pip install visdom -
安装成功
-
启动
python -m visdom.server 启动成功

若启动的时候报下载文件超时
- 访问:
http://localhost:8097
-
使用
-
实时显示曲线绘制方法
from visdom import Visdom ''' 单条追踪曲线设置 ''' viz = Visdom() # 初始化visdom类 viz.line([0.], ## Y的第一个点坐标 [0.], ## X的第一个点坐标 win="train loss", ##窗口名称 opts=dict(title='train_loss') ## 图像标例 ) #设置起始点 ''' 模型数据 ''' viz.line([1.], ## Y的下一个点坐标 [1.], ## X的下一个点坐标 win="train loss", ## 窗口名称 与上个窗口同名表示显示在同一个表格里 update='append' ## 添加到上一个点后面 ) -
多条曲线绘制
from visdom import Visdom ''' 多条曲线绘制 实际上就是传入y值时为一个向量 ''' viz = Visdom(env='my_wind') # 注意此时我已经换了新环境 #设置起始点 viz.line([[0.0,0.0]], ## Y的起始点 [0.], ## X的起始点 win="test loss", ##窗口名称 opts=dict(title='test_loss') ## 图像标例 ) ''' 模型数据 ''' viz.line([[1.1,1.5]], ## Y的下一个点 [1.], ## X的下一个点 win="test loss", ## 窗口名称 update='append' ## 添加到上一个点后面 ) -
图像显示
from visdom import Visdom import numpy as np image = np.random.randn(6, 3, 200, 300) # 此时batch为6 viz = Visdom(env='my_image') # 注意此时我已经换了新环境 viz.images(image, win='x') -
可视化数据集
from visdom import Visdom import numpy as np import torch from torchvision import datasets, transforms # 注意数据集路径 train_loader = torch.utils.data.DataLoader(datasets.MNIST( r'D:\data', train=True, download=False, transform=transforms.Compose( [transforms.ToTensor()])),batch_size=128,shuffle=True) sample=next(iter(train_loader)) # 通过迭代器获取样本 # sample[0]为样本数据 sample[1]为类别 nrow=16表示每行显示16张图像 viz = Visdom(env='my_visual') # 注意此时我已经换了新环境 viz.images(sample[0],nrow=16,win='mnist',opts=dict(title='mnist'))Visdom使用方法参考资料
-
使用保存的模型进行验证
源码
# -*- coding: utf-8 -*-
"""
使用训练好的模型区分蜜蜂蚂蚁
# @file name : resnet_inference.py
# @author : TingsongYu https://github.com/TingsongYu
# @date : 2019-11-16
# @brief : inference demo
"""
import os
import time
import torch.nn as nn
import torch
import torchvision.transforms as transforms
from PIL import Image
from matplotlib import pyplot as plt
import torchvision.models as models
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = torch.device("cuda")
# config
vis = True
# vis = False
vis_row = 4
norm_mean = [0.485, 0.456, 0.406]
norm_std = [0.229, 0.224, 0.225]
# 预处理
inference_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 数据标签
classes = ["ants", "bees"]
def img_transform(img_rgb, transform=None):
"""
将数据转换为模型读取的形式
:param img_rgb: PIL Image
:param transform: torchvision.transform
:return: tensor
"""
if transform is None:
raise ValueError("找不到transform!必须有transform对img进行处理")
img_t = transform(img_rgb)
return img_t
def get_img_name(img_dir, format="jpg"):
"""
获取文件夹下format格式的文件名
:param img_dir: str
:param format: str
:return: list
"""
file_names = os.listdir(img_dir)
img_names = list(filter(lambda x: x.endswith(format), file_names))
if len(img_names) < 1:
raise ValueError("{}下找不到{}格式数据".format(img_dir, format))
return img_names
def get_model(m_path, vis_model=False):
resnet18 = models.resnet18()
num_ftrs = resnet18.fc.in_features
resnet18.fc = nn.Linear(num_ftrs, 2)
checkpoint = torch.load(m_path)
resnet18.load_state_dict(torch.load(m_path))
if vis_model:
from torchsummary import summary
summary(resnet18, input_size=(3, 224, 224), device="cpu")
return resnet18
if __name__ == "__main__":
# =======================================获取文件路径===========================================
BASEDIR = os.path.dirname(os.path.abspath(__file__))
data_dir = os.path.abspath(os.path.join(BASEDIR, "..", "..", "data", "hymenoptera_data"))
if not os.path.exists(data_dir):
raise Exception("\n{} 不存在,请下载 07-02-数据-模型finetune.zip 放到\n{} 下,并解压即可".format(
data_dir, os.path.dirname(data_dir)))
img_dir = os.path.join(data_dir, "val", "bees")
# model_path = os.path.abspath(os.path.join(BASEDIR, "..", "..", "data", "resnet_checkpoint_14_epoch.pkl"))
model_path = os.path.abspath(os.path.join(BASEDIR, "..", "..", "learn", "twoCategory","model_save.pkl"))
if not os.path.exists(model_path):
raise Exception("\n{} 不存在,请下载 08-01-数据-20200724.zip 放到\n{} 下,并解压即可".format(
model_path, os.path.dirname(model_path)))
time_total = 0
img_list, img_pred = list(), list()
# ==================================处理数据集================================
# 1. data 获取图片名
img_names = get_img_name(img_dir)
num_img = len(img_names)
# 2. model
resnet18 = get_model(model_path, True)
resnet18.to(device)
# 确定状态
resnet18.eval()
# 不需要计算梯度
with torch.no_grad():
for idx, img_name in enumerate(img_names):
path_img = os.path.join(img_dir, img_name)
# step 1/4 : path --> img
img_rgb = Image.open(path_img).convert('RGB')
# step 2/4 : img --> tensor
img_tensor = img_transform(img_rgb, inference_transform)
img_tensor.unsqueeze_(0)
img_tensor = img_tensor.to(device)
# step 3/4 : tensor --> vector
time_tic = time.time()
outputs = resnet18(img_tensor)
time_toc = time.time()
# step 4/4 : visualization
_, pred_int = torch.max(outputs.data, 1)
pred_str = classes[int(pred_int)]
if vis:
img_list.append(img_rgb)
img_pred.append(pred_str)
if (idx+1) % (vis_row*vis_row) == 0 or num_img == idx+1:
for i in range(len(img_list)):
plt.subplot(vis_row, vis_row, i+1).imshow(img_list[i])
plt.title("predict:{}".format(img_pred[i]))
plt.show()
plt.close()
img_list, img_pred = list(), list()
time_s = time_toc-time_tic
time_total += time_s
print('{:d}/{:d}: {} {:.3f}s '.format(idx + 1, num_img, img_name, time_s))
print("\ndevice:{} total time:{:.1f}s mean:{:.3f}s".
format(device, time_total, time_total/num_img))
if torch.cuda.is_available():
print("GPU name:{}".format(torch.cuda.get_device_name()))