论文笔记:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
- 论文:Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering
http://openaccess.thecvf.com/content_cvpr_2018/html/Anderson_Bottom-Up_and_Top-Down_CVPR_2018_paper.html
在以往的图像描述或者视觉问答的深度网络模型中,很多论文和方法都用到的注意力机制,注意力机制能让模型注意到图像的显著区域,使得模型生成的结果更加的准确,对图像位置信息也更加敏感。但之前的注意力机制都是 top-down模式的[1,2].注意力作用的图像特征通过CNN生成,其特征区域大小相等。其语义概念的注意力实现,通过对每个视觉特征附加权重,再求和,得到每一个时间步的注意力权重。然而,人类在聚焦视觉的过程中,可能是根据视觉需要top-down的全局搜索然后再慢慢聚焦,也可以是因为bottom-top某些显著的刺激引起的视觉关注。因此在这篇文章中为了提升注意力的效果,提出了一种结合了top-down与bottom-top的注意力方法。该方法利用目标检测(Faster R-CNN)的方法获取自底向上(bottom-top)的视觉注意力特征(目标检测模型生成的一些视觉候选框,用来作为注意力特征),top-down的注意力方式与之前的空间注意力机制运行工作原理雷同。

利用目标检测的方式获得的空间特征的好处是:注意可以实现实体目标水平的注意力计算,这对于目标显著信息更加的具体。
------------------------------------分割线-----------------------------------
由于本文使用了目标检测的模型方法,因此在这里我们对目标检测做一个简单的介绍:
目标检测是计算机视觉三大主要任务之一:分类(Classification),检测(Detection),分割(Segmentation)

目标检测的难点就是 定位“框”的 确定。(位置信息本来是一些坐标信息,是一个回归问题,但是回归难收敛,计算量大,因此
将 定位“框”的确定转变为一个分类问题:如下图,对黑色框框 打分。分数越高越好。




但是 框 要取多大才合适?
太小,物体识别不完整;太大,识别结果多了很多其它信息。
那怎么办?那就各种大小的框都取来计算吧。如下图:为了定位熊的位置,取了很多的 候选框框,

传统算法的目标检测的代表有Haar特征+Adaboost算法,Hog特征+Svm算法,DPM算法(基本淘汰了)
现在基于深度学习的检测典型代表有:RCNN系列,YOLO系列和SSD系列。
本文用到的是RCNN系的经典版本 Faster R-CNN,具体怎么实现的以后在做文章讲解目标检测的模型。
--------------------------------------------------------------------------------------
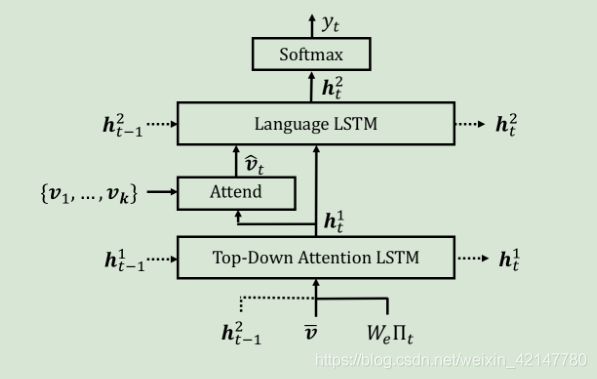
图像描述的总体模型如上图:
目标检测模型已经获得了视觉特征 k个大小一样的 v (其实与之前用CNN直接获得的k个特征向量v类似,只不过这里用了目标检测,得到的向量更加有针对性。)
top-down的注意力机制,(还是原来的配方,还是熟悉的味道)注意力权重由下公式获得,:
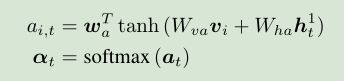
上下文向量由:
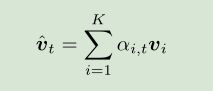
语言模型生成的预测也完全和之前一样,因此不再赘述:

注意力结果可视化:

上面是之前的注意力方法,每一个语义概念(单词),注意到的区域,与目标检测注意到的区域。
目标检测注意到的区域更加完整。
参考文献:
[1] Knowing when to look: Adaptive attention via a visual sentinel for image captioning
[2] Show, attend and tell: Neural image caption generation with visual attention
[3] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks