3 图游走算法
文章目录
- 1一个简单的图
-
- 1.1 首先创建安装环境
- 1.2 创建一张图
- 1.3 定义图模型
- 1.4 训练前的准备
- 1.5 开始训练
- 1.6 模型测试
- 2 随机游走算法
-
- 2.1 为什么要游走?
- 2.2 一个通俗的例子
- 2.3 Word2Vec
-
- 2.3.1 Skip Gram
- 2.3.2 Negative Sampling
- 2.4 node embedding方法
-
- 2.4.1 DeepWalk
- 2.4.2 node2vec
- 2.4.3 methpath2vec
- 2.4.4 变种结构
- 2.5 小结
- 2.6 DeepWalk代码
-
- 2.6.1 随机游走部分
- 2.6.2 Skip gram & negative sample
-
- 2.6.2.1 data
- 2.6.2.2 model
- 2.7 Node2Vec代码
- 3 参考
感谢百度,感恩度娘,百度飞桨-图神经网络
1一个简单的图
1.1 首先创建安装环境
# 安装 PaddlePaddle 框架
pip install paddlepaddle==1.8.5
# 安装 PGL 学习库
!pip install pgl
1.2 创建一张图
import pgl
from pgl import graph # 导入 PGL 中的图模块
import paddle.fluid as fluid # 导入飞桨框架
import numpy as np
def build_graph():
# 定义图中的节点数目,我们使用数字来表示图中的每个节点
num_nodes = 10
# 定义图中的边集
edge_list = [(2, 0), (2, 1), (3, 1),(4, 0), (5, 0),
(6, 0), (6, 4), (6, 5), (7, 0), (7, 1),
(7, 2), (7, 3), (8, 0), (9, 7)]
# 随机初始化节点特征,特征维度为 d
d = 16
feature = np.random.randn(num_nodes, d).astype("float32")
print("feature value")
print(feature)
print(feature.shape)
# 随机地为每条边赋值一个权重,这里是一个1-dim的向量
edge_feature = np.random.randn(len(edge_list), 1).astype("float32")
print("edge_feature value")
print(edge_feature)
print(edge_feature.shape)
# 创建图对象,最多四个输入
g = graph.Graph(num_nodes = num_nodes,
edges = edge_list,
node_feat = {'feature':feature},
edge_feat ={'edge_feature': edge_feature})
return g
g = build_graph()

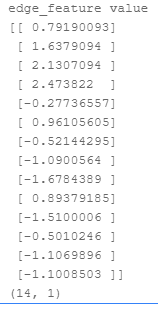
print('图中共计 %d 个节点' % g.num_nodes)
print('图中共计 %d 条边' % g.num_edges)
print('图中节点的向量表示,name:{0}, shape:{1}, dtype:{2}'.format(g.node_feat_info()[0][0], g.node_feat_info()[0][1], g.node_feat_info()[0][2]))
print('图中边的向量表示,name:{0}, shape:{1}, dtype:{2}'.format(g.edge_feat_info()[0][0], g.edge_feat_info()[0][1], g.edge_feat_info()[0][2]))

其他的信息参考:paddle中graph存储的信息API
1.3 定义图模型
# 定义一个同时传递节点特征和边权重的简单模型层。
def model_layer(gw, nfeat, efeat, hidden_size, name, activation):
'''
gw: GraphWrapper 图数据容器,用于在定义模型的时候使用,后续训练时再feed入真实数据
nfeat: 节点特征
efeat: 边权重
hidden_size: 模型隐藏层维度
activation: 使用的激活函数
'''
# 定义 send 函数
def send_func(src_feat, dst_feat, edge_feat):
# 将源节点的节点特征和边权重共同作为消息发送
return src_feat['h'] * edge_feat['e']
# 定义 recv 函数
def recv_func(feat):
# 目标节点接收源节点消息,采用 sum 的聚合方式
return fluid.layers.sequence_pool(feat, pool_type='sum')
# 触发消息传递机制
msg = gw.send(send_func, nfeat_list=[('h', nfeat)], efeat_list=[('e', efeat)])
output = gw.recv(msg, recv_func)
output = fluid.layers.fc(output,
size=hidden_size,
bias_attr=False,
act=activation,
name=name)
return output
class Model(object):
def __init__(self, graph):
"""
graph: 我们前面创建好的图
"""
# 创建 GraphWrapper 图数据容器,用于在定义模型的时候使用,后续训练时再feed入真实数据
self.gw = pgl.graph_wrapper.GraphWrapper(name='graph',
node_feat=graph.node_feat_info(),
edge_feat=graph.edge_feat_info())
# 作用同 GraphWrapper,此处用作节点标签的容器
self.node_label = fluid.layers.data("node_label", shape=[None, 1],
dtype="float32", append_batch_size=False)
def build_model(self):
# 定义两层model_layer
output = model_layer(self.gw,
self.gw.node_feat['feature'],
self.gw.edge_feat['edge_feature'],
hidden_size=8,
name='layer_1',
activation='relu')
output = model_layer(self.gw,
output,
self.gw.edge_feat['edge_feature'],
hidden_size=1,
name='layer_2',
activation=None)
# 对于二分类任务,可以使用以下 API 计算损失
loss = fluid.layers.sigmoid_cross_entropy_with_logits(x=output,
label=self.node_label)
# 计算平均损失
loss = fluid.layers.mean(loss)
# 计算准确率
prob = fluid.layers.sigmoid(output)
pred = prob > 0.5
pred = fluid.layers.cast(prob > 0.5, dtype="float32")
correct = fluid.layers.equal(pred, self.node_label)
correct = fluid.layers.cast(correct, dtype="float32")
acc = fluid.layers.reduce_mean(correct)
return loss, acc
1.4 训练前的准备
# 是否在 GPU 或 CPU 环境运行
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
# 定义程序,也就是我们的 Program
startup_program = fluid.Program() # 用于初始化模型参数
train_program = fluid.Program() # 训练时使用的主程序,包含前向计算和反向梯度计算
test_program = fluid.Program() # 测试时使用的程序,只包含前向计算
with fluid.program_guard(train_program, startup_program):
model = Model(g)
# 创建模型和计算 Loss
loss, acc = model.build_model()
# 选择Adam优化器,学习率设置为0.01
adam = fluid.optimizer.Adam(learning_rate=0.01)
adam.minimize(loss) # 计算梯度和执行梯度反向传播过程
# 复制构造 test_program,与 train_program的区别在于不需要梯度计算和反向过程。
test_program = train_program.clone(for_test=True)
# 定义一个在 place(CPU)上的Executor来执行program
exe = fluid.Executor(place)
# 参数初始化
exe.run(startup_program)
# 获取真实图数据
feed_dict = model.gw.to_feed(g)
# 获取真实标签数据
# 由于我们是做节点分类任务,因此可以简单的用0、1表示节点类别。其中,黄色点标签为0,绿色点标签为1。
y = [0,1,1,1,0,0,0,1,0,1]
label = np.array(y, dtype="float32")
label = np.expand_dims(label, -1)
feed_dict['node_label'] = label
1.5 开始训练
for epoch in range(30):
train_loss = exe.run(train_program,
feed=feed_dict, # feed入真实训练数据
fetch_list=[loss], # fetch出需要的计算结果
return_numpy=True)[0]
print('Epoch %d | Loss: %f' % (epoch, train_loss))
1.6 模型测试
test_acc = exe.run(test_program, feed=feed_dict, fetch_list=[acc], return_numpy=True)[0]
print("Test Acc: %f" % test_acc)
2 随机游走算法
2.1 为什么要游走?
