In the last article, the goal that we set to ourselves was to optimize the Deep Q-Learning with prioritized experience replay, in other words, provide the algorithm with a bit of help judging what is important and should be remembered and what is not. Most globally, under current technological achievements, algorithms tend to perform better when helped by human intervention. Take the example of image recognition, and let’s say you want to classify apples and bananas. Your algorithm would definitely be more accurate with the prior knowledge that bananas are yellow than if it has to learn by itself. This could also be translated by over engineering a set of hyper-parameters which would only optimize a very specific task. As for reinforcement learning, a way to prove algorithms can be generalized is to test it with multiple environments to solve. This is exactly why OpenAI environments have been made, allowing researchers to test out their algorithms by providing a simple interface that enables us to transition between environments very easily.
在上一篇文章中 ,我们设定的目标是通过优先级体验重放来优化Deep Q学习,换句话说,为该算法提供了一些帮助,以帮助您判断哪些是重要的,应该记住的,哪些不是必须的。 在全球范围内,根据当前的技术成就,算法在人工干预的帮助下往往会表现得更好。 以图像识别为例,假设您要对苹果和香蕉进行分类。 如果先验知识香蕉是黄色的,那么您的算法肯定比必须自己学习的算法更为准确。 这也可以通过对一组超参数进行过度工程来翻译,这些超参数只会优化非常具体的任务。 对于强化学习,证明算法可以推广的一种方法是在多种环境下进行测试以解决问题。 这正是制作OpenAI环境的原因,它允许研究人员通过提供一个简单的界面来测试他们的算法,该界面使我们能够非常轻松地在环境之间进行转换。
Now about prioritized experience replay, the publication showed that it could generalize well through most of the environments, yet this little human intervention help did not benefit in our case. After all, maybe this environment does need more randomness to be able to be solved. In the case of Deep Q-Learning, the randomness is created by using an epsilon greedy policy, which is “How about we don’t take the most optimized action from time to time and see what happens”. This is also called exploration. But this is actually a very pale random behavior since based on a stochastic (probabilistic) policy. Uh. In that case, how about making it totally random?
现在关于优先体验回放,该出版物表明它可以在大多数环境中很好地推广,但是这种少量的人工干预对我们的案例没有帮助。 毕竟,也许这个环境确实需要更多的随机性才能解决。 在深度Q学习中,随机性是通过使用epsilon贪婪策略创建的,该策略是“如何不时不采取最优化的行动,看看会发生什么”。 这也称为探索。 但这实际上是一种非常苍白的随机行为,因为它是基于随机(概率)策略的。 嗯 在这种情况下,如何使其完全随机?

Reinforcement learning randomness cooking recipe:
强化学习随机性烹饪食谱:
- Step 1: Take a neural network with a set of weights, which we use to transform an input state into a corresponding action. By taking successive actions guided by this neural network, we collect and add up each successive rewards until the experience is complete. 步骤1:采用具有一组权重的神经网络,我们将其用于将输入状态转换为相应的动作。 通过在该神经网络的指导下采取连续的动作,我们收集并累加每个连续的奖励,直到体验完成为止。
- Step 2: Now add the randomness: from this set of weights, generate another set of weights by adding random noise into the original weights parameters, which is, modify them a bit using a sampling distribution, for example a Gaussian distribution. Sample a new experience and collect the total reward. 步骤2:现在添加随机性:从这组权重中,通过将随机噪声添加到原始权重参数中来生成另一组权重,也就是使用采样分布(例如高斯分布)对其进行一些修改。 尝试新的体验并收集总奖励。
- Step 3: Repeat the random sampling of weight parameters until you achieve the desired score. 步骤3:重复权重参数的随机抽样,直到获得所需分数。
This is the most random thing you could do. Pull out a random neural network with random weights and see if that works, if not try again. Well the truth behind that is, this is very unlikely to work. (Or at least work in a reasonable amount of time). Yet, some very promising papers which have been published in recent years and provide very competitive results in tasks such as making humanoids robots learn how to walk are not so far from applying this very basic cooking recipe.
这是您可以做的最随机的事情。 拉出具有随机权重的随机神经网络,看看是否可行,如果不重试。 事实真相是,这不太可能起作用。 (或至少在合理的时间内工作)。 然而,近年来发表的一些非常有前途的论文在诸如使类人机器人学习如何走路等任务中提供了非常有竞争力的结果,并没有应用这种非常基本的烹饪方法。
Let’s get to it. Now imagine that instead of sampling around the same initial set of weights, at each sampling iteration you compare your reward with the previous set of weight’s rewards. If the reward is better, it means your neural network has a better idea of what is the optimal policy. So you can now start from there to sample another set of weights. This process is called hill climbing.
让我们开始吧。 现在想像一下,不是在相同的初始权重集合周围进行采样,而是在每次采样迭代时,将您的奖励与以前的权重奖励进行比较。 如果奖励更高,则意味着您的神经网络对什么是最佳策略有了更好的了解。 因此,您现在可以从那里开始采样另一组权重。 此过程称为爬山。
The analogy is pretty straightforward, you are trying to optimize your total reward (which lies at the summit of the hill), and you are taking successive steps. If your step brings your closer to the top, then you very confidently start from there for the next step. Otherwise, you come back to your previous step and try another direction. It actually looks very much like gradient ascent, optimizing a function by “climbing” a function you are trying to optimize. The difference lies in the neural network update. In hill climbing, you do not back propagate to update the weights, but only use random sampling.
这个比喻非常简单,您正在尝试优化总奖励(位于山顶),并且正在采取后续步骤。 如果您的步骤将您拉近了顶端,那么您很有信心地从那里开始下一步。 否则,您将返回上一步并尝试另一个方向。 实际上,它看起来非常像渐变上升,是通过“爬升”要尝试优化的功能来优化功能。 区别在于神经网络更新。 在爬坡中,您不会向后传播以更新权重,而仅使用随机采样。
Hill climbing actually belongs to a group of algorithms called black box optimization algorithms.
爬山实际上属于称为黑盒优化算法的一组算法。
We don’t know what exactly is the function we are trying to optimize, we can only feed it input and observe a result. Based on the output we are able to modify our input to try reaching the optimum result value. Actually eh, that sounds very familiar! Indeed, reinforcement learning algorithms also rely on a black box since they are based on an environment which provide the agent rewards (output) for each step taken (input). For example when you are trying to teach a humanoid robot how to walk, you have absolutely no prior knowledge of the kinematics, dynamics of the model you are trying to action, not even an idea of what gravity means! This is quite a black box, isn’t it? As seen below, what we are trying to optimize is our own approximation function with respect to the environment.
我们不知道我们要优化的功能到底是什么,我们只能将其输入并观察结果。 基于输出,我们能够修改输入以尝试达到最佳结果值。 嗯,听起来很熟悉! 确实,强化学习算法还依赖于黑匣子,因为它们基于为每个采取的步骤(输入)提供代理人奖励(输出)的环境。 例如,当您尝试教人形机器人如何行走时,您完全不了解要进行动作的模型的运动学,动力学,甚至不知道重力的含义! 这是一个黑匣子,不是吗? 如下所示,我们正在尝试优化的是针对环境的近似函数。
In the case of the deep Q-network, we have an idea of the function we are trying to optimize as we are performing back-propagation, so in some sense only the environment is considered as a black box. Where as for hill climbing, we are blindly modifying a set of weights without any knowledge about how these weights are used, which can be considered as a black box.
在深度Q网络的情况下,我们对正在执行反向传播时要尝试优化的功能有了一个想法,因此在某种意义上,仅将环境视为黑盒。 至于爬山的地方,我们在不知道如何使用这些权重的情况下盲目修改了一组权重,这可以看作是黑匣子。
Now, let’s climb some hill and see how would that be implemented. We start with another environment called Cart Pole, which is basically an inverted pendulum. This is usually a very good environment to test out algorithms and ideas as it is rather easy to solve and have no particular local minima. Cart pole is also popular due to the fact that it was also used for classic control theory (which provides with an analytical solution).
