【ML笔记】5、支持向量机(SVM)
支持向量机(SVM)是一个强大的和通用的ML模型,能够执行分类,回归,甚至异常值检测,特别适合于复杂的中小型数据集。
1、线性SVM分类

我们可以看到,这两个类可以很容易地用一条直线(线性可分)分开。左图显示了三种可能的线性分类器的决策边界。虚线模型很糟糕,没有将两组实例线性分开。另外两个模型在训练集上工作得很好,但它们的边界太接近训练数据点,可能在未见数据上表现不佳(泛化能力不够好)。
相比之下,右边的模型不仅线性分离了训练数据,而且尽可能远离这两类数据点。因此,它很可能在未见的数据上表现良好(泛化能力较好)。
我们可以认为SVM是在类之间拟合尽可能宽的街道(由虚线表示),这就是所谓的大间隔分类。且添加更多的样本点在“街道”外并不会影响到判定边界,因为判定边界是由位于“街道”边缘的样本点确定的,这些样本点被称为“支持向量”(右图中粉色圈圈出的训练数据点)。
SVM同样也是对特征提取敏感的。
软间隔分类
如果我们将所有的训练实例限制在SVM街道之外,这被称为硬间隔分类,硬间隔分类在很大程度上受到异常值的影响。可以想象到离群值(异常值)会搞乱硬边距分类器:

左图因为离群值的存在,甚至不能拟合出合适的SVM分类(线性不可分),右图虽然线性可分但是间隔很小。
为了避免上述问题,我们更倾向于使用软性模型。目的在保持“街道”尽可能大和避免间隔违规(例如:数据点出现在“街道”中央或者甚至在错误的一边)之间找到一个良好的平衡,这就是软间隔分类。
在Scikit-Learn库的SVM类,你可以用C超参数(惩罚系数)来控制这种平衡:较小的 C 会拟合更宽的“街道”,但会带来更多的间隔违规:

要注意,C值更小的模型虽然间隔违规点更多,但分类器似乎泛化性更好:在这个训练数据集上减少了预测错误,因为实际上大部分的间隔违规点出现在了判定边界正确的一侧。因此如果你的模型过拟合,你可以尝试通过适当减小超参数 C 去调整。
以下的Scikit-Learn 代码加载了内置的鸢尾花(Iris)数据集,缩放特征,并训练一个线性SVM模型(使用 LinearSVC 类,超参数 C=1 ,hinge 损失函数)来检测 Virginica鸢尾花。
import numpy as np
from sklearn import datasets
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris["data"][:, (2, 3)] # petal length, petal width
y = (iris["target"] == 2).astype(np.float64) # Iris-Virginica
svm_clf = Pipeline((
("scaler", StandardScaler()),
("linear_svc", LinearSVC(C=1, loss="hinge")),
))
svm_clf.fit(X, y)
svm_clf.predict([[5.5, 1.7]])
![]()
与逻辑回归模型(使用sigmoid函数)不同,支持向量机不输出每个类的概率,只给出推理结果。
可以选择使用 SGDClassifier类代替LinerSVC,即SGDClassifier(loss="hinge", alpha=1/(m*C)) 。它应用了随机梯度下降来训练一个线性 SVM 分类器。尽管它不会和 LinearSVC 一样快速收敛,但是对于处理那些不适合放在内存的大数据集是非常有用的,或者处理在线分类任务同样有用。
2、非线性SVM分类
如果数据集不是线性可分的,如果你增加了第二个特征x2=(x1)^2,产生的 2D 数据集就能很好的线性可分。
通过Scikit-Learn,你可以创建一个流水线(Pipeline)去包含多项式特征(PolynomialFeatures) 变换:
from sklearn.datasets import make_moons
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
polynomial_svm_clf = Pipeline((
("poly_features", PolynomialFeatures(degree=3)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge"))
))
polynomial_svm_clf.fit(X, y)polynomial_svm_clf.score(X, y)
下图表示模型的决策边界,因为我们添加了多项式degree,投影边界现在是非线性的

多项式核
添加多项式特征很容易实现,但是低阶多项式不能处理非常复杂的数据集,而高阶多项式却产生了大量的特征,会使模型变得慢。
幸运的是,当你使用 SVM 时,你可以运用一个被称为“核技巧”(kernel trick) 的神奇数学技巧。它可以取得就算你添加了许多多项式,甚至有高次数的多项式,也有一样好的结果。
from sklearn.svm import SVC
poly_kernel_svm_clf = Pipeline((
("scaler", StandardScaler()),
("svm_clf", SVC(kernel="poly", degree=3, coef0=1, C=5))
))
poly_kernel_svm_clf.fit(X, y)
这段代码用3阶的多项式核训练了一个 SVM 分类器,如左图所示。作为对比,右图是使用了10阶的多项式核 SVM 分类器。很明显,如果你的模型过拟合,你可以减小多项式核的阶数。相反的,如果是欠拟合,你可以尝试增大它。超参数 coef0 控制了高阶多项式与低阶多项式对模型的影响:

通用的方法是用网格搜索去找到最优超参数。首先进行非常粗略的网格搜索,一般会很快,然后在找到的最佳值进行更细的网格搜索。对每个超参数的作用有一个很好的理解可以帮助你在正确的超参数空间找到合适的值。
增加相似特征
略
高斯rbf核
略
计算复杂性
略
3、SVM回归
SVM不仅仅支持线性和非线性的分类任务,还支持线性和非线性的回归任务。目标:限制间隔违规的情况下,不是试图在两个类别之间找到尽可能大的“街道”(即间隔) 。SVM 回归任务是限制间隔违规情况下,尽量放置更多的样本在“街道”上。“街道”的宽度由超参数 ϵ 控制。下面两个SVM回归模型,一个有较大的间隔(ϵ=1.5 ) ,另一个间隔较小(ϵ=0.5 )。
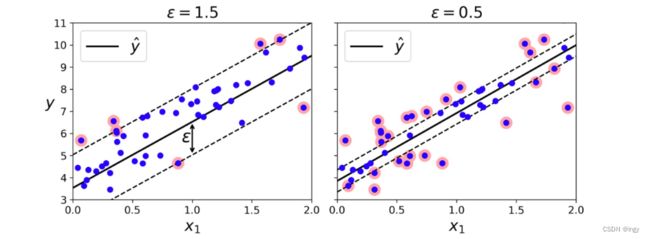
添加更多的数据样本在间隔之内并不会影响模型的预测,所以,这个模型被认为是不敏感的(-insensitive)。
你可以使用 Scikit-Learn 的 LinearSVR 类去实现线性 SVM 回归:
from sklearn.svm import LinearSVR
svm_reg = LinearSVR(epsilon=1.5)
svm_reg.fit(X, y)
为了处理线性回归任务,我们可以使用核化SVM模型,用多项式核函数来做:
from sklearn.svm import SVR
svm_poly_reg = SVR(kernel="poly", degree=2, C=100, epsilon=0.1)
svm_poly_reg.fit(X, y)
其使用了 Scikit-Learn 的 SVR 类(支持核技巧) 。在回归任务上, SVR 类和 SVC 类是一样的,LinearSVR等价于LinearSVC 。
4、底层原理
略(后续补)
练习