DietCode:TVM中新的动态Shape解决方案
近年来,随着深度学习领域动态 shape 推理场景激增,如机器翻译、语音识别等,针对动态 shape 模型的优化成为了热门研究议题。本文主要介绍了 DietCode 的整体架构设计,尝试了解 DietCode 如何针对动态 shape 进行调优。以 BERT 模型为例,DietCode 与 Ansor 相比, 搜索时间减少 5.88倍,性能提高约 70%。DietCode项目已经开始合入TVM中,但目前来看,只是在 tir 优化 Pass 中增加了 LocalPad,其他 feature 还未合入。
1 背景
在机器学习领域,提高计算密集型算子的性能是一项极具挑战的工作,目前业界主要有两种解决方案:使用供应商的算子库或使用 auto-scheduler 来完成算子调优。然而,前者需要大量的工程工作,算子开发周期长,限制多且专业性强;后者在 TVM 中只支持输入为静态形状的工作负载,以便模型编译时获得形状大小,如果输入为动态形状,将会导致极长的调优时间,这是因为整个搜索空间与形状强相关,auto-scheduler 不能为所有可能形状的工作负载构造一个确定的搜索空间。为了解决以上问题,DietCode 应运而生。
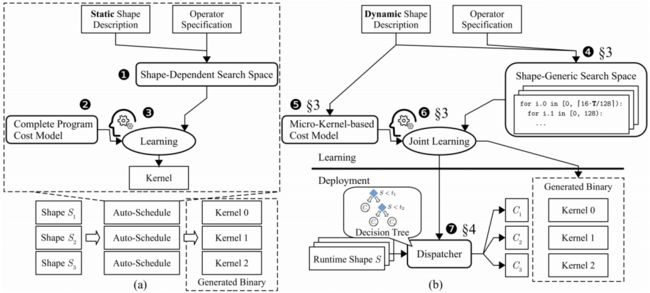
目前,TVM中 auto-scheduler(如:Ansor)的整体流程,如图1(a)所示,详细信息请参考Ansor: 为深度学习生成高性能张量程序。它的的输入为 TE(张量表达式),TE 中包含了算子的计算描述和形状信息。auto-scheduler 首先制定一个搜索空间,该搜索空间由 TE 派生出的实现(图 1(a) 中的 ①)组成,然后构建一个代价模型来预测每个 schedule 的运行时性能(图 1(a) 中的 ②)。在整个自动调度过程中,代价模型通过真实的硬件测量不断更新,并用于指导搜索空间内的探索(图 1(a) 中的 ③)。
2 DietCode 设计
如图1(b)所示,DietCode 框架主要有三个创新点:
构建一个由 micro-kernels 组成的通用形状搜索空间,来支持动态形状的工作负载(图 1(b) 中的 ④)。使用硬件约束(如:线程的最大数量、共享内存大小)来确定 micro-kernels 候选,从而消除了对形状的依赖,这些候选充当构建块,并反复执行来计算整个工作负载实例;
构建基于 micro-kernels 的代价模型(图 1(b) 中的 ⑤)。整个代价模型可以分解为两部分:shape-generic 代价模型 和 shape-dependent 自适应代价模型 。 需要在自动调度过程中,根据硬件测试进行学习和更新, 可以用核心占用率和填充比直接评估;
使用 sklearn 训练了一个决策树模型(图 1(b) 中的 ⑦),来为每个输入形状分配对应的 micro-kernel,决策树模型的输入为动态形状,输出是 micro-kernel。
DietCode 的优化流程是一个多任务学习(joint learning)的过程(图 1(b) 中的 ⑥),其中动态形状工作负载的实例共享相同的搜索空间并共同学习相同的代价模型。此流程使 DietCode 能够在每个类别的基础上进行操作,其中每个类别共享相同的形状通用程序(即 micro-kernel)。
3 实现细节
3.1 Local Padding
DietCode 的关键思想之一是将 micro-kernels 通用地应用于所有工作负载实例,但是,工作负载实例通常不能完美地适应 micro-kernel,如图2所示,在这些情况下,需要在 micro-kernel 中注入边界检查,以确保程序不会对无效数据进行操作。

图2 工作负载不能整除 micro-kernel 情况下的解决方案
