利用python从图像数据中提取特征的三种技术
来源:
https://www.analyticsvidhya.com/blog/2019/08/3-techniques-extract-features-from-image-data-machine-learning-python/
参考
使用sobel、prewitt、拉普拉斯算子、差分法提取图像的边缘
https://blog.csdn.net/Chaolei3/article/details/79809703
opencv-032-图像梯度之robert算子与prewitt算子
https://fanfuhan.github.io/2019/04/09/opencv-032/
目录
1.机器如何存储图像?
2.用Python读取图像数据
3.从图像数据中提取特征的方法#1:灰度像素值作为特征
4.从图像数据中提取特征的方法2:通道的平均像素值
5.从图像数据中提取特征的方法#3:提取边缘
1.机器如何存储图像?
1.1 黑白图像
以一个简单的例子开始,如下图:

该图像由多个小方块组成,这些称为像素。
我们通常可以轻松地区分图片中内容的边缘和颜色。但是计算机很难做到这一点。它们以数字形式存储图像。如下图:

机器以数字矩阵的形式存储图像。这个矩阵的大小取决于我们在任何给定图像中拥有的像素数。
图片的尺寸为 180 * 200,故图像中像素的数量即为 180*200
这些数字或像素值表示像素的强度或亮度。较小的数字(接近零)表示黑色,较大的数字(接近255)表示白色。
1.2 彩色图像
彩色图像通常由多种颜色组成,几乎所有颜色都可以由三种原色(红色,绿色和蓝色)生成,即RGB图像。
因此,针对彩色图像,存在三个矩阵(或通道)–红色,绿色和蓝色。每个矩阵的值介于0-255之间,代表该像素的颜色强度。这三个矩阵叠加形成彩色图像。如下图:

2.用Python读取图像数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import cv2
image = cv2.imread('article-image-21-236x300.png')
#cv2.imshow(image)
#checking image shape
print('Shape of the image is = ',image.shape)
# image matrix
#print('\n\nImage matrix\n\n',image)
#out<<
Shape of the image is = (28, 28, 3)
#basic function
#将图片由彩色转化为灰度图
imgGray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
#checking image shape
print('Shape of the image is = ',imgGray.shape)
# image matrix
#print('\n\nImage matrix\n\n',imgGray)
#out<<
Shape of the image is = (28, 28)
现在,让我们深入探讨本文背后的核心思想,并探索使用像素值作为特征的各种方法。
3.从图像数据中提取特征的方法#1:灰度像素值作为特征
图像创建特征的最简单方法是将这些原始像素值用作单独的特征。
考虑上面的图像的相同示例(数字“ 8”)–图像的尺寸为28 x 28,即特征数量与像素数量相同,为784.
那么如何将这784个像素作为特征排列?其实,我们可以简单地将每个像素值一个接一个地附加以生成特征向量。如下图所示:

image_puppy = cv2.imread('puppy.jpg')
image_puppyGray = cv2.cvtColor(image_puppy,cv2.COLOR_BGR2GRAY)
#checking image shape
#print('Shape of the image is = ',image_puppyGray.shape)
# image matrix
print('\n\nImage matrix\n\n',image_puppyGray)
#out<<
Shape of the image is = (241, 209)
此处的图像形状为241 x 209。因此,要素数量应为241*209。我们可以使用NumPy的reshape函数生成此图像,在此我们指定图像的尺寸:
#pixel features
features = np.reshape(image_puppyGray, (241*209))
features.shape, features
#out<<
((50369,), array([180, 197, 185, ..., 139, 153, 151], dtype=uint8))
这样我们就得到了该图像的特征。
4.从图像数据中提取特征的方法2:通道的平均像素值
#读取彩色图像
#输出其大小
#checking image shape
print('Shape of the image is = ',image_puppy.shape)
#out<<
Shape of the image is = (241, 209,3)
这次,图像的尺寸为(241, 209,3),其中3是通道数。在这种情况下,特征数量将为2412093 。
我们可以生成一个具有来自三个通道的像素平均值的新矩阵。