我们知道,图模型只是一种数据结构,其本质上与图像,序列一样,只是表达数据的一种方式,我们构建图这种数据结构,其最终目的还是要为我们的目标服务,例如分类等。所以,图游走类算法,可以理解成为是提取图结构特征的一种方法,相当于图像数据中的CNN算法一样,给图中的node表示一下,得到的结果称为 node embedding,在此基础上,使用node embedding进行我们的下游任务。
2.2 一个通俗的例子
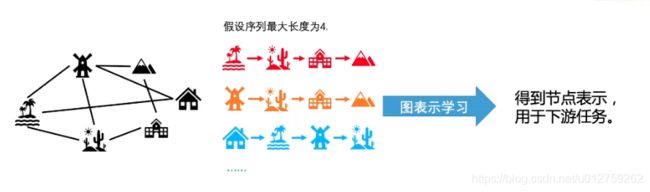
假设有这样一张图,想要经过其中的各个4地点(序列最大长度为4)。

则可以表示为
2.3 Word2Vec
2.3.1 Skip Gram
中心思想:词的语义可以通过上下文进行表示。
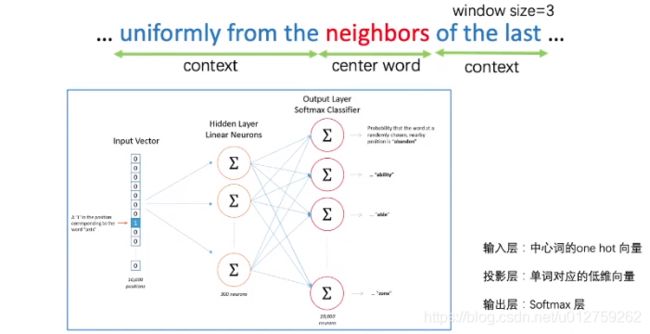
首先把词进行独热编码,通过设置窗口大小,找到其附近相关的几个词,上文中是前后3个词,构建一个神经网络,Input是“neighbors”的one-hot编码向量,输出是“neighbors”附近的6个词,进行训练。我们的目标是要神经网络的权重参数,并不要求预测相关词的精确度。
skip gram的具体意义可以参考这篇博客
2.3.2 Negative Sampling
在原本的思想中,如果要预测某个中心词附近的上下文,则需要对字典中的所有单词都预测一个概率,这样的话计算量会非常的大。

所以,有作者提出了负采样的概念,将softmax变成多个 sigmoid层。
比如说 love 和me两个单词;
使用特殊思维模式;假设整个词汇表只有100个单词;love 表示成one-hot向量; me表示成one-hot向量;模型输入为love的one-hot向量;模型输出为me的one-hot向量;
假设模型的神经网络结构为100*10*100;输出层100个;
输出层中除了me对应位置的1外,其他全是0;称这为负样本;参数数量为10*100
采样就是从这样负样本中抽样;比如说抽取5个;那么在此次梯度更新中就只更新10*5;更新数量为原来的1/20

2.4 node embedding方法
2.4.1 DeepWalk
游走方式:随机游走,从某一个点出发,通过连接边到下一个节点,直到最大的游走长度。
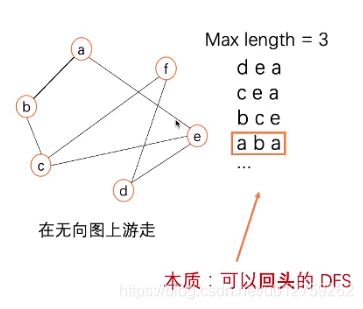
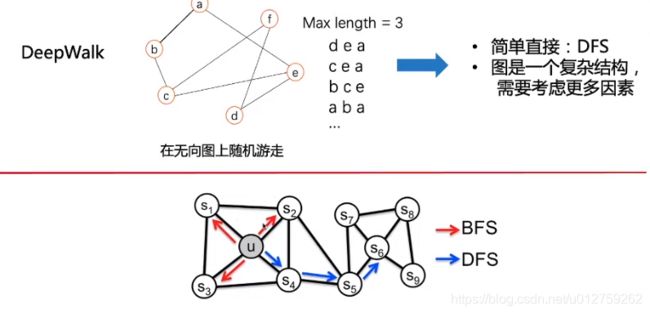
表示成公式为:

其选择概率其实是:归一化后的转移概率分布;当采用等概率的算法对下一个节点进行选择时,则可以表示为红色的表达式,其中 N ( v ) N(v) N(v)代表节点的数量。
下面是random walk的核心代码:
class UserDefGraph(Graph):
'''
Graph需要四个参数:
num_nodes:节点的数量
edges:边的信息:
# 定义图中的边集
edge_list = [(2, 0), (2, 1), (3, 1),(4, 0), (5, 0),
(6, 0), (6, 4), (6, 5), (7, 0), (7, 1),
(7, 2), (7, 3), (8, 0), (9, 7)]
node_feat:节点的向量表示
edge_feat:边的向量表示
'''
def random_walk(self, nodes, walk_len):
"""
输入:nodes - 当前节点id list (batch_size,)
eg. batch_size 为2时:[ 9443 13694]
walk_len - 最大路径长度 int
输出:以当前节点为起点得到的路径 list (batch_size, walk_len)
用到的函数
1. self.successor(nodes)
描述:获取当前节点的下一个相邻节点id列表
输入:nodes - list (batch_size,)
输出:succ_nodes - list of list ((num_successors_i,) for i in range(batch_size))
2. self.outdegree(nodes)
描述:获取当前节点的出度
输入:nodes - list (batch_size,)
输出:out_degrees - list (batch_size,)
"""
walks = [[node] for node in nodes]
walks_ids = np.arange(0, len(nodes))
cur_nodes = np.array(nodes)
for l in range(walk_len):
"""选取有下一个节点的路径继续采样,否则结束"""
# 这里的cur_nodes是一个长度为batch_size 的node序列:batch_size为2时的样子[ 9443 13694]
outdegree = self.outdegree(cur_nodes)
# outdegree代表每一个node的出度的数量:对应上述node的出度数量:[13 0]
walk_mask = (outdegree != 0)
# walk_mask 代表掩码 [ True False]
if not np.any(walk_mask):
break
cur_nodes = cur_nodes[walk_mask]
# cur_nodes:[9443]
walks_ids = walks_ids[walk_mask]
# walks_ids:[0]
outdegree = outdegree[walk_mask]
# outdegree:[13]
######################################
# 请在此补充代码采样出下一个节点
succ_nodes = self.successor(cur_nodes)
# succ_nodes:[[ 867 11035 8349 5118 6659 930 3524 1731 948 4942 987 4464 147]]
sample_index = np.floor(
np.random.rand(outdegree.shape[0]) * outdegree).astype("int64")
# sample_index:[8]
next_nodes = []
for s, ind, walk_id in zip(succ_nodes, sample_index, walks_ids):
walks[walk_id].append(s[ind])
next_nodes.append(s[ind])
######################################
cur_nodes = np.array(next_nodes)
return walks
2.4.2 node2vec
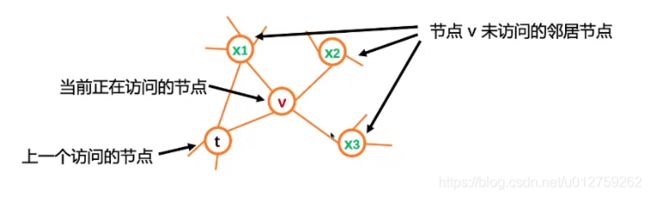
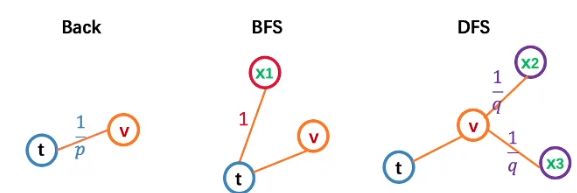
假设有各个节点的状态如图所示,其中,选择节点的概率可以表示为:
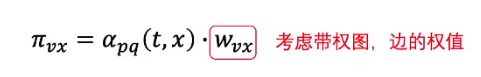
其中: w v x w_{vx} wvx为边的权重, α p q \alpha_{pq} αpq代表节点 p , q p,q p,q之间的选择权重, p , q p,q p,q是超参数。

在节点状态图中,节点 d t t = 0 d_{tt}=0 dtt=0,节点 d t x 2 = d t x 3 = 2 d_{tx_2}=d_{tx_3}=2 dtx2=dtx3=2,节点 d t x 1 = 1 d_{tx_1}=1 dtx1=1
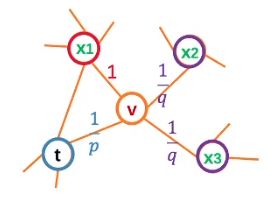
1 p \frac{1}{p} p1代表节点 v v v是否要回到节点 t t t的概率

#----------------
# Node2Vec采样算法
#----------------
def node2vec_sample(succ, prev_succ, prev_node, p, q):
"""
输入:succ - 当前节点的下一个相邻节点id列表 list (num_neighbors,)
prev_succ - 前一个节点的下一个相邻节点id列表 list (num_neighbors,)
prev_node - 前一个节点id int
p - 控制回到上一节点的概率 float
q - 控制偏向DFS还是BFS float
输出:下一个节点id int
"""
##################################
# 请在此实现node2vec的节点采样函数
# 当前节点下一个相邻节点的长度
succ_len = len(succ)
# 前一个节点下一个相邻节点的长度
prev_succ_len = len(prev_succ)
prob_sum = 0.0
prev_succ_set = []
# 前一个节点的邻居节点
for i in range(prev_succ_len):
prev_succ_set.append(prev_succ[i])
probs = []
for i in range(succ_len):
if succ[i] == prev_node:
prob = 1. / p
elif succ[i] in prev_succ_set and succ[i] != prev_succ_set[-1]:
prob = 1.
else:
prob = 1. / q
probs.append(prob)
prob_sum += prob
rand_num = random() * prob_sum
for i in range(succ_len):
rand_num -= probs[i]
if rand_num <= 0:
sample_succ = succ[i]
return sample_succ
##################################
class UserDefGraph(Graph):
def node2vec_random_walk(self, nodes, max_depth, p=1.0, q=1.0):
"""Implement of node2vec stype random walk.
Reference paper: https://cs.stanford.edu/~jure/pubs/node2vec-kdd16.pdf.
Args:
nodes: Walk starting from nodes
max_depth: Max walking depth
p: Return parameter
q: In-out parameter
Return:
A list of walks.
