后缀自动机 AC自动机
trie树可遍历出所有无重复后缀,通过后缀遍历前缀可得到所有子串;后缀链接把所有后缀相同的状态(以当前节点为endpos的子串)连接起来,便有了类似KMP的next数组的性质。
——后缀自动机使用理解
AC自动机和后缀自动机算是算法竞赛中字符串算最难、最抽象的吧。
其中又以后缀自动机为大BOSS。
它用途广泛,性能优越,受到万千算法选手青睐;但是其学习却让人痛苦万分。
我花了三天断断续续学了五六个小时才勉强弄懂它的构造原理,期间看了数十个视频、博客,听大佬长篇大论地证明时,我一度怀疑自己是不是脑子不好使。但是看一眼评论区,大家平均都是好几天才能学会,那我也不算太差吧。(弱校没有学长带的痛)
好吧回到正题。
根据我的学习经验,一切把SAM构造当黑盒用的都是扯淡,看大佬一万字数学证明来学更是扯淡。最好还是看形象的,图形化的讲解为佳。
如:
后缀自动机 suffix-automaton_哔哩哔哩_bilibili后缀自动机多图详解(代码实现) - maomao9173 - 博客园
后缀自动机简单解释:
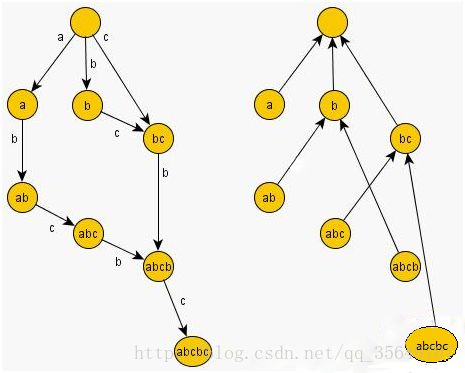
后缀自动机是复杂的树形结构,是字符串的魔幻压缩方式,其主要包含两种边:trie边表示字符间的连接,总体上你能从根节点到叶子节点的简单路径中找到该字符串的任意后缀。第二种边是后缀连接,用来在树上转移,这也是自动机的精髓(毒瘤)所在。
先感性理解:你要在trie上表示所有后缀,那么重复的后缀肯定就不能出现。那么找重复的后缀就是后缀连接的作用,连接后缀的字符就是trie边的作用。
那么搞清楚后缀连接的原理就成了最痛苦的环节。
我们从整个字符串的构建开始思考。
我们从左到右依次构建。
那么每次向右遇到的字符就是要插入的字符,也是新的后缀。假如前面有 个字符,那么添加第
个字符,那么添加第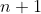 个字符就会改变所有个后缀。此时我们要找出所有出现的后缀中以前出现过的,那是我们不需要的冗余数据。
个字符就会改变所有个后缀。此时我们要找出所有出现的后缀中以前出现过的,那是我们不需要的冗余数据。
所以此时就要靠后缀连接了。
后缀连接就是把((根节点到该点)形成的(后缀相同的)串的)点连接起来,这样每次更新后缀只需要找最后一次插入的点的后缀连接一路判断上去即可。因为新后缀除去最后一个插入的字符还是上次的后缀,所以我们每次跑到后缀连接上就判断这里有没有连接新插入字符,有的话就说明有重复了。一直保持这个过程就能完成更新。
其中有两个特殊情况就要用![]() 数组特判。
数组特判。
一个是:
if(tre[q].len==tre[p].len+1)tre[np].fa=q;表示以这个点结尾的所有字符串中最长的刚好和没判断的部分后缀接上了,像这样:

另一个即拆点(不能存在两个相同,又不能破坏性质)。
int nq=++cnt;
tre[nq]=tre[q];tre[nq].len=tre[p].len+1;//短的接上
tre[q].fa=tre[np].fa=nq;//新后缀和长部分都连上短部分
for(;p&&tre[p].ch[c]==q;p=tre[p].fa)tre[p].ch[c]=nq;//继承原来的后缀链接void ex_sam(int c){
int p=las,np=las=++cnt;num[cnt]=1;
tre[np].len=tre[p].len+1;
for(;p&&!tre[p].ch[c];p=tre[p].fa)tre[p].ch[c]=np;
if(p==0)tre[np].fa=1;//到根节点
else{
int q=tre[p].ch[c];
if(tre[q].len==tre[p].len+1)tre[np].fa=q;//刚好接上
else{
int nq=++cnt;
tre[nq]=tre[q];tre[nq].len=tre[p].len+1;
tre[q].fa=tre[np].fa=nq;
for(;p&&tre[p].ch[c]==q;p=tre[p].fa)tre[p].ch[c]=nq;
}//分点,复制一份接上
}
}AC自动机
ac自动机最详细的讲解,让你一次学会ac自动机。_creatorx的博客-CSDN博客_自动机
AC自动机 算法详解(图解)及模板_bestsort的博客-CSDN博客_ac自动机、
//如果有这个子节点为字母i+'a',则
//让这个节点的失败指针指向(((他父亲节点)的失败指针所指向的那个节点)的下一个节点)
//有点绕,为了方便理解特意加了括号AC自动机也没什么好搞的,主要后缀自动机能力比它更强,所以AC自动机就显得没什么用了。
kmp
//char a[],b[],int f[],next1[],lb=strlen(b+1),la=strlen(a+1);
// b串自我匹配:关键是找出自己的可能循环点:如abcabd:那么两个ab就有可能作为回溯的点,可能从这里作为字符串的开头向后匹配可以得解;不然就不用回溯,因为没有相同的开头,一直向后就好了;
void KMP(){
next1[1]=0;
for(int i=2,j=0;i<=lb;i++)
{
while(j!=0&&b[i]!=b[j+1])
j=next1[j];
if(b[i]==b[j+1])j++;
next1[i]=j;
}
}
//b串匹配a串:如果到不匹配的地方,按next1中求出的可能循环点回溯,没回溯点说明前面不存在可能的相同开头字串,b从头开始匹配,a接着往后。
void get_f(){
for(int i=1,j=0;i<=la;i++){
while(j>0&&(a[i]!=b[j+1]))
j=next1[j];//退回操作:找j之前中可能的一个节点;
if(a[i]==b[j+1])
j++;
f[i]=j;
if(j==lb){
j=next1[j];
//
}
}
}毁灭吧,累了。
#include
using namespace std;
const int maxn=2e5+10;
#define ll long long
int tre[maxn][26],t_cnt[maxn],t_fail[maxn];
string s[maxn];
int tot=0;
void t_insert(string a){
int now=0,len=a.size();
for(int i=1;iq;
for(int i=0;i<26;i++){
if(tre[0][i]){
t_fail[tre[0][i]]=0;
q.push(tre[0][i]);
}
}
while(!q.empty()){
int now=q.front();
q.pop();
for(int i=0;i<26;i++){
if(tre[now][i]){
t_fail[tre[now][i]]=tre[t_fail[now]][i];
q.push(tre[now][i]);
}
else
tre[now][i]=tre[t_fail[now]][i];
}
}
}
int ask(string a){
int now=0,ans=0,len=a.size();
for(int i=0;i 后缀自动机例题:
查询是否出现:
P1368 【模板】最小表示法 (后缀自动机)_Jack_00_的博客-CSDN博客
不同字串个数(总长度):
【模板】后缀自动机 (SAM) - 洛谷
dp地去搞。因为后缀自动机上每个点都代表一种状态,越往下字串越长,越往上字串越短,而且不重复。我们在跑出来地tre上跑个dp,![dp[i]=1+\sum_{j}^{j\epsilon son(i)}dp[j]](http://img.e-com-net.com/image/info8/8d751f5eda784b54ac87d8907b174a87.gif) 即可。
即可。
总长度:![]() ,可以感性地理解为每往上,那么每个不同地串就加1。
,可以感性地理解为每往上,那么每个不同地串就加1。
/*keep on going and never give up*/
#include
using namespace std;
#define int long long
#define ll long long
#define db(x) cerr<<(#x)<<" "<<(x)<<" "< 字典序第k大子串:
Lexicographical Substring Search - SPOJ SUBLEX - Virtual Judge
搞个玄学拓扑排序(即按长度排序后,由长度来算size,最长的为1,类似上面的dp,可以看作上面串的可能拓展串),再统计一下size。然后递归地在tre上跑:如果k>当前size,说明不在这棵子数上,k-size,去下一棵树;不然就进去当前子树,再跑这个过程即可。
/*keep on going and never give up*/
#include
using namespace std;
#define int long long
#define ll long long
#define db(x) cerr<<(#x)<<" "<<(x)<<" "<=1;i--){
sz[id[i]]=1;
for(int j=0;j<26;j++){
int v=tre[id[i]].ch[j];
if(!v)continue;
sz[id[i]]+=sz[v];
}
}
}
void query(int k){
int x=1;
while (k){
for (int i=0;i<26;i++){
if (tre[x].ch[i]){
if (sz[tre[x].ch[i]]>=k){
putchar('a'+i);
x=tre[x].ch[i];
k--;break;
}else k-=sz[tre[x].ch[i]];
}
}
}
puts("");
}
string s;
signed main(){
cin>>s;
for(auto c:s) ex_sam(c-'a');
tops();
int q;cin>>q;
while(q--){
int k;cin>>k;query(k);
}
} 最长公共字串:
zLongest Common Substring - SPOJ LCS - Virtual Judge
建s,匹配t,如果存在转移,则len+1,否则转移回父节点。有点像KMP的next转移的感觉。
因为fa的后缀都相同,相当于找更短可能后缀的拓展了。
/*keep on going and never give up*/
#include
using namespace std;
#define int long long
#define ll long long
#define inf 1e14
#define db(x) cerr<<(#x)<<" "<<(x)<<" "<>s>>t;
for(auto c:s)ex_sam(c-'a');
cal(t.size());
cout<