DeiT论文精读
论文地址:https://arxiv.org/abs/2012.12877v2
代码地址:https://github.com/facebookresearch/deit.
Abstract
transformer需要使用大型基础设施对数亿张图像进行了预训练,从而限制了它们的使用。 在这项工作中,作者只在图像上训练transformer。在一台电脑上训练他们不到3天。基于vision transformer(86M参数)在没有外部数据的情况下,在ImageNet上达到了83.1%。
更重要的是,作者引入了一种专门针对transformer的teacher-student策略。它依赖于一个蒸馏token,确保学生模型通过注意力机制从老师模型那里学习。当使用卷积模型作为教师模型时,这种基于token的蒸馏方法能够取得十分优异的性能。
1 Introduction
Vision transformer论文的结论是,transformer“在数据量不足的训练下不能很好地泛化”,而这些模型的训练涉及大量的计算资源。
在本文中,作者在2到3天内(53小时的预训练,以及20小时的微调)在一个8-GPU节点上训练一个 Vision transformer,这与具有相似数量参数和效率的模型进行对比取得了优异的性能。它使用Imagenet作为唯一的训练集。
作者还解决了另一个问题:如何提取这些模型?并引入了一种基于token的蒸馏策略,特定于transformer,用DeiT⚗表示,并表明它有利地取代了通常的蒸馏
 贡献如下:
贡献如下:
作者表明,与同类工作相比,单纯的transformer模型可以在没有外部数据的情况下在ImageNet上获得优异的结果。它们在三天内在一个有4个gpu的单一节点上学习。两种新模型DeiT-S和DeiT-Ti的参数较少,可以被看作与ResNet-50和ResNet-18相当。
作者引入了一种新的基于蒸馏token的蒸馏程序,它扮演着与class token相同的作用,除了它的目的是复制由教师模型估计的标签。这两个token都通过注意力机制在transformer中相互作用。这种特定于transformer的策略明显优于vanilla distillation。通过蒸馏,transformer从卷积模型学习到的比从另一个性能相当的transformer学习到的更多,性能更优。
作者还探究了imagenet上预训练的模型在转移到不同的下游任务,如细粒度分类,在几个流行的公共基准上: CIFAR-10,CIFAR-100,Oxford-102 flflowers,,Stanford Cars and iNaturalist-18/19.。
2 Related work
Knowledge Distillation
(KD),由Hinton等人提出,它指的是学生模型利用来自强大教师网络的“软”标签的训练方式。这是教师模型的softmax函数的输出向量,而不仅仅是最高分数,它给出了一个“硬”标签。这样的训练提高了学生模型的表现(或者,它可以看作是将教师模型压缩成一个更小的模型——学生模型的一种形式)。一方面,教师模型的软标签将有类似于标签平滑[58]的效果。另一方面,如Wei等人[54]所示,教师模型的监督考虑了数据增强的影响,这有时会导致真实标签和图像之间的错位。例如,让我们考虑一个带有“猫”标签的图像,它代表一个大的景观和一个角落里的小猫。如果猫不再在数据增强的作物上,它会隐式地更改图像的标签。KD可以在学生模型中转移归纳偏差[1],它们将以艰难的方式合并。例如,通过使用卷积模型作为教师,在transformer模型中引起由卷积引起的偏差可能是有用的。本文研究了transformer教师模型对transformer学生模型的蒸馏过程。介绍了一种针对transformer的新型蒸馏方法,并证明了它的优越性
4 Distillation through attention
本节涵盖了蒸馏的两个维度:硬蒸馏与软蒸馏,以及经典蒸馏与蒸馏token。
Soft distillation 最小化教师的softmax和学生模型的softmax之间的差异。
设Zt为教师模型的对数,Zs为学生模型的对数。用τ表示蒸馏温度,λ表示地面真实标签y上平衡KL散度和交叉熵(LCE)的系数,ψ表示softmax函数。蒸馏目的是:
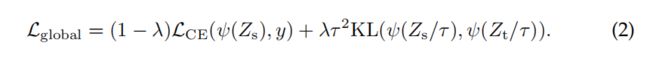
Hard-label distillation. 作者引入了一种蒸馏的变体,其中我们把教师模型的艰难决定作为一个真正的标签。让![]() 成为教师模型的艰难决定,与这种硬标签蒸馏相关的目标是:
成为教师模型的艰难决定,与这种硬标签蒸馏相关的目标是:
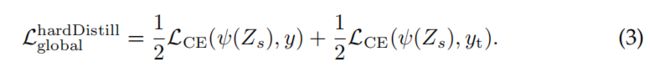
对于一个给定的图像,与教师模型相关联的硬标签可能会根据特定的数据增强而改变。我们将看到,这个选择比传统的选择更好,同时没有参数,在概念上更简单:教师模型预测yt与真正的标签y扮演相同的角色
还要注意,硬标签也可以通过标签平滑[47]转换为软标签,其中真正的标签被认为的概率为1−ε,其余的ε在其余类中共享。在所有使用真标签的实验中,作者将这个参数固定为ε = 0.1。
Distillation token. 如图2所示。作者向初始embeding(patch和class token)添加了一个新的token,即蒸馏token。我们的蒸馏token与cls token类似地使用:它通过自注意力机制与其他embeding进行交互,并在最后一层之后由网络输出。其目标由损失的蒸馏分量给出。蒸馏embeding允许学生模型从教师模型的输出中学习,就像在常规的蒸馏中一样,同时与class embeding保持互补。
 作者还观察到学习到的类和蒸馏token收敛于不同的向量:这些标记之间的平均余弦相似度等于0.06。随着类和蒸馏embeding的计算,它们通过网络逐渐变得更加相似,一直到最后一层相似性高(cos=0.93),但仍然低于1。这是意料之中的,因为它们的目标是产生相似但不完全相同的目标。
作者还观察到学习到的类和蒸馏token收敛于不同的向量:这些标记之间的平均余弦相似度等于0.06。随着类和蒸馏embeding的计算,它们通过网络逐渐变得更加相似,一直到最后一层相似性高(cos=0.93),但仍然低于1。这是意料之中的,因为它们的目标是产生相似但不完全相同的目标。
作者验证了蒸馏token向模型添加了一些东西,与简单地添加一个与相同目标标签相关联的额外cls token相比:作者实验了一个具有cls token的转换器,而不是一个教师模型的伪标签。即使随机且独立地初始化它们,在训练过程中,它们收敛于相同的向量(cos=0.999),并且输出embeding也是拟相同的。这个附加的cls token不会对分类性能产生任何影响。相比之下,作者蒸馏策略比vanilla distillation基线提供了显著的改进,我们在第5.2节中的实验验证了这一点。