"""
if p == 1. and q == 1.:
return self.random_walk(nodes, max_depth)
walk = []
# init
for node in nodes:
walk.append([node])
cur_walk_ids = np.arange(0, len(nodes))
cur_nodes = np.array(nodes)
prev_nodes = np.array([-1] * len(nodes), dtype="int64")
prev_succs = np.array([[]] * len(nodes), dtype="int64")
for d in range(max_depth):
# select the walks not end
outdegree = self.outdegree(cur_nodes)
mask = (outdegree != 0)
if np.any(mask):
cur_walk_ids = cur_walk_ids[mask]
cur_nodes = cur_nodes[mask]
prev_nodes = prev_nodes[mask]
prev_succs = prev_succs[mask]
else:
# stop when all nodes have no successor
break
cur_succs = self.successor(cur_nodes)
num_nodes = cur_nodes.shape[0]
nxt_nodes = np.zeros(num_nodes, dtype="int64")
for idx, (succ, prev_succ, walk_id, prev_node) in enumerate(
zip(cur_succs, prev_succs, cur_walk_ids, prev_nodes)):
### Use your own node2vec_sample -- node2vec 采样作业
sampled_succ = node2vec_sample(succ, prev_succ, prev_node, p, q)
walk[walk_id].append(sampled_succ)
nxt_nodes[idx] = sampled_succ
prev_nodes, prev_succs = cur_nodes, cur_succs
cur_nodes = nxt_nodes
return walk
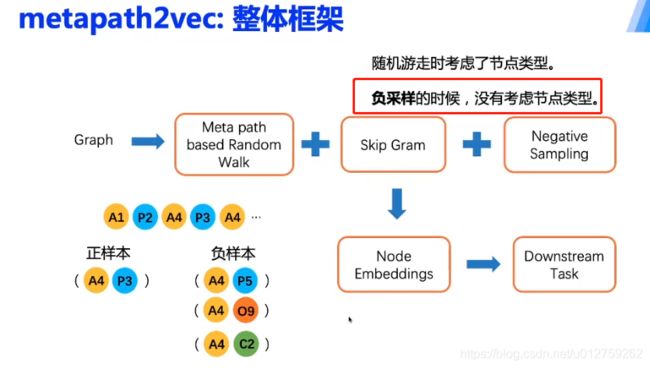
2.4.3 methpath2vec

在边、点的基础上,加上了节点的type
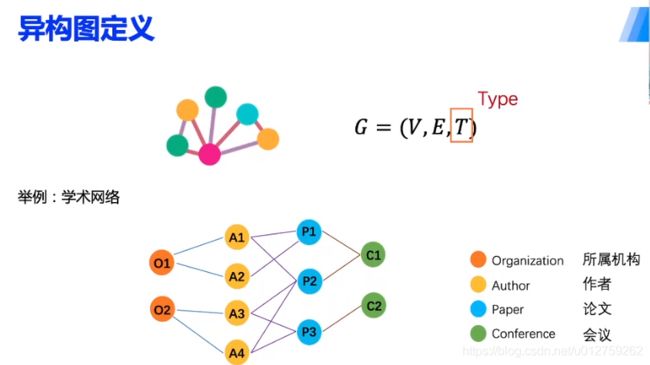
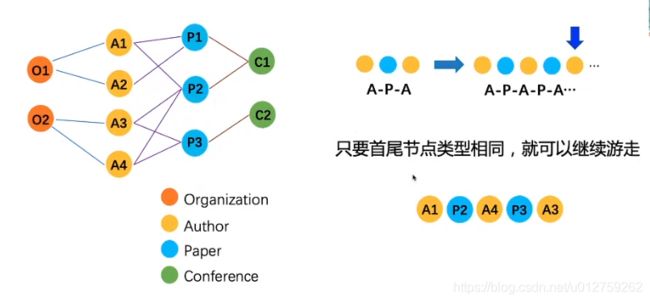
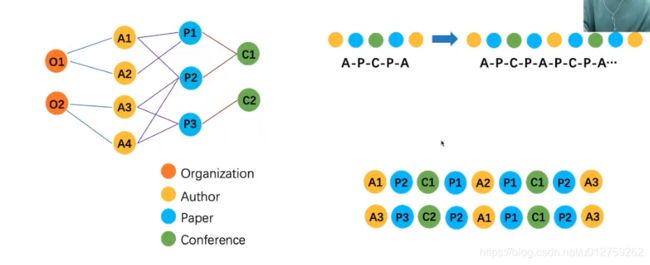
在上述的学术网络中,游走的方式:根据节点类型构成组合的路径,例如
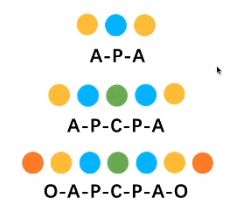
这种游走方式必须要是对称的,A-P-A代表:两个作者在发表了同一篇文章。
例子1:
例子2:

2.4.4 变种结构
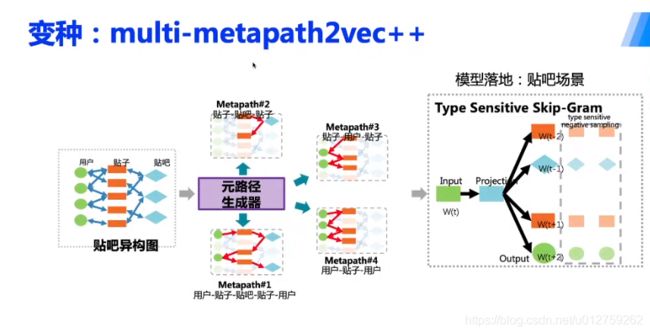
在metapath2vec的基础上,针对多条路径再继续游走
2.5 小结
2.6 DeepWalk代码
整体思路参考2.5小结中流程
2.6.1 随机游走部分
大致流程为:
- 先读取数据,存到graph图中(一直到
pool.map(process, args_list)) - 创建随机游走结果的保存文件(主要是函数
graph.random_walk(nodes, walk_len))
hidden_size = args.hidden_size
neg_num = args.neg_num
epoch = args.epoch
save_path = args.save_path
batch_size = args.batch_size
walk_len = args.walk_len
win_size = args.win_size
# 设置模型保存路径
if not os.path.isdir(save_path):
os.makedirs(save_path)
# 导入数据集
dataset = data_loader.ArXivDataset()
# Use your random_walk -- DeepWalk作业部分
pgl_graph = dataset.graph
# 开始随机游走
dataset.graph = UserDefGraph(num_nodes=pgl_graph.num_nodes,
edges=pgl_graph.edges,
node_feat=pgl_graph.node_feat,
edge_feat=pgl_graph.edge_feat)
print(pgl_graph.num_nodes)
print(pgl_graph.edges)
print(pgl_graph.node_feat)
print(pgl_graph.edge_feat)
log.info("Start random walk on disk...")
walk_save_path = os.path.join(save_path, "walks")
if not os.path.isdir(walk_save_path):
os.makedirs(walk_save_path)
# 多进程随机游走过程
pool = Pool(args.processes)
# idx, graph, save_path, epoch, batch_size, walk_len, seed = args
# 在process函数中,相互对应的情况
args_list = [(x, dataset.graph, walk_save_path, 1, batch_size,
walk_len, np.random.randint(2**32, dtype="int64"))
for x in range(epoch)]
# 在process中,把随机游走的结果存储到文件中
pool.map(process, args_list)
# glob 返回所有匹配的文件路径列表,看看是不是有随机游走的文件,有的话,随机游走结束
filelist = glob.glob(os.path.join(walk_save_path, "*"))
log.info("Random walk on disk Done.")
