深度强化学习Soft-Actor Critic算法高性能Pytorch代码(改写自spinningup,低环境依赖,低阅读障碍)
写在前面
- DRL各种算法在github上各处都是,例如莫凡的DRL代码、ElegantDRL(易读性NO.1)
- 很多代码不是原算法的最佳实现,在具体实现细节上也存在差异,不建议直接用在科研上。
- 这篇博客的代码改写自OpenAi spinningup源码DRL_OpenAI,代码性能方面不再是你需要考虑的问题了。
- 为什么改写?因为源码依赖环境过多,新手读起来很吃力,还有很多logger让人头疼。
- 这篇博客的代码将环境依赖降低到最小,并且摒弃了一些辅助功能,让代码更容易读懂。
- SAC算法很新,且性能出众。
项目分三个文件:main.py , SACModel.py , core.py
Python3.6
SACModel.py
import torch
from torch.optim import Adam
from copy import deepcopy
import itertools
import core as core
import numpy as np
class ReplayBuffer:
"""
A simple FIFO experience replay buffer for SAC agents.
"""
def __init__(self, obs_dim, act_dim, size):
self.obs_buf = np.zeros(core.combined_shape(size, obs_dim), dtype=np.float32)
self.obs2_buf = np.zeros(core.combined_shape(size, obs_dim), dtype=np.float32)
self.act_buf = np.zeros(core.combined_shape(size, act_dim), dtype=np.float32)
self.rew_buf = np.zeros(size, dtype=np.float32)
self.done_buf = np.zeros(size, dtype=np.float32)
self.ptr, self.size, self.max_size = 0, 0, size
def store(self, obs, act, rew, next_obs, done):
self.obs_buf[self.ptr] = obs
self.obs2_buf[self.ptr] = next_obs
self.act_buf[self.ptr] = act
self.rew_buf[self.ptr] = rew
self.done_buf[self.ptr] = done
self.ptr = (self.ptr+1) % self.max_size
self.size = min(self.size+1, self.max_size)
def sample_batch(self, batch_size=32):
idxs = np.random.randint(0, self.size, size=batch_size)
batch = dict(obs=self.obs_buf[idxs],
obs2=self.obs2_buf[idxs],
act=self.act_buf[idxs],
rew=self.rew_buf[idxs],
done=self.done_buf[idxs])
return {k: torch.as_tensor(v, dtype=torch.float32) for k,v in batch.items()}
class SAC:
def __init__(self, obs_dim, act_dim, act_bound, actor_critic=core.MLPActorCritic, seed=0,
replay_size=int(1e6), gamma=0.99, polyak=0.995, lr=1e-3, alpha=0.2):
self.obs_dim = obs_dim
self.act_dim = act_dim
self.act_bound = act_bound
self.gamma = gamma
self.polyak = polyak
self.alpha = alpha
torch.manual_seed(seed)
np.random.seed(seed)
self.ac = actor_critic(obs_dim, act_dim, act_limit=2.0)
self.ac_targ = deepcopy(self.ac)
# Freeze target networks with respect to optimizers (only update via polyak averaging)
for p in self.ac_targ.parameters():
p.requires_grad = False
# List of parameters for both Q-networks (save this for convenience)
self.q_params = itertools.chain(self.ac.q1.parameters(), self.ac.q2.parameters())
# Set up optimizers for policy and q-function
self.pi_optimizer = Adam(self.ac.pi.parameters(), lr=lr)
self.q_optimizer = Adam(self.q_params, lr=lr)
# Experience buffer
self.replay_buffer = ReplayBuffer(obs_dim=obs_dim, act_dim=act_dim, size=replay_size)
# Set up function for computing SAC Q-losses
def compute_loss_q(self, data):
o, a, r, o2, d = data['obs'], data['act'], data['rew'], data['obs2'], data['done']
q1 = self.ac.q1(o,a)
q2 = self.ac.q2(o,a)
# Bellman backup for Q functions
with torch.no_grad():
# Target actions come from *current* policy
a2, logp_a2 = self.ac.pi(o2)
# Target Q-values
q1_pi_targ = self.ac_targ.q1(o2, a2)
q2_pi_targ = self.ac_targ.q2(o2, a2)
q_pi_targ = torch.min(q1_pi_targ, q2_pi_targ)
backup = r + self.gamma * (1 - d) * (q_pi_targ - self.alpha * logp_a2)