Fine-tuning with distillation. 作者在更高分辨率的微调阶段同时使用真实的标签和教师模型的预测。使用具有相同目标分辨率的教师模型,通常通过Touvron等人[50]的方法从低分辨率的教师模型那里获得。作者测试了只使用真正的标签,但这降低了教师模型带来的模型性能的改善,导致了较低的表现。
Classifification with our approach: joint classififiers. 在测试时,由transformer产生的类或蒸馏embeding都与线性分类器相关联,并能够推断出图像标签。然而,作者的参考方法是这两个独立的头部的后期融合,为此,模型添加了两个分类器的softmax输出来进行预测。我们将在第5节中评估这三个选项。
5 Experiments
5.1 Transformer models
DeiT设计与VIT相同。唯一的区别是训练策略和蒸馏embeding。此外,作者不使用MLP头进行预训练,而只是一个线性分类器。为了避免混淆,参考ViT在之前的工作中获得的结果,并以DeiT作为作者模型的前缀。如果没有指定,DeiT指的是参考模型DeiT-B,它具有与ViT-B具有相同的体系结构。当作者在更大的分辨率下微调DeiT时,作者会在最后附加结果的操作分辨率,例如,DeiT-B↑384。最后,当使用蒸馏过程时,用一个平衡符号来标识它为DeiT⚗。
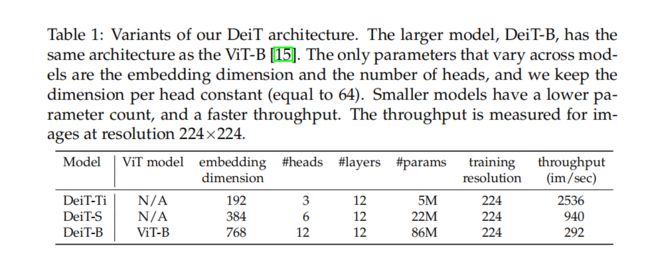
ViT-B(以及DeiT-B)的参数固定为D = 768,h = 12和d = D/h = 64。作者引入了两个较小的模型,即DeiT-S和DeiT-Ti,为此改变了头的数量,保持d固定。表1总结了在论文中考虑的模型。
5.2 Distillation
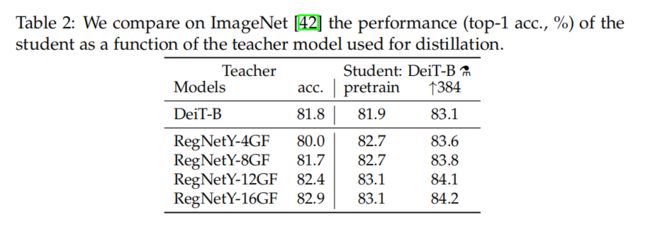
Convnets teachers. 作者已经观察到,使用卷积模型作为教师比使用transformer有更好的性能。原因可能是由于transformer通过蒸馏继承了卷积模型的感应偏差,在随后的所有蒸馏实验中,默认的教师模型是一个RegNetY-16GF [40](84M参数),作者使用与DeiT相同的数据和相同的数据增强进行训练。教师模型在ImageNet上的准确率达到了82.9%。
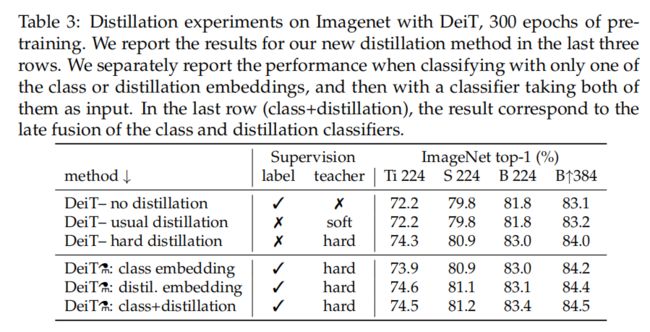
Comparison of distillation methods. 对于transformer来说,硬蒸馏显著优于软蒸馏,即使只使用一个cls token。在第4节中的蒸馏策略进一步提高了性能,表明这两个token提供了对分类有用的互补信息:这两个token上的分类器明显优于独立的类和蒸馏分类器,它们本身的性能已经优于蒸馏基线。
蒸馏embeding提供的结果略优于cls embeding。它也与卷积模型预测更相关。这种性能上的差异可能是由于它从卷积模型的归纳偏差中获益更多。蒸馏embeding在初始训练中具有不可否认的优势。
Agreement with the teacher & inductive bias?
蒸馏模型与卷积模型的相关性比从头学习的transformer更强。可以预期,与蒸馏embeding相关的分类器更接近卷积模型的输出结果,而与cls embeding相关的分类器更类似于未蒸馏学习的DeiT。联合 类+蒸馏 分类器提供了一个中间立场。
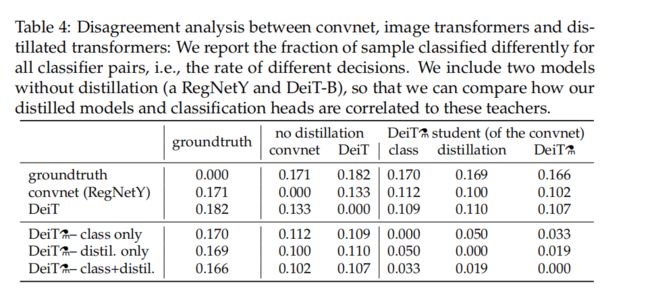 Number of epochs. 增加epoch的数量显著提高蒸馏训练的性能
Number of epochs. 增加epoch的数量显著提高蒸馏训练的性能
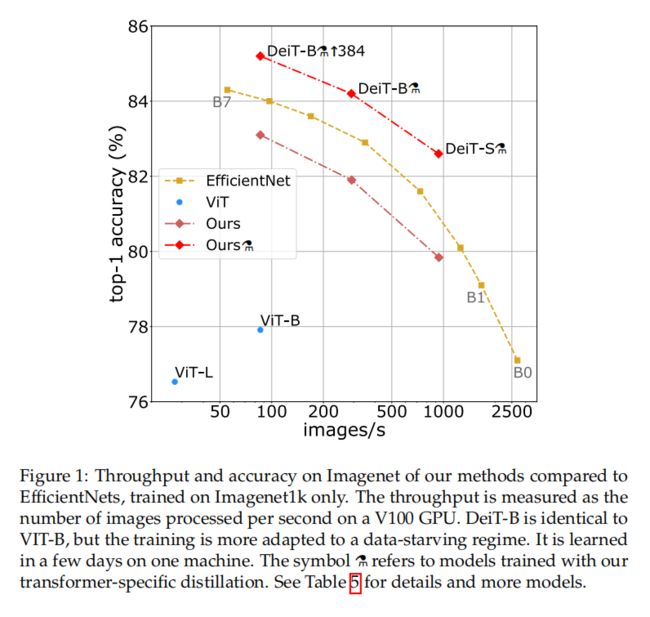
5.3 Effificiency vs accuracy: a comparative study with convnets

5.4 Transfer learning: Performance on downstream tasks
Comparison vs training from scratch. 在CIFAR-10从头训练
在这个实验中,(1)考虑更长的训练计划(多达7200个,对应于300个),这样网络总共得到了相当数量的图像;(2)我们将图像重新调整到224×224,以确保有相同的增强。结果不如Imagenet预训练好(98.5% vs 99.1%),这是意料之中的,因为该网络的多样性要低得多。然而,他们表明,仅在CIFAR-10上学习一个合理的transformer是可能的

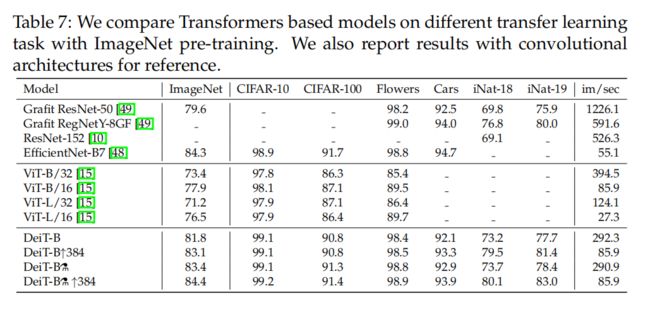
6 Training details & ablation
Initialization and hyper-parameters. transformer对初始化相对敏感。作者遵循Hanin和Rolnick [20]的建议,用截断的正态分布初始化权值。
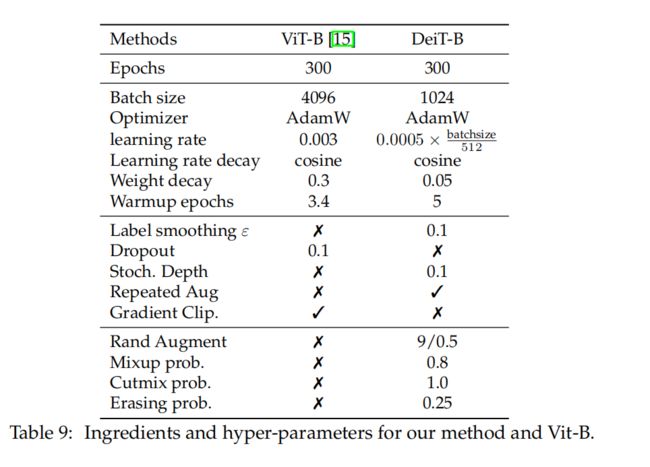
表9说明了在所有实验中在训练时默认使用的超参数,除非另有说明。对于蒸馏,按照Cho等人[9]的建议来选择参数τ和λ。取典型的值τ = 3.0和λ = 0.1来进行通常的(软)蒸馏。
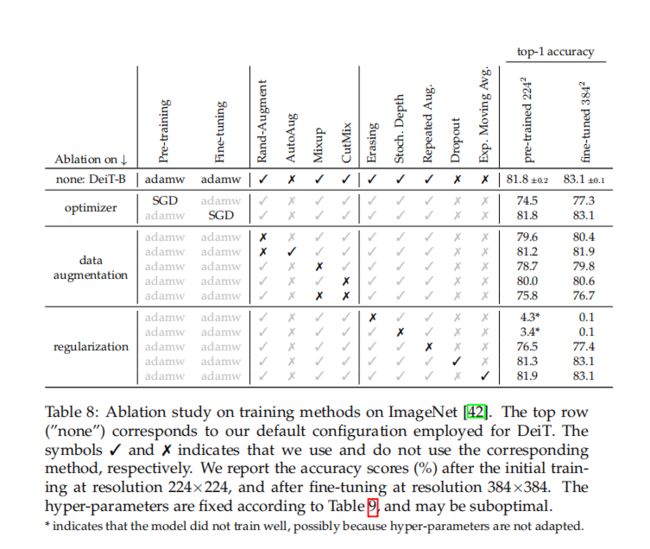
Data-Augmentation. Auto-Augment[11]、Rand-Augment[12]和random erasing[62]改善了结果。对于后两种情况,使用timm [55]定制,在消融后,我们选择Rand-Augment而不是Auto-Augment。总的来说,实验证实了transformer需要一个强大的数据增强:评估的几乎所有的数据增强方法都被证明是有用的。一个例外是dropout,将其排除在训练程序之外。
Regularization & Optimizers.
Exponential Moving Average (EMA).
评估了经过训练后获得的网络的EMA。有一些小的增益,但在微调后消失:EMA模型的边缘为0.1个精度点,但当微调时,两个模型达到相同的(改进的)性能。
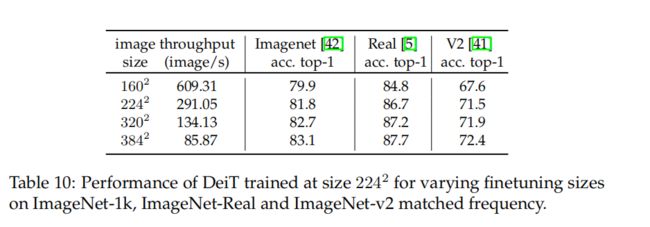
Fine-tuning at different resolution.