随机森林的java算法_spark 随机森林算法案例实战
随机森林算法
由多个决策树构成的森林,算法分类结果由这些决策树投票得到,决策树在生成的过程当中分别在行方向和列方向上添加随机过程,行方向上构建决策树时采用放回抽样(bootstraping)得到训练数据,列方向上采用无放回随机抽样得到特征子集,并据此得到其最优切分点,这便是随机森林算法的基本原理。图 3 给出了随机森林算法分类原理,从图中可以看到,随机森林是一个组合模型,内部仍然是基于决策树,同单一的决策树分类不同的是,随机森林通过多个决策树投票结果进行分类,算法不容易出现过度拟合问题。
图 3. 随机森林示意图


随机森林算法案例实战
本节将通过介绍一个案例来说明随机森林的具体应用。一般银行在货款之前都需要对客户的还款能力进行评估,但如果客户数据量比较庞大,信贷审核人员的压力会非常大,此时常常会希望通过计算机来进行辅助决策。随机森林算法可以在该场景下使用,例如可以将原有的历史数据输入到随机森林算法当中进行数据训练,利用训练后得到的模型对新的客户数据进行分类,这样便可以过滤掉大量的无还款能力的客户,如此便能极大地减少信货审核人员的工作量。
假设存在下列信贷用户历史还款记录:
表 2. 信贷用户历史还款数据表
记录号是否拥有房产(是/否)婚姻情况(单身、已婚、离婚)年收入(单位:万元)是否具备还款能力(是、否)
10001
否
已婚
10
是
10002
否
单身
8
是
10003
是
单身
13
是
……
….
…..
….
……
11000
是
单身
8
否
上述信贷用户历史还款记录被格式化为 label index1:feature1 index2:feature2 index3:feature3 这种格式,例如上表中的第一条记录将被格式化为 0 1:0 2:1 3:10,各字段含义如下:
是否具备还款能力 是否拥有房产 婚姻情况,0 表示单身、 年收入
0 表示是,1 表示否 0 表示否,1 表示是 1 表示已婚、2 表示离婚 填入实际数字
0 1:0 2:1 3:10
将表中所有数据转换后,保存为 sample_data.txt,该数据用于训练随机森林。测试数据为:
表 3. 测试数据表
是否拥有房产(是/否)婚姻情况(单身、已婚、离婚)年收入(单位:万元)
否
已婚
12
如果随机森林模型训练正确的话,上面这条用户数据得到的结果应该是具备还款能力,为方便后期处理,我们将其保存为 input.txt,内容为:
0 1:0 2:1 3:12
将 sample_data.txt、input.txt 利用 hadoop fs –put input.txt sample_data.txt /data 上传到 HDFS 中的/data 目录当中,再编写如清单 9 所示的代码进行验证
清单 9. 判断客户是否具有还贷能力
package cn.mlimportorg.apache.spark.SparkConfimportorg.apache.spark.SparkContextimportorg.apache.spark.mllib.util.MLUtilsimportorg.apache.spark.mllib.regression.LabeledPointimportorg.apache.spark.rdd.RDDimportorg.apache.spark.mllib.tree.RandomForestimportorg.apache.spark.mllib.tree.model.RandomForestModelimportorg.apache.spark.mllib.linalg.Vectors
object RandomForstExample {defmain(args: Array[String]) {
val sparkConf= new SparkConf().setAppName("RandomForestExample").
setMaster("spark://sparkmaster:7077")
val sc=new SparkContext(sparkConf)
val data: RDD[LabeledPoint]= MLUtils.loadLibSVMFile(sc, "/data/sample_data.txt")
val numClasses= 2val featureSubsetStrategy= "auto"val numTrees= 3val model: RandomForestModel=RandomForest.trainClassifier(
data, Strategy.defaultStrategy("classification"),numTrees,
featureSubsetStrategy,new java.util.Random().nextInt())
val input: RDD[LabeledPoint]= MLUtils.loadLibSVMFile(sc, "/data/input.txt")
val predictResult= input.map { point =>val prediction=model.predict(point.features)
(point.label, prediction)
}//打印输出结果,在 spark-shell 上执行时使用
predictResult.collect()//将结果保存到 hdfs //predictResult.saveAsTextFile("/data/predictResult")
sc.stop()
}
}
上述代码既可以打包后利用 spark-summit 提交到服务器上执行,也可以在 spark-shell 上执行查看结果. 图 10 给出了训练得到的RadomForest 模型结果,图 11 给出了 RandomForest 模型预测得到的结果,可以看到预测结果与预期是一致的。
图 10. 训练得到的 RadomForest 模型
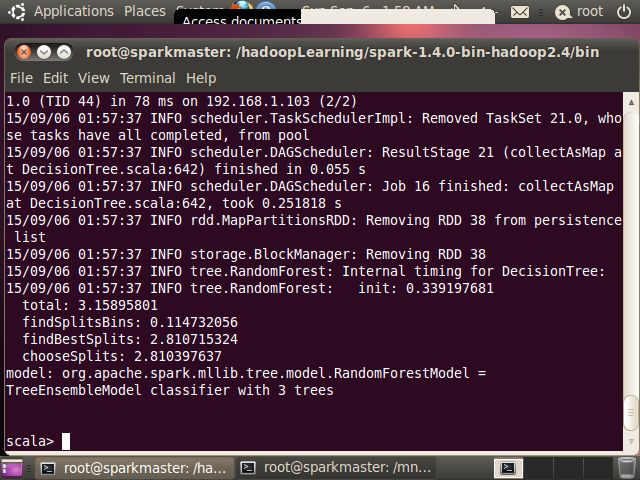
图 11. collect 方法返回的结果

摘自:https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-random-forest/index.html