其中倒数第四行中多进程 process函数目的是把每一个epoch,都进行随机游走,得到的结果存储在文件中。
def process(args):
idx, graph, save_path, epoch, batch_size, walk_len, seed = args
with open('%s/%s' % (save_path, idx), 'w') as outf:
for _ in range(epoch):
np.random.seed(seed)
for nodes in graph.node_batch_iter(batch_size):
walks = graph.random_walk(nodes, walk_len)
for walk in walks:
outf.write(' '.join([str(token) for token in walk]) + '\n')
2.6.2 Skip gram & negative sample
整个流程如下:
- 先定义模型和损失函数
- feed data
2.6.2.1 data
其实在代码中,data的顺序是在model后的,但是为了便于理解,先介绍data
# 将deepwalk_generator生成的数据源feed到deepwalk_pyreader
deepwalk_pyreader.decorate_tensor_provider(
deepwalk_generator(
dataset.graph,
batch_size=batch_size,
walk_len=walk_len,
win_size=win_size,
epoch=epoch,
neg_num=neg_num,
filelist=filelist))
def deepwalk_generator(graph,
batch_size=512,
walk_len=5,
win_size=2,
neg_num=5,
epoch=200,
filelist=None):
"""
此函数用于生成训练所需要的(中心节点、正样本、负样本)
"""
def walks_generator():
# 读取 random walk 序列
if filelist is not None:
bucket = []
for filename in filelist:
with io.open(filename) as inf:
for line in inf:
walk = [int(x) for x in line.strip('\n').split(' ')]
bucket.append(walk)
if len(bucket) == batch_size:
yield bucket
bucket = []
if len(bucket):
yield bucket
else:
# 如果没有找到存储random walk的文件,则在此处设置开始游走
for _ in range(epoch):
for nodes in graph.node_batch_iter(batch_size):
walks = graph.random_walk(nodes, walk_len)
yield walks
def wrapper():
# 生成训练用样本
for walks in walks_generator():
src, pos = gen_pair(walks, win_size, win_size)
if src.shape[0] == 0:
continue
# 在图中随机采样节点,作为当前 src 节点的负节点
negs = graph.sample_nodes([len(src), neg_num, 1]).astype(np.int64)
yield [src, pos, negs]
return wrapper
其中,deepwalk_generator的代码如下:正常的理解顺序应该是:
- 读取之前随机游走部分生成的游走序列,也就是
filelist中的值,在代码中是作为参数进去的。 - 在函数
wapper调用walks_generator,按照batch_size对数据进行组合,生成bucket - 在函数
wapper中遍历每一个node,通过函数gen_pair生成skip gram的数据 - 对src数据进行随机采样
-
第一步就不说了,读取文件名列表
-
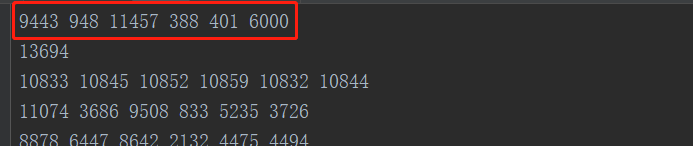
生成bucket:遍历文件中的内容,取batch_size个游走序列,这里以batch_size=1为例
-
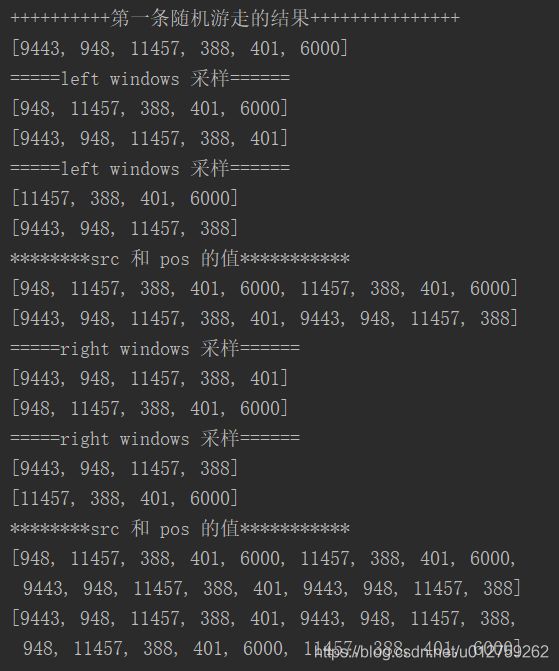
通过gen_pair函数生成src和pos序列,为了方便理解gen_pair函数:以第一条随机游走序列为例,打印出了src和pos的值(后续还还需要有一个扩展维度的操作,这里没有执行)。从中可以看到,src中存储的可以看做是中心节点,pos中存储的是其windows_size 中的临近节点
-
- src和pos生成的大小取决于win_size 和 walk_len的大小,如果win_size=2,walk_len=5,则生成的src和pos均为2*6=12。
例如ABCDE五个节点:- A:AB,AC
- B:BA,BC,BD
- C:CB,CA,CD,CE
- D:DE,DC,DB,
- src和pos生成的大小取决于win_size 和 walk_len的大小,如果win_size=2,walk_len=5,则生成的src和pos均为2*6=12。
- 第4步,在图中随机采样节点,作为当前 src 节点的负节点,源码中调用的是:
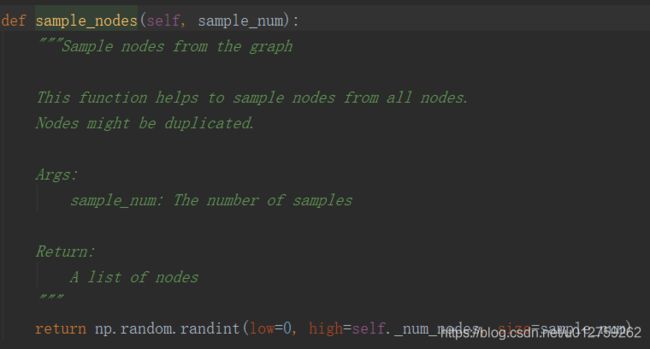
randint的接收值可以是一个list

2.6.2.2 model
# 接下来应该进行skip gram和负采样了
with fluid.program_guard(deepwalk_prog, startup_prog):
with fluid.unique_name.guard():
deepwalk_pyreader, deepwalk_loss = deepwalk_model(
dataset.graph, hidden_size=hidden_size, neg_num=neg_num)
lr = l.polynomial_decay(0.025, train_steps, 0.0001) # 对初始学习率使用多项式衰减
adam = fluid.optimizer.Adam(lr)
adam.minimize(deepwalk_loss)
其中,deepwalk_model为
def deepwalk_model(graph, hidden_size=16, neg_num=5):
"""
该函数为Skip Gram模型部分,即课堂所讲的 Skip Gram + 负采样
函数参数含义:
graph: 图
hidden_size: 节点维度
neg_num: 负采样数目
"""
# 创建在Python端提供数据的reader
# capacity: 维护的缓冲区的容量数据个数
# shapes:是一个列表或元组,shapes[i]是代表第i个数据shape,
# shape[i]也是元组或列表。这里维度分别为:[-1, 1, 1], [-1, 1, 1], [-1, neg_num, 1]
# 三个list分别代表
# src:[batch_size * (win_size+1)* walk_len, 1, 1],
# [这一批batch_size中随机游走node的总数量, 当前节点的数量, 1]
# pos:[batch_size * (win_size+1)* walk_len, 1, 1],
# negs:[batch_size * (win_size+1)* walk_len, neg_num,1],
# 这里的embedding其实是对游走的序列进行embedding
#
pyreader = l.py_reader(
capacity=70,
shapes=[[-1, 1, 1], [-1, 1, 1], [-1, neg_num, 1]],
dtypes=['int64', 'int64', 'int64'],
lod_levels=[0, 0, 0],
name='train',
use_double_buffer=True)
# 创建参数的初始化器
embed_init = fluid.initializer.UniformInitializer(low=-1.0, high=1.0)
weight_init = fluid.initializer.TruncatedNormal(scale=1.0 /
math.sqrt(hidden_size))
# 从给定的reader中读取数据,包括中心节点编号,对应的正样本节点编号和负样本节点编号
src, pos, negs = l.read_file(pyreader)
# 从Embedding矩阵中,根据input参数的节点id信息,查询对应节点的embedding表示
# 输入:embed_src - 中心节点向量 list (batch_size, 1, embed_size)
# weight_pos - 标签节点向量 list (batch_size, 1, embed_size)
# weight_negs - 负样本节点向量 list (batch_size, neg_num, embed_size)
# 输出:loss - 正负样本的交叉熵 float
embed_src = l.embedding(
input=src,
size=[graph.num_nodes, hidden_size],
param_attr=fluid.ParamAttr(
name='content', initializer=embed_init))