现在,让我们爬上一座山,看看如何实现。 我们从另一个称为Cart Pole的环境开始,它基本上是一个倒立的摆。 通常,这是测试算法和思想的一个很好的环境,因为它很容易解决并且没有特定的局部最小值。 推车杆也很受欢迎,因为它也被用于经典的控制理论(提供了一种分析解决方案)。
Let’s first watch what an inverted pendulum looks like in real life, here balanced by an impressive robot from Naver Labs:
首先,让我们看一下现实生活中倒立摆的样子,这里有一个来自Naver Labs的令人印象深刻的机器人:
演示地址
Now let’s try to balance the cart-pole from our gym environment. In this implementation we assume that an agent is provided (code on github) which can evaluate the reward for a full episode.
现在,让我们尝试平衡健身房环境中的障碍。 在此实现中,我们假设提供了一个代理(可在github上编码),该代理可以评估完整剧集的奖励。
for i_iteration in range(1, n_iterations+1):
weights_pop = [current_weights + (std*np.random.randn(agent.get_weights_dim()))
for i in range(population)]
rewards = np.array([agent.evaluate(weights, gamma, max_t) for weights in weights_pop])
elite_idxs = rewards.argsort()[-n_elite:]
weights_pop = [weights_pop[i] for i in elite_idxs]
rewards = [rewards[i] for i in elite_idxs]
current_weights = np.average(weights_pop, axis=0, weights=rewards)
reward = agent.evaluate(current_weights, gamma=1.0)Quite simple isn’t it? We actually went a bit fancy here by adding a small improvement, instead of using all the rewards to compute the new weights, we only use a fraction of them called the “elite” weights, the ones who provided the best rewards. We could also be more greedy and only take the weights with the highest reward, but that would be less robust and not handle well local minima. Computing the new weights with all the results on the other hand is more robust but slower as well. Using a fraction of the results represents some kind of balance between robustness and fast convergence.
是不是很简单? 实际上,我们通过添加一些小的改进在这里有点花哨,而不是使用所有奖励来计算新的权重,而是仅使用其中的一小部分称为“精英”权重,即提供最佳奖励的权重。 我们也可以更贪婪,只拿最高奖励的权重,但是那样就不那么健壮,不能很好地处理局部最小值。 另一方面,计算具有所有结果的新权重更为可靠,但速度也较慢。 使用一部分结果表示鲁棒性和快速收敛之间的某种平衡。
The algorithm can solve the cart pole environment in 104 iterations with about 470s of processing time. Let’s enjoy watching the trained agent perform his task. Definitely not as good looking as a humanoid robotic arm balancing a weight, but that’s already something!
该算法可以在104次迭代中解决小车杆环境,处理时间约为470s。 让我们享受观看训练有素的特工执行任务的乐趣。 绝对不如平衡重的人形机器人手臂好看,但是已经足够了!

Now hill climbing is one possible black-box algorithm implementation. In this paper, the OpenAI team (the company which made OpenAI gym as well) came out with another version which they said could solve complex RL problems such as the Mujoco motion tasks or the Atari games collection. They also claim they can solve these tasks much faster than the most efficient RL algorithms, by at least a factor 10. Let’s see what is the algorithm behind such a success:
现在,爬山是一种可能的黑盒算法实现。 在本文中, OpenAI团队(也是制造OpenAI体育馆的公司)提出了另一个版本,他们说该版本可以解决复杂的RL问题,例如Mujoco运动任务或Atari游戏集。 他们还声称,与最高效的RL算法相比,它们可以解决这些任务的速度至少快10倍。让我们看看成功的背后是什么算法:

Put apart the mathematical notations, what is here is very similar to the hill-climbing algorithm. First generate sets of weights by sampling randomly with a Gaussian distribution, evaluate the rewards for each set of weights and update the new weights using all the results. The main difference lies in the update, while hill climbing just averages the best weights, Evolution Strategies will use an update rate to move slowly to the best direction. As all RL algorithms this is indeed meant to avoid falling straight away into local minima and adds robustness. Apart from that, this is very much like hill climbing. And that is able to perform better than the most complex RL algorithms? Uh. The keyword is actually in the title of the snapshot: parallelization.
