机器学习算法之贝叶斯
目录
文章目录
- 目录
- 一、简单实例
- 二、朴素贝叶斯
- 三、高斯贝叶斯
- 四、综合实例
- 总结
一、简单实例
import numpy as np
X=np.array([[0,1,0,1],#模拟天气特征
[1,1,1,0],
[0,1,1,0],
[0,0,0,1],
[0,1,1,0],
[0,1,0,1],
[1,0,0,1]])
y=np.array([0,1,1,0,1,0,0])
counts={}#计算不同分类每个特征为1的数量
for label in np.unique(y):
counts[label]=X[y==label].sum(axis=0)
print("feature counts:\n{}".format(counts))
显示结果

import numpy as np
X=np.array([[0,1,0,1],#模拟天气特征
[1,1,1,0],
[0,1,1,0],
[0,0,0,1],
[0,1,1,0],
[0,1,0,1],
[1,0,0,1]])
y=np.array([0,1,1,0,1,0,0])
counts={}#计算不同分类每个特征为1的数量
for label in np.unique(y):
counts[label]=X[y==label].sum(axis=0)
print("feature counts:\n{}".format(counts))
显示结果

Another_day=[[1,1,0,1]]#假设另外一天刮北风,闷热,天气预报有雨但不多云
pre2=clf.predict(Another_day)
print('\n\n\n')
if pre2==[1]:
print("it is rainy")
else:
print("it is not rainy")
显示结果
![]()
二、朴素贝叶斯
贝努利朴素贝叶斯(又做二项分布或0-1分布)(1)
from sklearn.datasets import make_blobs#导入数据生成器
from sklearn.model_selection import train_test_split#导入数据集拆分工具
X,y=make_blobs(n_samples=500,centers=5,random_state=8)#生成500个样本,5个分类的数据集
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=8)#将数据集拆分成训练集和测试集
nb=BernoulliNB()#使用贝努利贝叶斯拟合数据
nb.fit(X_train,y_train)
print('训练集模型得分:{:.3f}'.format(nb.score(X_train,y_train)))
print('测试集模型得分:{:.3f}'.format(nb.score(X_test,y_test)))
显示结果
![]()
贝努利朴素贝叶斯(又做二项分布或0-1分布)(2)
import matplotlib.pyplot as plt#导如画图工具
x_min,x_max=X[:,0].min()-0.5,X[:,0].max()+0.5#导入数据集拆分工具
y_min,y_max=X[:,1].min()-0.5,X[:,1].max()+0.5
xx,yy=np.meshgrid(np.arange(x_min,x_max,.02),#用不同背景颜色表示不同分类
np.arange(y_min,y_max, .02))
z=nb.predict(np.c_[(xx.ravel(),yy.ravel())]).reshape(xx.shape)
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
plt.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=plt.cm.cool,edgecolor='k')#将训练集和测试集用散点图表示
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=plt.cm.cool,marker='*',edgecolor='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title('Classifier:BernoulliNB')
plt.show()
显示结果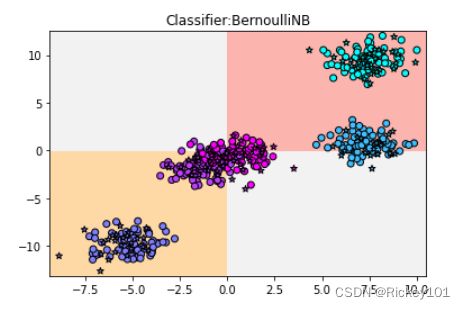
导入多(二)项式朴素贝叶斯(有错误是因为输入的X值应该非负)
from sklearn.naive_bayes import MultinomialNB
mnb=MultinomialNB()
mnb.fit(X_train,y_train)
mnb.score(X_test,y_test)
显示结果
![]()
解决办法:导入数据预处理工具MinMaxScaler
from sklearn.naive_bayes import MultinomialNB
from sklearn.preprocessing import MinMaxScaler#导入数据预处理工具MinMaxScaler
scaler=MinMaxScaler()#使用MinMaxScaler对数据进行预处理,使数据全部为非负值
scaler.fit(X_train)
X_train_scaled=scaler.transform(X_train)
X_test_scaled=scaler.transform(X_test)
mnb=MultinomialNB()#使用多项式朴素贝叶斯拟合经过预处理之后的数据
mnb.fit(X_train_scaled,y_train)