weight_pos = l.embedding(
input=pos,
size=[graph.num_nodes, hidden_size],
param_attr=fluid.ParamAttr(
name='weight', initializer=weight_init))
weight_negs = l.embedding(
input=negs,
size=[graph.num_nodes, hidden_size],
param_attr=fluid.ParamAttr(
name='weight', initializer=weight_init))
### 负采样计算部分——Multi Sigmoids
# 分别计算正样本和负样本的 logits
pos_logits = l.matmul(
embed_src, weight_pos, transpose_y=True) # [batch_size, 1, 1]
neg_logits = l.matmul(
embed_src, weight_negs, transpose_y=True) # [batch_size, 1, neg_num]
# 设置正样本标签,并计算正样本loss
ones_label = pos_logits * 0. + 1.
ones_label.stop_gradient = True
pos_loss = l.sigmoid_cross_entropy_with_logits(pos_logits, ones_label)
# 设置负样本标签,并计算负样本loss
zeros_label = neg_logits * 0.
zeros_label.stop_gradient = True
neg_loss = l.sigmoid_cross_entropy_with_logits(neg_logits, zeros_label)
# 总的Loss计算为正样本与负样本loss之和
loss = (l.reduce_mean(pos_loss) + l.reduce_mean(neg_loss)) / 2
return pyreader, loss
整个代码如下:
"""DeepWalk代码文件"""
# 导入需要的依赖包
import argparse
import time
import os
import io
import math
from multiprocessing import Pool
import glob
import numpy as np
from pgl import data_loader
from pgl.utils.logger import log
import paddle.fluid as fluid
import paddle.fluid.layers as l
from pgl.graph import Graph
class UserDefGraph(Graph):
'''
Graph需要四个参数:
num_nodes:节点的数量
edges:边的信息:
# 定义图中的边集
edge_list = [(2, 0), (2, 1), (3, 1),(4, 0), (5, 0),
(6, 0), (6, 4), (6, 5), (7, 0), (7, 1),
(7, 2), (7, 3), (8, 0), (9, 7)]
node_feat:节点的向量表示
edge_feat:边的向量表示
'''
def random_walk(self, nodes, walk_len):
"""
输入:nodes - 当前节点id list (batch_size,)
walk_len - 最大路径长度 int
输出:以当前节点为起点得到的路径 list (batch_size, walk_len)
用到的函数
1. self.successor(nodes)
描述:获取当前节点的下一个相邻节点id列表
输入:nodes - list (batch_size,)
输出:succ_nodes - list of list ((num_successors_i,) for i in range(batch_size))
2. self.outdegree(nodes)
描述:获取当前节点的出度
输入:nodes - list (batch_size,)
输出:out_degrees - list (batch_size,)
"""
print("nodes")
print(nodes)
walks = [[node] for node in nodes]
walks_ids = np.arange(0, len(nodes))
cur_nodes = np.array(nodes)
for l in range(walk_len):
"""选取有下一个节点的路径继续采样,否则结束"""
outdegree = self.outdegree(cur_nodes)
walk_mask = (outdegree != 0)
if not np.any(walk_mask):
break
cur_nodes = cur_nodes[walk_mask]
walks_ids = walks_ids[walk_mask]
outdegree = outdegree[walk_mask]
######################################
# 请在此补充代码采样出下一个节点
succ_nodes = self.successor(cur_nodes)
sample_index = np.floor(
np.random.rand(outdegree.shape[0]) * outdegree).astype("int64")
next_nodes = []
for s, ind, walk_id in zip(succ_nodes, sample_index, walks_ids):
walks[walk_id].append(s[ind])
next_nodes.append(s[ind])
######################################
cur_nodes = np.array(next_nodes)
return walks
def deepwalk_model(graph, hidden_size=16, neg_num=5):
"""
该函数为Skip Gram模型部分,即课堂所讲的 Skip Gram + 负采样
函数参数含义:
graph: 图
hidden_size: 节点维度
neg_num: 负采样数目
"""
# 创建在Python端提供数据的reader
# capacity: 维护的缓冲区的容量数据个数
# shapes:是一个列表或元组,shapes[i]是代表第i个数据shape,
# shape[i]也是元组或列表。这里维度分别为:[-1, 1, 1], [-1, 1, 1], [-1, neg_num, 1]
# 这里的embedding其实是对游走的序列进行embedding
# 所以输入为该node的one-hot编码,输出应该为
pyreader = l.py_reader(
capacity=70,
shapes=[[-1, 1, 1], [-1, 1, 1], [-1, neg_num, 1]],
dtypes=['int64', 'int64', 'int64'],
lod_levels=[0, 0, 0],
name='train',
use_double_buffer=True)
# 创建参数的初始化器
embed_init = fluid.initializer.UniformInitializer(low=-1.0, high=1.0)
weight_init = fluid.initializer.TruncatedNormal(scale=1.0 /
math.sqrt(hidden_size))
# 从给定的reader中读取数据,包括中心节点编号,对应的正样本节点编号和负样本节点编号
src, pos, negs = l.read_file(pyreader)
# 从Embedding矩阵中,根据input参数的节点id信息,查询对应节点的embedding表示
embed_src = l.embedding(
input=src,
size=[graph.num_nodes, hidden_size],
param_attr=fluid.ParamAttr(
name='content', initializer=embed_init))
weight_pos = l.embedding(
input=pos,
size=[graph.num_nodes, hidden_size],
param_attr=fluid.ParamAttr(
name='weight', initializer=weight_init))
weight_negs = l.embedding(
input=negs,
size=[graph.num_nodes, hidden_size],
param_attr=fluid.ParamAttr(
name='weight', initializer=weight_init))
### 负采样计算部分——Multi Sigmoids
# 分别计算正样本和负样本的 logits
pos_logits = l.matmul(
embed_src, weight_pos, transpose_y=True) # [batch_size, 1, 1]
neg_logits = l.matmul(
embed_src, weight_negs, transpose_y=True) # [batch_size, 1, neg_num]
# 设置正样本标签,并计算正样本loss
ones_label = pos_logits * 0. + 1.