放开数学符号,这里的内容与爬山算法非常相似。 首先通过使用高斯分布随机采样来生成权重集,评估每组权重的奖励并使用所有结果更新新权重。 主要区别在于更新,而爬山只是平均最佳权重,而Evolution Strategies将使用更新率缓慢地朝最佳方向移动。 与所有RL算法一样,这实际上是要避免立即陷入局部最小值并增加鲁棒性。 除此之外,这非常像爬山。 那能比最复杂的RL算法表现更好吗? 嗯 关键字实际上在快照的标题中: parallelization 。
Parallelization is separating the processing tasks and executing them at the same time. Let’s say here, when you want to evaluate the rewards for each set of weights you can just evaluate all of them at the same time and then gather the results when they are all done. If using only one computer of course this would require it to be incredibly powerful to be able to do that, but the trick here is that the computation is not limited to one machine only. Parallelization can be done by sharing the computing tasks with other computers. For instance, the OpenAI team stated that to teach a humanoid robot to walk they used 1,440 CPUs across 80 machines.
并行化是将处理任务分离并同时执行。 在这里说,当您要评估每组权重的奖励时,您可以同时评估所有权重,然后在完成所有评估后收集结果。 如果当然只使用一台计算机,这将要求它具有强大的功能才能做到这一点,但是这里的窍门是计算不仅限于一台计算机。 并行化可以通过与其他计算机共享计算任务来完成。 例如,OpenAI团队表示,要教人形机器人走路,他们在80台机器上使用了1,440个CPU。
Making tasks parallelized for solving RL problems is nowadays a must if you want to achieve decent results. For example, the relatively famous A3C algorithm’s target is orientated towards taking advantage of parallel computation being part of what the authors call Asynchronous methods for Deep RL. The difference with Evolution Strategies (ES) is that ES is fully made to take advantage of parallelization, and even though it’s a much simpler piece of code, stacking more and more computers will lead to better results.
现在,如果要获得不错的结果,则必须并行解决RL问题。 例如,相对著名的A3C算法的目标是利用并行计算的优势,而并行计算是作者称为Deep RL的异步方法的一部分。 与Evolution Strategies(ES)的不同之处在于,充分利用ES来充分利用并行化,即使它是一段简单得多的代码,堆叠越来越多的计算机也将带来更好的结果。
Even so I (and probably you) don’t have 80 computers at hand, it could still be interesting to try to run this algorithm with asynchronous computation to get a better hold on how this could actually work and see if we can outperform the hill climbing performance.
即使我(可能还有您)手头上没有80台计算机,尝试通过异步计算运行此算法仍然很有趣,以便更好地掌握其实际工作方式,看看我们是否能胜过这座山攀爬性能。
To try parallelizing the evolution strategy algorithm, we need to dig into parallel computation in Python and the different ways of performing multi-threading. Fortunately, we can rely on some very good article which details exactly what we are looking for, presently a guidance on which library is most suited for us with some snippets of code teaching us how to use it. (Actually it was supposed to be part of this article but shhhh).
要尝试并行化演化策略算法,我们需要深入研究Python中的并行计算以及执行多线程的不同方法。 幸运的是,我们可以依靠一篇非常好的文章,其中详细介绍了我们所要查找的内容,目前,通过一些代码段教我们如何使用它,从而提供了最适合我们的库的指南。 (实际上,它应该是本文的一部分,但嘘)。
> > > > > Insert analysis of multi-threading in Python here << < < <
>>>>>>在此处在Python中插入多线程分析 << << <<
Using the newly acquired knowledge, we can try to parallelize the evolution strategies algorithm. The base layer of our implementation is the same as previously presented , it relies upon an agent who can evaluate the total reward for a provided set of weights. The agent simply performs a forward pass on the neural networks built with the specified weights to find out the action to take at every step, and sums up the rewards provided by the gym environment.