print('{:.3f}'.format(mnb.score(X_test_scaled,y_test)))
显示结果
0.320
z=mnb.predict(np.c_[(xx.ravel(),yy.ravel())]).reshape(xx.shape)
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
plt.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=plt.cm.cool,edgecolor='k')
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=plt.cm.cool,marker='*',edgecolor='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title('Classifier:MultinomialNB')
plt.show()
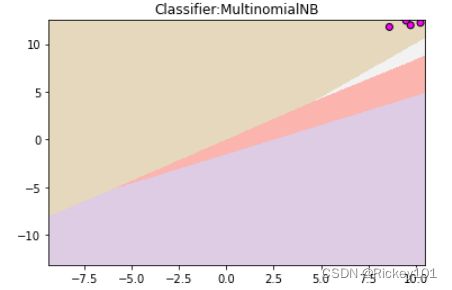
三、高斯贝叶斯
#高斯贝叶斯(1)
from sklearn.naive_bayes import GaussianNB
gnb=GaussianNB() #使用高斯贝叶斯拟合数据
gnb.fit(X_train,y_train)
print('{:.3f}'.format(gnb.score(X_test,y_test)))
显示结果
0.968
高斯贝叶斯(2)图像演示工作过程
z=gnb.predict(np.c_[(xx.ravel(),yy.ravel())]).reshape(xx.shape)#用不同的色块表示不同的类型
plt.pcolormesh(xx,yy,z,cmap=plt.cm.Pastel1)
plt.scatter(X_train[:,0],X_train[:,1],c=y_train,cmap=plt.cm.cool,edgecolor='k')#将训练集和测试集用散点图表示
plt.scatter(X_test[:,0],X_test[:,1],c=y_test,cmap=plt.cm.cool,marker='*',
edgecolor='k')
plt.xlim(xx.min(),xx.max())
plt.ylim(yy.min(),yy.max())
plt.title('Classifier:GaussianNB')
plt.show()
显示结果
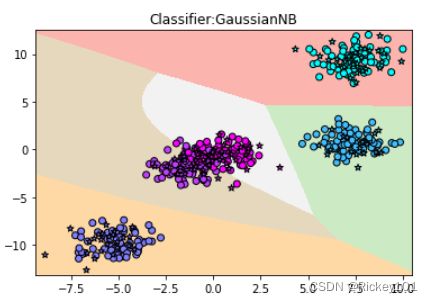
四、综合实例
#导入威斯康星乳腺肿瘤数据集
from sklearn.datasets import load_breast_cancer
cancer=load_breast_cancer()
X,y=cancer.data,cancer.target#将数据集的数值和分类目标赋值给x和y
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=38)#使用数据集拆分工具
gnb=GaussianNB()#使用高斯朴素贝叶斯拟合数据
gnb.fit(X_train,y_train)
print('训练集得分:{:.3f}'.format(gnb.score(X_train,y_train)))
print('测试集得分:{:.3f}'.format(gnb.score(X_test,y_test)))
显示结果
![]()
#高斯朴素贝叶斯学习曲线
from sklearn.model_selection import learning_curve #导入学习曲线库
from sklearn.model_selection import ShuffleSplit#导入随机拆分工具
def plot_learning_curve(estimator,title,X,y,ylim=None,cv=None,
n_jobs=1,train_sizes=np.linspace(.1,1.0,5)):#定义一个函数绘制学习曲线
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes,train_scores,test_scores=learning_curve(
estimator,X,y,cv=cv,n_jobs=n_jobs,train_sizes=train_sizes)
train_scores_mean=np.mean(train_scores,axis=1)
test_scores_mean=np.mean(test_scores,axis=1)
plt.grid()
plt.plot(train_sizes,train_scores_mean,'o-',color="r",
label="Training score")
plt.plot(train_sizes,test_scores_mean,'o-',color="g",
label="Cross-Validation score")
plt.legend(loc="lower right")
return plt
title="Learning Curves(Naive Bayes)"
cv=ShuffleSplit(n_splits=100,test_size=0.2,random_state=0)#设定拆分数量
estimator=GaussianNB()#设定模型为高斯朴素贝叶斯
plot_learning_curve(estimator,title,X,y,ylim=(0.9,1.01),cv=cv,n_jobs=4)#调用我们定义好的函数
plt.show()
显示结果
总结
例如:以上就是今天要讲的内容,本文仅仅简单介绍了机器学习算法之贝叶斯算法的使用,而sklearn库能提供了大量能使我们快速便捷地处理数据的算法。