有三种解决方案可以缓解以上问题,如图3所示,(a) 表示带有边界检查的平铺循环。(b-d) 表示三种优化策略:(b) 全局填充,(c) 循环分区,和 (d) 局部填充,具体如下:
Global padding。可以在kernel计算时消除边界检查,但是 pad 和 slice 需要额外的存储和计算;
Loop partitioning。划分为边界检查的可消除区和不可消除区,并且 t << T 时,才会受益;
Local padding。在从内存中获取和写回阶段保留边界检查,同时在计算阶段删除边界检查(计算阶段占主要影响,从内存获取和写回阶段可被内存传输延迟隐藏)。
综上,DietCode 选择 local padding 方案,因为不会产生额外的存储开销,并且可以通用地应用于各种大小的形状。

图3 边界检查
3.2 基于 Micro-Kernel 的 Cost Model
为了准确预测基于 micro-kernel 的完整程序的性能,DietCode 的代价模型设计分为三部分,分别为:① micro-kernel 的性能,②硬件核心占用惩罚,③padding 惩罚。图 4 说明了代价模型中三部分之间的相关性和对应关系,这种对应关系为准确预测基于 micro-kernel 的完整程序的性能提供了强有力保障。代价模型的数学表达式如下:
M 表示 micro-kernel,P 表示程序, 表示硬件核心占用惩罚,数学系表达式为线性回归模型,如下所示:
其中 P/M 项对应于执行 M 以形成 P 的次数,系数 k、b 是可学习的参数。由于每个 micro-kernel 都被分配给一个硬件内核,因此 P/M 也与占用的硬件内核数相关。因此, 表示使用 M 组成的完整程序 P 的硬件占用率。
填充惩罚,可以用与硬件无关的方式建模为:
图4 DietCode 的代价模型
3.3 自动调度
多任务学习过程完成后,DietCode 会生成多个 micro-kernels。为了将所有的输入形状分配给最合适的 micro-kernel,设计了一个公式,如下所示:
其中,P(S, M) 表示使用微内核 M 组成的形状 S 的完整程序,在所有形状都投票后,使用 scikit-learn 框架训练决策树,决策树的输入是所有可能的形状,输出标签是它们选择的 micro-kernel。生成的决策树自动将选择相同 micro-kernel 的形状归类在一起,并以 C 代码格式导出,以便在运行时从输入形状高效调度到其对应的 micro-kernel。
4 整体分析
DietCode 主要提出了 micro-kernel 的概念来解决动态 Shape 在TVM中自动调度的问题,极大减少了搜索时间。但本质上仍然是一种“分组”策略,将动态问题转化为静态问题。在我们之前的实践中,针对bert模型的优化,使用过一种类似“桶分组”的方法,但是“分组”概念停留在了模型层面,导致了不小的存储开销,并且最终性能的提升取决于输入的分布情况,很明显,输入非均匀分布的时候,很多模型的存在意义很低。DietCode 将“分组”下沉,将会节省大量的存储空间,并且它更大的优势是自动搜索,降低搜索时间。此外,针对静态 shape 的模型推理,我们研究过在 AutoTVM 中 引入 micro-kernel,经过合理的设计,确实能够降低搜索时间,并且算子规模越大,加速效果越明显。而针对动态 shape 的推理,DietCode 提供了一个不错的方法,后续将会对其进行验证和探索。如有理解偏差,欢迎讨论。
参考
[1] 论文地址:https://proceedings.mlsys.org/paper/2022/hash/fa7cdfad1a5aaf8370ebeda47a1ff1c3-Abstract.html
[2] TVM-RFC:https://github.com/apache/tvm-rfcs/blob/main/rfcs/0072-dynamic-autoscheduler.md