利用新获得的知识,我们可以尝试并行化进化策略算法。 我们实现的基础层与前面介绍的相同,它依赖于一个代理,该代理可以评估一组提供的权重的总奖励。 该代理简单地对使用指定权重构建的神经网络执行前向遍历,以找出每一步要采取的动作,并汇总健身房环境提供的奖励。
We now want to leverage our threading knowledge by choosing the correct library for our case. We want to optimize the convergence time of the evolution strategy by parallelizing heavy computation. On top of that, we wish in the future to be able to use the cores of multiple separate computers. The choice is then obvious, we want to go with the multi-processing library.
现在,我们希望通过为案例选择正确的库来利用我们的线程知识。 我们希望通过并行化大量计算来优化演化策略的收敛时间。 最重要的是,我们希望将来能够使用多台独立计算机的核心。 选择就显而易见了,我们想使用多处理库。
It was seen that using the multi-processing, some data types could not be successfully serialized, which is the case for the agent, probably due to the presence of pytorch data types. In order to work around this issue, the agents are defined as global variables so that they can still be accessible from the threads, which is not a good design, and which cannot be used in the case of computation shared between multiple computers. But as for testing, that will do for now as a primal way to measure the parallel computation efficiency. The base of the algorithm is as follow: at each iteration launch a thread for each parallel agent that you want to use. Then in each thread sample a set of weights and call the evaluate function. Collect all the rewards generated by each thread and update the weights. Note that the update requires the rewards as well as the sampled weights but the thread is only returning the reward. This is using the seed trick: np.random is actually not that random, if you call np.random.randn multiple times and then reset the seed and reiterate, it will provide the exact same results. Taking advantage of this, instead of returning the set of weights (Which could be huge for complex neural networks), we can only return the seed and then recreate the weights when needed. The gain of time not serializing/de serializing the weights can be consequent for some applications. Here is how this implementation would look like:
可以看出,使用多重处理无法成功序列化某些数据类型(代理程序就是这种情况),可能是由于存在pytorch数据类型。 为了解决此问题,将代理定义为全局变量,以便仍然可以从线程访问它们,这不是一个好的设计,并且在多台计算机之间共享计算的情况下不能使用它们。 但是对于测试而言,这现在将是衡量并行计算效率的主要方式。 该算法的基础如下:在每次迭代时,为要使用的每个并行代理启动一个线程。 然后在每个线程中采样一组权重并调用评估函数。 收集每个线程生成的所有奖励并更新权重。 请注意,更新需要奖励以及采样的权重,但是线程仅返回奖励。 这是使用种子技巧的:np.random实际上不是那么随机,如果多次调用np.random.randn,然后重置种子并重申,它将提供完全相同的结果。 利用此优势,我们无需返回权重集(对于复杂的神经网络而言这可能是巨大的),我们只能返回种子,然后在需要时重新创建权重。 对于某些应用,可能会导致没有对权重进行序列化/反序列化的时间增加。 这是此实现的样子:
#Number of agents working in parallel
num_agents = 50
agents = []
for i in range(num_agents):
env = gym.make('CartPole-v0')
env.seed(i)
agent = AgentTest(env, state_size=4, action_size=2, seed=i)
agents.append(agent)
def sample_reward(current_weight, index, gamma, max_t, std):
rng = np.random.RandomState(index)
weights = current_weight + (std*rng.randn(agents[index].get_weights_dim()))
reward = agents[index].evaluate(weights, gamma, max_t)
return {index : reward}
def update_weights(weights, indices, alpha, std, rewards):
scaled_rewards = np.zeros(len(rewards))
reconstructed_weights = np.zeros((len(rewards), agents[0].get_weights_dim()))
for i in indices:
rng = np.random.RandomState(i)
scaled_rewards[i] = rewards[i]
reconstructed_weights[i] = weights + std*rng.randn(agents[i].get_weights_dim())
scaled_rewards = (scaled_rewards - np.mean(scaled_rewards)) / (np.std(scaled_rewards) + 0.1)
n = len(rewards)
deltas = alpha / (n * std) * np.dot(reconstructed_weights.T, scaled_rewards)
return weights + deltas
def evolution(n_iterations=1000, max_t=2000, alpha = 0.01, gamma=1.0, std=0.1):
scores_deque = deque(maxlen=100)
scores = []
current_weights = []
rewards = {}
start_time = time.time()
current_weights = std*np.random.randn(agents[0].get_weights_dim())
indices = [i for i in range(num_agents)]
for i_iteration in range(1, n_iterations+1):
rewards.clear()
def callback(pair):
rewards.update(pair)
pool = mp.Pool(num_agents)
for i in range(num_agents):
pool.apply_async(sample_reward, args = (current_weights, i, gamma, max_t, std,), callback = callback)
pool.close()
pool.join()
current_weights = update_weights(current_weights, indices, alpha, std, rewards)Running this code has a problem though. The multi-processing apply_async gets blocked at the start of the second iteration. Seemingly some internal lock proper to multiprocessing is blocking the computation. Since the first iteration was successful, we can guess some remnants of that first iteration is blocking the beginning of the next one. It could be that when going out of scope the objects that the mp.Pool() handles could not be destroyed properly. One possible explanation would be that, multi-processing creates threads with the “fork” method internally which copies the thread environment instead of “spawn” re-evaluating” all the variables. It is possible that not all the data types (and underlying ones) have a well defined copy constructor which could lead to such a deadlock.How about using the “spawn” method then? Since multi-processing re-evaluates all the variables, the gym environment as well as the agent itself do suffer the same treatment, which is very time consuming (at least much more than calling the sample_reward function itself). Even though this approach would still work, it would definitely not allow us to reach the target that is fixed, improve the computation efficiency of the evolution strategy algorithm.
但是运行此代码有一个问题。 在第二次迭代开始时,多处理apply_async被阻塞。 似乎某些适合多处理的内部锁正在阻止计算。 由于第一次迭代是成功的,因此我们可以猜测该第一次迭代的一些残障会阻止下一次迭代的开始。 可能是当超出范围时mp.Pool()处理的对象无法正确销毁。 一种可能的解释是,多处理在内部使用“ fork”方法创建线程,该方法复制线程环境,而不是“ spawn”重新评估所有变量。 可能不是所有的数据类型(以及基础数据类型)都具有定义良好的副本构造函数,这可能导致这种僵局。那么,如何使用“ spawn”方法呢? 由于多重处理会重新评估所有变量,因此健身房环境以及代理本身确实受到相同的处理,这非常耗时(至少比调用sample_reward函数本身要多得多)。 即使这种方法仍然有效,也绝对不允许我们达到固定的目标,无法提高进化策略算法的计算效率。
So now what? Multi-processing does not seem like a viable alternative, the only other solution is to use the Threadpool library, which is limited by the Global Interpreter Lock (GIL). We can still verify the performance level using that library to see if we have any gain compared to a basic sequential approach. In both cases we use 50 agents that are able to generate the total reward for a randomly sampled set of weights:
那么现在怎么办? 多处理似乎不是一个可行的选择,唯一的解决方案是使用Threadpool库,该库受全局解释器锁(GIL)的限制。 我们仍然可以使用该库来验证性能水平,以查看与基本顺序方法相比是否有任何收益。 在这两种情况下,我们都使用50个代理商,它们能够为一组随机抽样的权重生成总奖励:

The algorithm runs until the average reward hits 195. In both cases, the behavior looks similar and the environment is solved with an equivalent amount of episodes. Until here everything looks fine. The algorithm is the same, the only difference being the parallelization of the computation. However the computation time is different, actually longer in the case when using the threadpool executor library. This is echoing the results found when bench-marking the different threading approaches. We only confirmed what was expected.