ones_label.stop_gradient = True
pos_loss = l.sigmoid_cross_entropy_with_logits(pos_logits, ones_label)
# 设置负样本标签,并计算负样本loss
zeros_label = neg_logits * 0.
zeros_label.stop_gradient = True
neg_loss = l.sigmoid_cross_entropy_with_logits(neg_logits, zeros_label)
# 总的Loss计算为正样本与负样本loss之和
loss = (l.reduce_mean(pos_loss) + l.reduce_mean(neg_loss)) / 2
return pyreader, loss
def gen_pair(walks, left_win_size=2, right_win_size=2):
"""
该函数用于生成正样本对
函数参数含义:
walks: 多条节点游走序列
left_win_size: 左窗口值大小
right_win_size: 右窗口值大小
"""
src = []
pos = []
for walk in walks:
for left_offset in range(1, left_win_size + 1):
src.extend(walk[left_offset:])
pos.extend(walk[:-left_offset])
for right_offset in range(1, right_win_size + 1):
src.extend(walk[:-right_offset])
pos.extend(walk[right_offset:])
src, pos = np.array(src, dtype=np.int64), np.array(pos, dtype=np.int64)
src, pos = np.expand_dims(src, -1), np.expand_dims(pos, -1)
src, pos = np.expand_dims(src, -1), np.expand_dims(pos, -1)
return src, pos
def deepwalk_generator(graph,
batch_size=512,
walk_len=5,
win_size=2,
neg_num=5,
epoch=200,
filelist=None):
"""
此函数用于生成训练所需要的(中心节点、正样本、负样本)
"""
def walks_generator():
# 读取 random walk 序列
if filelist is not None:
bucket = []
for filename in filelist:
with io.open(filename) as inf:
for line in inf:
walk = [int(x) for x in line.strip('\n').split(' ')]
bucket.append(walk)
if len(bucket) == batch_size:
yield bucket
bucket = []
if len(bucket):
yield bucket
else:
# 如果没有找到存储random walk的文件,则在此处设置开始游走
for _ in range(epoch):
for nodes in graph.node_batch_iter(batch_size):
walks = graph.random_walk(nodes, walk_len)
yield walks
def wrapper():
# 生成训练用样本
for walks in walks_generator():
src, pos = gen_pair(walks, win_size, win_size)
if src.shape[0] == 0:
continue
# 在图中随机采样节点,作为当前 src 节点的负节点
negs = graph.sample_nodes([len(src), neg_num, 1]).astype(np.int64)
yield [src, pos, negs]
return wrapper
def process(args):
idx, graph, save_path, epoch, batch_size, walk_len, seed = args
with open('%s/%s' % (save_path, idx), 'w') as outf:
for _ in range(epoch):
np.random.seed(seed)
for nodes in graph.node_batch_iter(batch_size):
walks = graph.random_walk(nodes, walk_len)
for walk in walks:
outf.write(' '.join([str(token) for token in walk]) + '\n')
def main(args):
"""
主函数
"""
hidden_size = args.hidden_size
neg_num = args.neg_num
epoch = args.epoch
save_path = args.save_path
batch_size = args.batch_size
walk_len = args.walk_len
win_size = args.win_size
# 设置模型保存路径
if not os.path.isdir(save_path):
os.makedirs(save_path)
# 导入数据集
dataset = data_loader.ArXivDataset()
# Use your random_walk -- DeepWalk作业部分
pgl_graph = dataset.graph
# 开始随机游走
dataset.graph = UserDefGraph(num_nodes=pgl_graph.num_nodes,
edges=pgl_graph.edges,
node_feat=pgl_graph.node_feat,
edge_feat=pgl_graph.edge_feat)
print(pgl_graph.num_nodes)
print(pgl_graph.edges)
print(pgl_graph.node_feat)
print(pgl_graph.edge_feat)
log.info("Start random walk on disk...")
walk_save_path = os.path.join(save_path, "walks")
if not os.path.isdir(walk_save_path):
os.makedirs(walk_save_path)
# 多进程随机游走过程
pool = Pool(args.processes)
# idx, graph, save_path, epoch, batch_size, walk_len, seed = args
# 在process函数中,相互对应的情况
args_list = [(x, dataset.graph, walk_save_path, 1, batch_size,
walk_len, np.random.randint(2**32, dtype="int64"))
for x in range(epoch)]
# 在process中,把随机游走的结果存储到文件中
pool.map(process, args_list)
# glob 返回所有匹配的文件路径列表,看看是不是有随机游走的文件,有的话,随机游走结束
filelist = glob.glob(os.path.join(walk_save_path, "*"))
log.info("Random walk on disk Done.")