# MSE loss against Bellman backup
loss_q1 = ((q1 - backup)**2).mean()
loss_q2 = ((q2 - backup)**2).mean()
loss_q = loss_q1 + loss_q2
# Useful info for logging
q_info = dict(Q1Vals=q1.detach().numpy(),
Q2Vals=q2.detach().numpy())
return loss_q, q_info
# Set up function for computing SAC pi loss
def compute_loss_pi(self, data):
o = data['obs']
pi, logp_pi = self.ac.pi(o)
q1_pi = self.ac.q1(o, pi)
q2_pi = self.ac.q2(o, pi)
q_pi = torch.min(q1_pi, q2_pi)
# Entropy-regularized policy loss
loss_pi = (self.alpha * logp_pi - q_pi).mean()
# Useful info for logging
pi_info = dict(LogPi=logp_pi.detach().numpy())
return loss_pi, pi_info
def update(self, data):
# First run one gradient descent step for Q1 and Q2
self.q_optimizer.zero_grad()
loss_q, q_info = self.compute_loss_q(data)
loss_q.backward()
self.q_optimizer.step()
# Freeze Q-networks so you don't waste computational effort
# computing gradients for them during the policy learning step.
for p in self.q_params:
p.requires_grad = False
# Next run one gradient descent step for pi.
self.pi_optimizer.zero_grad()
loss_pi, pi_info = self.compute_loss_pi(data)
loss_pi.backward()
self.pi_optimizer.step()
# Unfreeze Q-networks so you can optimize it at next DDPG step.
for p in self.q_params:
p.requires_grad = True
# Finally, update target networks by polyak averaging.
with torch.no_grad():
for p, p_targ in zip(self.ac.parameters(), self.ac_targ.parameters()):
# NB: We use an in-place operations "mul_", "add_" to update target
# params, as opposed to "mul" and "add", which would make new tensors.
p_targ.data.mul_(self.polyak)
p_targ.data.add_((1 - self.polyak) * p.data)
def get_action(self, o, deterministic=False):
return self.ac.act(torch.as_tensor(o, dtype=torch.float32),
deterministic)
core.py
import numpy as np
import scipy.signal
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.distributions.normal import Normal
def combined_shape(length, shape=None):
if shape is None:
return (length,)
return (length, shape) if np.isscalar(shape) else (length, *shape)
def mlp(sizes, activation, output_activation=nn.Identity):
layers = []
for j in range(len(sizes)-1):
act = activation if j < len(sizes)-2 else output_activation
layers += [nn.Linear(sizes[j], sizes[j+1]), act()]
return nn.Sequential(*layers)
def count_vars(module):
return sum([np.prod(p.shape) for p in module.parameters()])
LOG_STD_MAX = 2
LOG_STD_MIN = -20
class SquashedGaussianMLPActor(nn.Module):
def __init__(self, obs_dim, act_dim, hidden_sizes, activation, act_limit):
super().__init__()
self.net = mlp([obs_dim] + list(hidden_sizes), activation, activation)
self.mu_layer = nn.Linear(hidden_sizes[-1], act_dim)
self.log_std_layer = nn.Linear(hidden_sizes[-1], act_dim)
self.act_limit = act_limit
def forward(self, obs, deterministic=False, with_logprob=True):
net_out = self.net(obs)
mu = self.mu_layer(net_out)
log_std = self.log_std_layer(net_out)
log_std = torch.clamp(log_std, LOG_STD_MIN, LOG_STD_MAX)
std = torch.exp(log_std)
# Pre-squash distribution and sample
pi_distribution = Normal(mu, std)
if deterministic:
# Only used for evaluating policy at test time.
pi_action = mu
else:
pi_action = pi_distribution.rsample()
if with_logprob:
# Compute logprob from Gaussian, and then apply correction for Tanh squashing.
# NOTE: The correction formula is a little bit magic. To get an understanding
# of where it comes from, check out the original SAC paper (arXiv 1801.01290)
# and look in appendix C. This is a more numerically-stable equivalent to Eq 21.
# Try deriving it yourself as a (very difficult) exercise. :)
logp_pi = pi_distribution.log_prob(pi_action).sum(axis=-1)
logp_pi -= (2*(np.log(2) - pi_action - F.softplus(-2*pi_action))).sum(axis=1)
else:
logp_pi = None
pi_action = torch.tanh(pi_action)
pi_action = self.act_limit * pi_action
return pi_action, logp_pi
class MLPQFunction(nn.Module):
def __init__(self, obs_dim, act_dim, hidden_sizes, activation):
super().__init__()
self.q = mlp([obs_dim + act_dim] + list(hidden_sizes) + [1], activation)
def forward(self, obs, act):
q = self.q(torch.cat([obs, act], dim=-1))
return torch.squeeze(q, -1) # Critical to ensure q has right shape.
class MLPActorCritic(nn.Module):
def __init__(self, obs_dim, act_dim, hidden_sizes=(256,256),
activation=nn.ReLU, act_limit = 2.0):
super().__init__()
# build policy and value functions
self.pi = SquashedGaussianMLPActor(obs_dim, act_dim, hidden_sizes, activation, act_limit)
self.q1 = MLPQFunction(obs_dim, act_dim, hidden_sizes, activation)
self.q2 = MLPQFunction(obs_dim, act_dim, hidden_sizes, activation)
def act(self, obs, deterministic=False):
with torch.no_grad():
a, _ = self.pi(obs, deterministic, False)
return a.numpy()
main.py
from SACModel import *
import gym
import matplotlib.pyplot as plt
if __name__ == '__main__':
env = gym.make('CartPole-v0')
obs_dim = env.observation_space.shape[0]
act_dim = env.action_space.shape[0]
act_bound = [-env.action_space.high[0], env.action_space.high[0]]
sac = SAC(obs_dim, act_dim, act_bound)
MAX_EPISODE = 100
MAX_STEP = 500
update_every = 50
batch_size = 100
rewardList = []
for episode in range(MAX_EPISODE):
o = env.reset()
ep_reward = 0
for j in range(MAX_STEP):
if episode > 20:
env.render()
a = sac.get_action(o)
else:
a = env.action_space.sample()
o2, r, d, _ = env.step(a)
sac.replay_buffer.store(o, a, r, o2, d)
if episode >= 10 and j % update_every == 0:
for _ in range(update_every):
batch = sac.replay_buffer.sample_batch(batch_size)
sac.update(data=batch)
o = o2
ep_reward += r
if d:
break
print('Episode:', episode, 'Reward:%i' % int(ep_reward))
rewardList.append(ep_reward)
plt.figure()
plt.plot(np.arange(len(rewardList)),rewardList)
plt.show()
'CartPole-v0’倒立摆实验Reawrd Curve
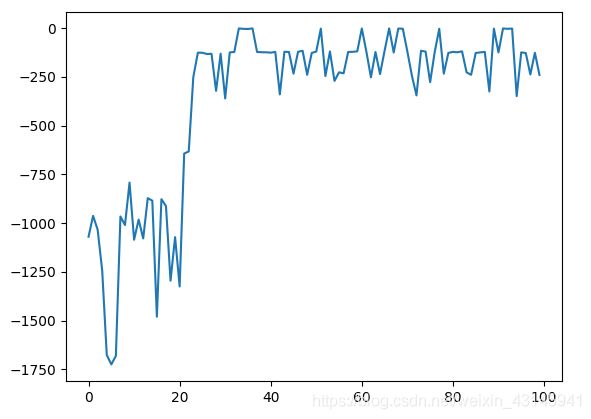
由于倒立摆这个环境比较简单,我比较了spinningup的DDPG,差距不是很明显。可以更换一些较为复杂的环境进行测试。