该算法一直运行到平均奖励达到195为止。在两种情况下,行为看起来都相似,并且环境以等量的情节解决。 到这里为止一切都很好。 算法是相同的,唯一的区别是计算的并行化。 但是计算时间有所不同,实际上在使用线程池执行程序库的情况下会更长。 这与对不同的线程方法进行基准测试时发现的结果相呼应。 我们只确认了预期的结果。
We now found ourselves in a deadlock, our preferred threading library is not working as expected, other approaches are actually slower than the sequential approach. The way we do threading needs to be different. If only we could parallelize the computation directly inside the gym environment, things would be much easier…
现在,我们陷入了僵局,我们首选的线程库无法按预期工作,其他方法实际上比顺序方法慢。 我们执行线程的方式需要不同。 如果我们可以直接在体育馆环境中并行化计算,那么事情会容易得多……
Guess what? This interface does.. kind of exists. There is an interface called VecEnv, which is literally an array of openai gym environments. Actually it sounds quite similar to the approach we just took earlier. Except that this VecEnv acts as a wrapper of the traditional gym environment and allows you to perform a parallel computation of the “step” operation. In the following example of the implementation of the evaluate function, the “step” function now accepts and array of actions, and returns an array of rewards and new states:
你猜怎么了? 该接口确实存在。 有一个名为VecEnv的接口,实际上是openai体育馆环境的数组。 实际上,这听起来与我们之前采用的方法非常相似。 除了此VecEnv可以用作传统健身房环境的包装外,它还允许您对“步”操作进行并行计算。 在下面的评估函数实现示例中,“步进”函数现在接受一系列动作,并返回一系列奖励和新状态:
def evaluate(self, weights, num_agents, gamma=1.0, max_t=5000):
episode_returns = {}
terminated = []
for i in range(num_agents):
terminated.append(False)
self.weightsVec[i].set_weights(weights[i])
episode_returns.update({i: 0})
states = self.env.reset()
for t in range(max_t):
states = torch.from_numpy(states).float().to(device)
actions = self.forward(states)
self.env.step_async(actions)
states, rewards, dones, infos = self.env.step_wait(timeout=1.0)
for i in range(len(rewards)):
if(terminated[i] == True):
continue
previous_reward = episode_returns[i]
new_reward = rewards[i]
episode_returns.update({i: previous_reward + new_reward * math.pow(gamma, t)})
if dones[i] == True:
terminated[i] = True
if False not in terminated:
break
return episode_returnsWhile before we just parallelize the entire process of accumulating the rewards for an entire episode, we here call multiple thread at each “step”. The benefit is that we do call a thread after having already performed the neural network forward pass. Which means that the problems encountered in the previous section related to pytorch data types and multi-processing should be avoided. Let’s check the performance results:
在我们并行化累积整个情节的奖励的整个过程之前,我们在这里在每个“步骤”处调用多个线程。 好处是我们已经执行了神经网络前向传递后才调用线程。 这意味着应避免在上一节中遇到的与pytorch数据类型和多处理有关的问题。 让我们检查一下性能结果:

While we were expecting a massive improvement in computation time, the opposite actually happened. Even though the algorithm converged using about 500 iterations compared with 400 for the previous results, it took about three more times to compute. Now let’s try take apart the “step” function and measure the performance separately from the rest of the algorithm.