# 设置train_steps
train_steps = int(dataset.graph.num_nodes / batch_size) * epoch
place = fluid.CPUPlace()
deepwalk_prog = fluid.Program()
startup_prog = fluid.Program()
# 接下来应该进行skip gram和负采样了
with fluid.program_guard(deepwalk_prog, startup_prog):
with fluid.unique_name.guard():
deepwalk_pyreader, deepwalk_loss = deepwalk_model(
dataset.graph, hidden_size=hidden_size, neg_num=neg_num)
lr = l.polynomial_decay(0.025, train_steps, 0.0001) # 对初始学习率使用多项式衰减
adam = fluid.optimizer.Adam(lr)
adam.minimize(deepwalk_loss)
# 将deepwalk_generator生成的数据源feed到deepwalk_pyreader
deepwalk_pyreader.decorate_tensor_provider(
deepwalk_generator(
dataset.graph,
batch_size=batch_size,
walk_len=walk_len,
win_size=win_size,
epoch=epoch,
neg_num=neg_num,
filelist=filelist))
deepwalk_pyreader.start() # 开始数据传递
exe = fluid.Executor(place)
exe.run(startup_prog)
prev_time = time.time()
step = 0
# 开始训练
while 1:
try:
deepwalk_loss_val = exe.run(deepwalk_prog,
fetch_list=[deepwalk_loss],
return_numpy=True)[0]
cur_time = time.time()
use_time = cur_time - prev_time
prev_time = cur_time
step += 1
if step == 1 or step % 10 == 0:
log.info("Step %d " % step + "DeepWalk Loss: %f " %
deepwalk_loss_val + " %f s/step." % use_time)
except fluid.core.EOFException:
deepwalk_pyreader.reset()
break
# 保存训练好的DeepWalk模型
fluid.io.save_persistables(exe,
os.path.join(save_path, "paddle_model"),
deepwalk_prog)
if __name__ == '__main__':
# 超参数设置
parser = argparse.ArgumentParser(description='deepwalk')
parser.add_argument("--use_my_random_walk", action='store_true', help="use_my_random_walk")
parser.add_argument("--hidden_size", type=int, default=128)
parser.add_argument("--neg_num", type=int, default=20)
parser.add_argument("--epoch", type=int, default=1)
parser.add_argument("--batch_size", type=int, default=512)
parser.add_argument("--walk_len", type=int, default=5)
parser.add_argument("--win_size", type=int, default=5)
parser.add_argument("--save_path", type=str, default="./tmp/deepwalk")
parser.add_argument("--processes", type=int, default=1)
args = parser.parse_args()
log.info(args)
main(args)
2.7 Node2Vec代码
NOTE:Node2Vec会根据与上个节点的距离按不同概率采样得到当前节点的下一个节点。

参考; PGL/pgl/graph_kernel.pyx 中用Cython语言实现了节点采样函数node2vec_sample
import numpy as np
# 随机节点的获取
def node2vec_sample(succ, prev_succ, prev_node, p, q):
"""
输入:succ - 当前节点的下一个相邻节点id列表 list (num_neighbors,)
prev_succ - 前一个节点的下一个相邻节点id列表 list (num_neighbors,)
prev_node - 前一个节点id int
p - 控制回到上一节点的概率 float
q - 控制偏向DFS还是BFS float
输出:下一个节点id int
"""
##################################
# 请在此实现node2vec的节点采样函数
# 节点参数信息
succ_len = len(succ) # 获取相邻节点id列表节点长度(相对当前)
prev_succ_len = len(prev_succ) # 获取相邻节点id列表节点长度(相对前一个节点)
prev_succ_set = np.asarray([]) # 前一节点的相邻节点id列表
for i in range(prev_succ_len): # 遍历得到前一节点的相邻节点id列表的新list——prev_succ_set,用于后边概率的讨论
# 将前一节点list,依次押入新的list中
prev_succ_set = np.append(prev_succ_set,prev_succ[i]) # ? prev_succ_set.insert(prev_succ[i])
# 概率参数信息
probs = [] # 保存每一个待前往的概率
prob = 0 # 记录当前讨论的节点概率
prob_sum = 0. # 所有待前往的节点的概率之和
# 遍历当前节点的相邻节点
for i in range(succ_len): # 遍历每一个当前节点前往的概率
if succ[i] == prev_node: # case 1 : 采样节点与前一节点一致,那么概率为--1/q(原地)
prob = 1. / p
# case 2 完整的应该是: np.where(prev_succ_set==succ[i]) and np.where(succ==succ[i])
# 但是因为succ本身就是采样集,所以np.where(succ==succ[i])总成立,故而忽略,不考虑
elif np.where(prev_succ_set==succ[i]): # case 2 : 采样节点在前一节点list内,那么概率为--1 ?cpython中的代码: prev_succ_set.find(succ[i]) != prev_succ_set.end()
prob = 1.
elif np.where(prev_succ_set!=succ[i]): # case 3 : 采样节点不在前一节点list内,那么概率为--1/q
prob = 1. / q
else:
prob = 0. # case 4 : other
probs.append(prob) # 将待前往的每一个节点的概率押入保存
prob_sum += prob # 计算所有节点的概率之和
RAND_MAX = 65535 # 这是一个随机数的最值,用于计算随机值的--根据C/C++标准,最小在30000+,这里取2^16次方
rand_num = float(np.random.randint(0, RAND_MAX+1)) / RAND_MAX * prob_sum # 计算一个随机概率:0~prob_sum. ?cpython中的代码: float(rand())/RAND_MAX * prob_sum
sampled_succ = 0. # 当前节点的相邻节点中确定的采样点
# rand_num => 是0~prob_num的一个值,表示我们的截取概率阈值--即当遍历了n个节点时,若已遍历的节点的概率之和已经超过了rand_num
# 我们取刚好满足已遍历的节点的概率之和已经超过了rand_num的最近一个节点作为我们的采样节点
# 比如: 遍历到第5个节点时,权重概率和大于等于rand_num,此时第5个节点就是对应的采样的节点了
# 为了方便实现:这里利用循环递减--判断条件就变成了————当rand_num减到<=0时,开始采样节点
for i in range(succ_len): # 遍历当前节点的所有相邻节点
rand_num -= probs[i] # 利用rand_num这个随机获得的概率值作为依据,进行一个循环概率检验
if rand_num <= 0: # 当遇到第一次使得rand_num减到<=0后,说明到这个节点为止, 遍历应该终止了,此时的节点即未所求的节点,【停止检验条件】
sampled_succ = succ[i] # 并把当前节点作为确定的节点
return sampled_succ # 返回待采样的节点--节点一定在succ中
3 参考
1.【论文笔记】DeepWalk——陌上疏影凉
1.【网络图模型综述】
1.【异构图神经网络简介–机器之心】
1.【Graph Embedding之metapath2vec–圈圈_Master】
1.【从Random Walk谈到Bacterial foraging optimization algorithm(BFOA),再谈到Ramdom Walk Graph Segmentation图分割算法】
- Node2vec算法原理深度研究
- 【Graph Embedding】node2vec:算法原理,实现和应用
- 【Graph Embedding】: node2vec算法
- 【图网络笔记-知识补充与node2vec代码注解】