第三章 决策树分类及两种可视化方法
前言
学习数据挖掘,用于记录练习和回顾
一、红酒数据集
数据下载链接:https://archive.ics.uci.edu/ml/datasets/Wine
二、使用步骤
1.引入库
import pandas as pd
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn import tree
import matplotlib.pyplot as plt
from sklearn.tree import export_graphviz
2.读入数据
wine_data = pd.read_csv("./UCI/wine/wine.data", header="infer")
X, Y = wine_data.iloc[:, 1:], wine_data.iloc[:, 0] # 把分类属性与常规属性分开
# 75%训练集,25%测试集,75%训练标签,25%测试标签
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.25, random_state=0)
3.决策树训练
dec = tree.DecisionTreeClassifier(criterion='gini') # 信息增益entropy
dec = dec.fit(x_train, y_train)
predictions = dec.predict(x_test)
print("决策树:\n" + classification_report(y_test, predictions))
print("准确率:", dec.score(x_test, y_test))
4.可视化
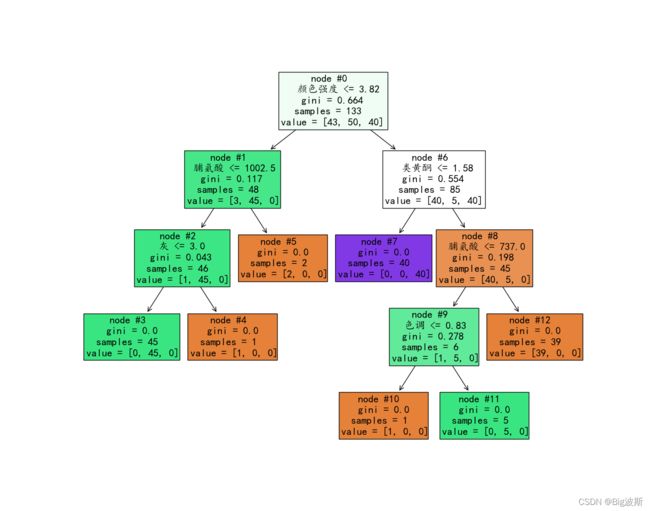
1 、画树方法1
plt.figure(figsize=(14, 11))
tree.plot_tree(dec, filled=True, fontsize='16', node_ids=True,
feature_names=['酒精', '苹果酸', '灰', '灰的碱性', '镁', '总酚', '类黄酮', '非黄酮类酚类',
'原花青素', '颜色强度', '色调', '稀释葡萄酒的OD280/OD315', '脯氨酸'])
plt.rcParams['font.sans-serif'] = ['Kaiti'] # 解决乱码
plt.show()
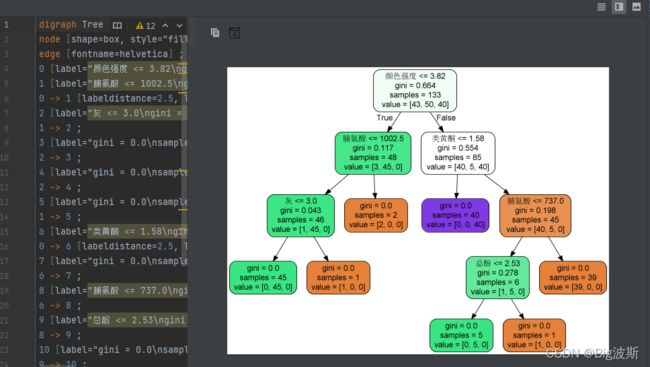
2、画树方法2
export_graphviz(dec,
out_file="./tree.dot",
feature_names=["酒精","苹果酸","灰","灰的碱性",'镁', '总酚', '类黄酮', '非黄酮类酚类',
"原花青素", "颜色强度","色调","稀释葡萄酒的OD280/OD315","脯氨酸" ],
filled=True,
rounded=True,
)
画图文件代码形式和图片形式