当我们期望计算时间会大大改善时,实际上却发生了相反的情况。 尽管该算法使用约500次迭代进行了收敛,而先前的结果为400次,但计算仍需花费大约三倍的时间。 现在,让我们尝试分解“步进”功能,并与算法的其余部分分开衡量性能。
if __name__ == '__main__':
#Number of agents working in parallel
num_agents = 100
env_fns = [make_env('CartPole-v0', num_agents) for _ in range(num_agents)]
env = AsyncVectorEnv(env_fns)
agent = Agent(env, state_size=4, action_size=2, num_agents=num_agents)
env_test = gym.make('CartPole-v0')
agent_test = AgentTest(env_test, state_size=4, action_size=2)
one_set_of_weights = 0.1*np.random.randn(agent.get_weights_dim())
all_sets_of_weights = []
for i in range(num_agents):
all_sets_of_weights.append(one_set_of_weights)
start_time = time.time()
for i in range(100):
rewards = agent.evaluate(all_sets_of_weights, num_agents)
print("Time needed for VecEnv approach: %f", time.time() - start_time)
start_time = time.time()
for i in range(100):
for i in range(num_agents):
rewards = agent_test.evaluate(one_set_of_weights)
print("Time needed for sequential approach: %f", time.time() - start_time)We create two agents, one implementing the usual “step” function, taking one action as an argument and providing back the new state and obtained reward, while the other one use the VecEnv (vector of environments) and implements a “step” function taking an array of actions as argument and outputting an array of states and rewards. We repeat the process of calling the “step” a fixed number of times and compare the results:
我们创建了两个代理,一个实现了通常的“步骤”功能,一个动作作为参数并提供了新的状态并获得了奖励,而另一个则使用了VecEnv(环境的向量)并实现了一个“步骤”功能,一系列动作作为参数,并输出一系列状态和奖励。 我们重复调用“步骤”一定次数的过程,并比较结果:
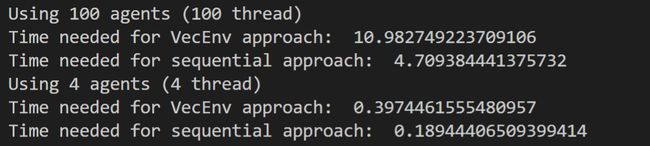
We know that VecEnv threads by implementing multi-processing, which is the correct approach and it is supposed to provide a significant computation improvement. However, we observe that even for the most advantageous case where the number of threads equals the number of cores of the PC (4 in this case), the performance is still behind the simple sequential case.
我们知道,VecEnv通过实现多重处理来实现线程化,这是正确的方法,并且应该提供显着的计算改进。 但是,我们观察到,即使对于线程数等于PC内核数(在这种情况下为4)的最有利的情况,性能仍然落后于简单的顺序情况。
One reason for this lack of performance could be that the environment is too simple to solve: the “step” function takes only an infinitesimal amount of time to return, while multiprocessing does need to serialize and de-serialize (which we don’t know the amount as it is hidden in the VecEnv implementation). It is likely that in more complex environments, as the humanoid robot learning to walk, the “step” function would require much more computation power and thus take full advantage of the threading implementation.
缺乏性能的一个原因可能是环境解决起来太简单:“ step”函数仅需要极短的时间才能返回,而多处理程序确实需要序列化和反序列化(我们不知道) VecEnv实现中隐藏的金额)。 在更复杂的环境中,随着人形机器人学习走路,“步进”功能可能需要更多的计算能力,从而充分利用线程实现的优势。
Conclusion:
结论:
- While we were initially planning to improve our lunar lander, we opted to solve the inverted pendulum problem first as an easy way to benchmark the implementation efficiency. 当我们最初计划改进月球着陆器时,我们选择首先解决倒立摆问题,这是一种基准化实施效率的简便方法。
- We could observe that a naive threading implementation separating the full evaluation of an experience reward into different thread does not work due to Pytorch. 我们可以观察到,由于Pytorch,天真线程实现无法将经验奖励的完整评估分为不同的线程。
- We used a ThreadPool executor instead and proved that this approach was still limited by the GIL (Global Interpreter Lock). 我们改用了ThreadPool执行器,并证明了该方法仍然受到GIL(全局解释器锁定)的限制。
- Finally, we tried the VecEnv wrapper of the gym environment providing an interface to execute the “step” using multiple threads. However, this approach did not appear to be successful, potentially due to our environment being too simple to take advantage of the multi-threading approach. 最后,我们尝试了健身房环境的VecEnv包装器,该包装器提供了使用多个线程执行“步骤”的接口。 但是,这种方法似乎并不成功,可能是由于我们的环境太简单而无法利用多线程方法。
To be done:
要做的事:
- Try the algorithm with a more complex environment (e.g the Mujoco environments). 在更复杂的环境(例如Mujoco环境)中尝试算法。
Github repo: https://github.com/Guillaume-Cr/evolution_strategies
Github仓库: https : //github.com/Guillaume-Cr/evolution_strategies
翻译自: https://towardsdatascience.com/evolution-strategies-for-reinforcement-learning-d46a14dfceee