这样,特征的数量保持不变,并且我们还考虑了来自图像三个通道的像素值。我们将创建一个尺寸为241*209的新矩阵,其中所有值均初始化为0。此矩阵将存储三个通道的平均像素值:
feature_matrix = np.zeros((241,209))
print(feature_matrix.shape)
#out
(241, 209)
我们有一个尺寸为(2412093)的3D矩阵,其中241是高度,209是宽度,3是通道数。为了获得平均像素值,我们将使用一个for循环:
for i in range(0,image_puppyGray.shape[0]):
for j in range(0,image_puppyGray.shape[1]):
feature_matrix[i,j] = ((int(image_puppy[i,j,0]) + int(image_puppy[i,j,1]) + int(image_puppy[i,j,2]))/3)
特征矩阵大小为241*209,接下来我们将其化为一维数组。
feature = np.reshape(feature_matrix,(241*209))
print(feature.shape)
#out<<
(50369,)
5.从图像数据中提取特征的方法#3:提取边缘
如下图,我们可以很容易地确定其中存在的对象,即狗,汽车和猫。其实我们在区分这些物体时,可能会考虑一些特征,首先是形状,其次是颜色或大小。可是如果想让计算机像我们一样识别图像中物体,他应该如何识别物体的形状呐?

我们的想法可能是提取边缘作为特征并将其输入模型。那我们如何识别图像的边缘?其实边缘基本上是颜色急剧变化的地方。如下图:
因为颜色从白色变为棕色(在右图),从棕色变为黑色(在左图),所以我们可以识别边缘。我们知道图像是以数字的形式表示,那么寻找像素值周围急剧变化的像素就可以找到边缘。
假设我们有以下图像矩阵:

为了确定像素是否为边缘,我们将简单地减去该像素点周围的值。在该矩阵中,明显突出的像素值为85。我们将找到值89和78之间的差异。但是该差异很小,所以该像素周围没有边缘。
现在考虑下图中明显突出的像素125:

由于此像素两侧的值之间的差异较大,因此可以得出结论,此像素存在明显的过渡,因此是边缘。
当然由于像素过多,我们不可能手动寻找这种差异,这里我们使用可用于突出显示图像边缘的内核。
其实这种内核有很多,我们这里采用Prewitt内核(在x方向上)实现。
下面是Prewitt内核:
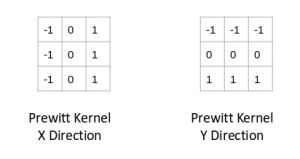
我们将所选像素周围的值乘以所选内核(Prewitt内核)。然后,我们可以将结果值相加以获得最终值。因为我们已经在一列中有-1,在另一列中有1,所以将这些值相加就等于求和。

还有其他各种内核,我在下面提到了四个最常用的内核:

#!/usr/bin/env python
# -*- coding: utf-8 -*-
# author:lucky
# albert time:2020/9/29
#importing the required libraries
import numpy as np
import cv2 as cv
#reading the image
img = cv.imread('puppy.jpg')
# cv.namedWindow("input", cv.WINDOW_AUTOSIZE)
# cv.imshow('input',img)
# #将图片转化为灰度图
# imgGray = cv.cvtColor(img,cv.COLOR_BGR2GRAY)
#prewitt算子-卷积核
prewitt_x = np.array([[-1,0,-1],[-1,0,-1],[-1,0,-1]],dtype=np.float32)
prewitt_y = np.array([[-1,-1,-1],[0,0,0],[1,1,1]],dtype = np.float32)
#卷积操作
prewitt_grad_x = cv.filter2D(img,cv.CV_32F,prewitt_x)
prewitt_grad_y = cv.filter2D(img,cv.CV_32F,prewitt_y)
prewitt_grad_x = cv.convertScaleAbs(prewitt_grad_x)
prewitt_grad_y = cv.convertScaleAbs(prewitt_grad_y)
#展示图片
# cv.imshow("prewitt x", prewitt_grad_x);
# cv.imshow("prewitt y", prewitt_grad_y);
# print(img.shape)
#将三张图像合并到一张图像上
h,w = img.shape[:2]
img_result = np.zeros([h,3*w,3],dtype= img.dtype)
img_result[0:h,0:w,:] = img
img_result[0:h,w:2*w,:] = prewitt_grad_x
img_result[0:h,2*w:3*w,:] = prewitt_grad_y
#图片展示
cv.imshow('result',img_result)
#保存
cv.imwrite("prewitt.png",img_result)
#添加延迟
cv.waitKey(0)
原图

结果图

代码已上传github
https://github.com/xiaoliyu00/python_opencv