LPIPS指标在SRGAN的评估
LPIPS指标在SRGAN的评估
文章目录
- LPIPS指标在SRGAN的评估
- 前言
- 一、简述LPIPS
- 二、简述SRGAN
- 三、代码部分-将LPIPS指标在SRGAN的评估
-
- 1.先放修改后test_benchmask完整的代码
- 2.添加部分详细的介绍
-
- 2.1引入lpips库
- 2.2 加入loss_fn
- 2.3 保存数据
- 总结
前言
SRGAN认为传统的图像评估方法(例如PSNR、SSIM)并没有很好的体现人的感官视觉,也就是说并不是PSNR的值越高。视觉上的效果看起来就更好。
所以论文采用了生成对抗网络应用于图像的超分辨率上,目标在于生成一个真实的、接近于自然流形图像的SR图片。但文中的指标还是采用了PSNR,以及SSIM,以及主观的MOS。近年来有一种指标,用于同图像的生成上,即图像感知相似度指标 (LPIPS),相比于PSNR、SSIM,基于学习的感知相似度度量(即PLPIPS)要更符合人类的感知。
鉴于目前没有人将LPIPS这个指标用在SRGAN上,本博客主要简述如何使用LPIPS对SRGAN的结果进行评估(理论的东西后续有空也会更新)

一、简述LPIPS
深度特征作为感知度量的无理由的有效性——LPIPS。文章通过大量的实验分析了使用深度特征度量图像相似度的有效性,题目中所说的“Unreasonable Effectiveness”指在监督、自监督、无监督模型上得到的深度特征在模拟低层次感知相似性上都比以往广泛使用的方法(例如L2、SSIM等)的表现要好,而且适用于不同的网络结构(SqueezeNet、AlexNet、VGG)。文章开头便附图表明了:广泛使用的L2/PSNR、SSIM、FSIM指标在判断图片的感知相似度时给出了与人类感知相违背的结论,而相比之下,基于学习的感知相似度度量要更符合人类的感知。
LPIPS论文
LPIPS开源代码链接
某个博主的详细介绍

二、简述SRGAN
作者总结了最近的图像超分辨率的工作,认为大都集中于以均方差(MSE)作为损失函数,造成生成图像过于平滑,缺少高频细节,看起来觉得不真实,感到不舒服。所以提出了基于生成式对抗网络的网络结构,作者认为这是生成式对抗网络第一次应用于4倍下采样图像的超分辨重建工作。
SRGAN利用感知损失(perceptual loss),由对抗损失(adversarial loss)和内容损失(content loss)组成。
对抗损失将图像映射到高位流形空间,并用判别网络去判别重建后的图像和原始图像。而内容损失则是基于感觉相似性(perceptual similarity)而非像素相似性(pixel similarity),所以生成的高分辨图像视觉效果更好。
SRGAN论文
SRGAN-pytorch代码
某个博主的详细介绍
三、代码部分-将LPIPS指标在SRGAN的评估
1.先放修改后test_benchmask完整的代码
代码如下(示例):
import argparse
import os
from math import log10
import numpy as np
import pandas as pd
import torch
import torchvision.utils as utils
from torch.autograd import Variable
from torch.utils.data import DataLoader
from tqdm import tqdm
from lpips.lpips import lpips
import pytorch_ssim
from data_utils import TestDatasetFromFolder, display_transform
from model import Generator
parser = argparse.ArgumentParser(description='Test Benchmark Datasets')
parser.add_argument('--upscale_factor', default=4, type=int, help='super resolution upscale factor')
parser.add_argument('--model_name', default='netG_epoch_4_100.pth', type=str, help='generator model epoch name')
opt = parser.parse_args()
UPSCALE_FACTOR = opt.upscale_factor
MODEL_NAME = opt.model_name
#
results = {'Set5': {'psnr': [], 'ssim': [], 'lpipsm': []},
'Set14': {'psnr': [], 'ssim': [], 'lpipsm': []},
'BSD100': {'psnr': [], 'ssim': [], 'lpipsm': []},
'Urban100': {'psnr': [], 'ssim': [], 'lpipsm': []},
'SunHays80': {'psnr': [], 'ssim': [], 'lpipsm': []}}
model = Generator(UPSCALE_FACTOR).eval()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
model = model.cuda()
model.load_state_dict(torch.load('epochs/' + MODEL_NAME)) # torch.load_state_dict()函数就是用于将预训练的参数权重加载到新的模型之中
model = model.eval()
test_set = TestDatasetFromFolder('data/test', upscale_factor=UPSCALE_FACTOR)
test_loader = DataLoader(dataset=test_set, num_workers=4, batch_size=1, shuffle=False)
test_bar = tqdm(test_loader, desc='[testing benchmark datasets]')
out_path = 'benchmark_results/SRF_' + str(UPSCALE_FACTOR) + '/'
if not os.path.exists(out_path):
os.makedirs(out_path)
loss_fn = lpips.LPIPS(net='alex')
loss_fn = loss_fn.to(device)
with torch.no_grad():
for image_name, lr_image, hr_restore_img, hr_image in test_bar:
image_name = image_name[0]
if torch.cuda.is_available():
lr_image = lr_image.cuda()
hr_image = hr_image.cuda()
sr_image = model(lr_image).clamp(0.0, 1.0)
mse = ((hr_image - sr_image) ** 2).data.mean()
psnr = 10 * log10(1 / mse)
ssim = pytorch_ssim.ssim(sr_image, hr_image).data.item()
lpipsm = loss_fn.forward(sr_image, hr_image)
test_images = torch.stack([
display_transform()(hr_restore_img.squeeze(0)),
display_transform()(hr_image.data.cpu().squeeze(0)),
display_transform()(sr_image.data.cpu().squeeze(0))
])
# torch.stack沿着一个新维度对输入张量序列进行连接;增加新的维度进行堆叠。比如把多个2维的张量凑成一个3维的张量;多个3维的凑成一个4维的张量…
# outputs = torch.stack(inputs, dim=0) → Tensor
image = utils.make_grid(test_images, nrow=3, padding=5)
utils.save_image(image, out_path + image_name.split('.')[0] + '_psnr_%.4f_ssim_%.4f_lpips_%.4f.' % (psnr, ssim, lpipsm) +
image_name.split('.')[-1], padding=5)
# save psnr\ssim
results[image_name.split('_')[0]]['psnr'].append(psnr)
results[image_name.split('_')[0]]['ssim'].append(ssim)
results[image_name.split('_')[0]]['lpipsm'].append(lpipsm)
out_path = 'statistics/' # 训练的过程保存路径
saved_results = {'psnr': [], 'ssim': [], 'lpipsm': []}
for item in results.values():
psnr = np.array(item['psnr'])
ssim = np.array(item['ssim'])
lpipsm = np.array(item['lpipsm']).astype(np.float64)
if (len(psnr) == 0) or (len(ssim) == 0) or (len(lpipsm) == 0):
psnr = 'No data'
ssim = 'No data'
lpipsm = 'No data'
else:
psnr = psnr.mean()
ssim = ssim.mean()
lpipsm = lpipsm.mean()
saved_results['psnr'].append(psnr)
saved_results['ssim'].append(ssim)
saved_results['lpipsm'].append(lpipsm)
data_frame = pd.DataFrame(saved_results, results.keys())
data_frame.to_csv(out_path + 'srf_' + str(UPSCALE_FACTOR) + '_test_results.csv', index_label='DataSet')
2.添加部分详细的介绍
2.1引入lpips库
首先需要到官网上下载好lpips的代码(链接在上面),下载好后把lpips的包放进SRGAN里面,如下图:
代码如下(示例):
from lpips.lpips import lpips
2.2 加入loss_fn
选着lpips的网络,注意loss_fn = lpips.LPIPS(net=‘alex’)中的net也可以选择其他的网络,例如VGG;在选择完loss_fn后,将模型放在GPU上(loss_fn.to(device))
loss_fn = lpips.LPIPS(net='alex')
loss_fn = loss_fn.to(device)
2.3 保存数据
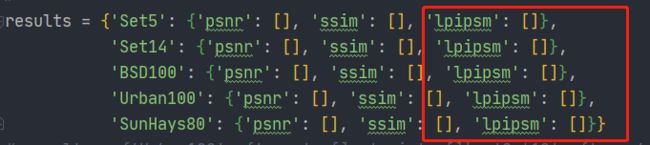
在存储最后的平均结果results上添加上’lpipsm’: []
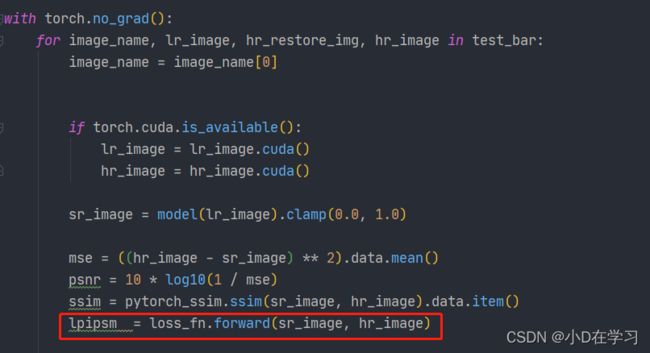
然后将生成的图像和目标图像输入到loss_fn中。计算lpips的值lpipsm
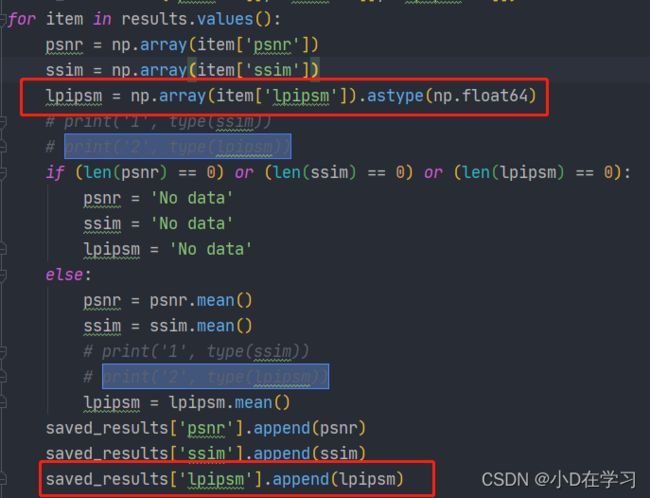
保存结果

需要注意的时,psnr = np.array(item[‘psnr’])输出来类型是的np.float64,而lpipsm = np.array(item[‘lpipsm’])输出的类型则是np.array(至于为什么,还没有去深究),需要把lpipsm的类型转换为float64,即lpipsm = np.array(item[‘lpipsm’]).astype(np.float64),不然会报错。
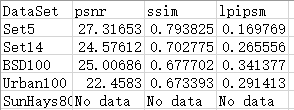
最后的结果(SunHays80的数据集我没有下载,所以。。)
实验采用的数据集为DIV2K,在一张2080Ti卡上训练大概4-5小时。
平均
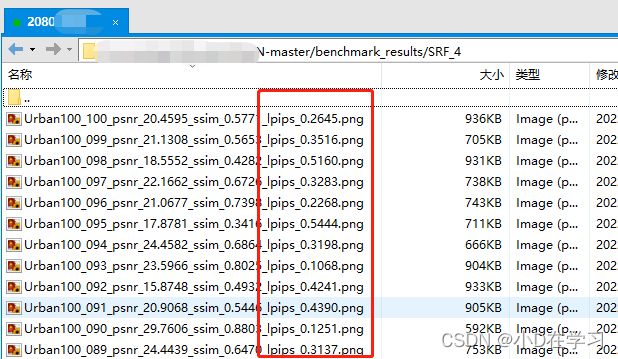
每张
总结
该博客主要介绍如何用一个指标LPIPS对SRGAN进行评估,写得略微简陋,后续还会更新LPIPS在CNN上的评估,以及SRGAN的训练过程、ESRGAN等等。
写得不容易呀,路过觉得不错的可以点赞收藏支持一下哈(这样采用动力更新hhh)