基于Pytorch的动手学习Bert+FC的文本分类模型
基于Pytorch的动手学习Bert+FC的文本分类模型
- 一、模型构建
-
- 1.1 模型参数
- 1.2 构建Bert+FC模型
- 二、辅助模块
-
- 2.1 数据构建函数
- 2.2 数据Batch迭代器
- 三、模型训练
-
- 3.1 模型训练函数
- 3.2 模型结果评估函数
- 四、主函数
-
- 4.1 主函数
- 4.2 完整代码
一、模型构建
1.1 模型参数
本次数据集主要是用清华数据集的10分类任务
其中models,放模型文件

THUCNews下有data文件夹
data数据类别下有class和test,train、dev数据
在models文件夹下,构建bert模型文件
导入相应的库
import torch
import torch.nn as nn
from pytorch_pretrained import BertModel,BertTokenizer #从pytorch预训练模型中导入模型和分词器
print('Torch版本',torch.__version__)
Torch版本 1.4.0
配置相应的Bert模型参数
其中self.bert_path = ‘bert_pretrain’,需要带入对应的Bert预训练的模型

bert内置模型参数
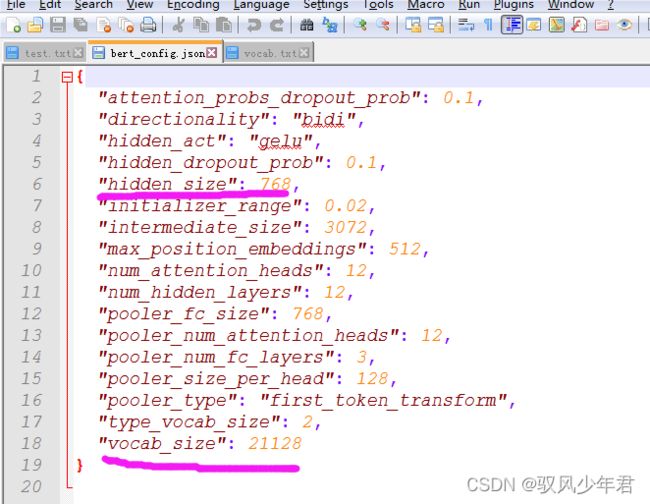
词汇表

隐藏层个数self.hidden_size = 768 要等于预训练模型的隐藏层数目
class Config(object):
"""
配置参数
"""
def __init__(self,dataset):
#模型名称
self.model_name = "Bert"
#训练集
self.train_path = dataset + '/data/train.txt'
#测试集
self.test_path = dataset + '/data/test.txt'
#校验集
self.dev_path = dataset + '/data/dev.txt'
#类别
self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]
#模型训练完成后保存路径
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
#模型设备,cpu或者gpu
self.device = torch.device('cuda'if torch.cuda.is_available() else 'cpu')
# 如果超过1000batch,效果没提升,就提前结束训练
self.require_improvement = 1000
#样本的类别数
self.num_class = len(self.class_list)
#epoch数
self.num_epochs = 3
#batch_size每一个批次是数目
self.batch_size = 128
#每句话处理长度,短填长截
self.pad_size = 32
#学习率
self.learning_rate = 1e-5
#bert预训练的模型位置
self.bert_path = 'bert_pretrain'
#bert切词器
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
#隐藏层个数
self.hidden_size = 768
1.2 构建Bert+FC模型
定义模型,继承NN、mode
从导入BertModel.from_pretrained(config.bert_path)
class Model(nn.Module):
def __init__(self,config):
#继承父类
super(Model, self).__init__()
#加载模型
self.bert = BertModel.from_pretrained(config.bert_path)
#Bert参数的是否微调,False表示不调整,True表示根据上游模型调整参数
for param in self.bert.parameters():
param.requires_grad = True #不固定参数,梯度需要变换
#最后一层,FC全连接,传入对应的隐藏层数目,类别数
self.fc = nn.Linear(config.hidden_size,config.num_class)
#前向传播
#x,包含词ids,seq_len,attention—mask
def forward(self,x):
context = x[0] #输入的句子,shape[128,32]表示128条文本,每条文本32词
mask = x[2] #对padding部分进行mask,shape[128,32],mask中的1表示实际词汇,0表示填充的0
_,pooled = self.bert(context,attention_mask=mask,output_all_encoded_layers=False)#,shape[128,768],原本每条文本32词,经过bert转换后变成768
out = self.fc(pooled) #,shape[128,10],fc训练后得到每条文本每个类别的的概率
return out
二、辅助模块
2.1 数据构建函数
读取相应的数据,将数据转换为模型可以读取的格式
from tqdm import tqdm #显示进度条
import torch
import time
from datetime import timedelta
PAD,CLS = '[PAD]','[CLS]'
#构建数据输入函数
def load_dataset(file_path,config):
"""
返回结果:4个list:ids,label,ids_len,mask
:param file_path:
:param seq_len:
:return:
"""
contents = []
with open(file_path,'r',encoding='utf-8') as f:
for line in tqdm(f):
line = line.strip() #取掉空格
if not line: #跳过空行
continue
content,lable = line.split('\t')
#对文本进行切词
token = config.tokenizer.tokenize(content)
#在文本开头加上CLS标志位
token = [CLS] + token
#文本长度
seq_len = len(token)
mask = []
#将文本转为相应的ids
token_ids = config.tokenizer.convert_tokens_to_ids(token)
#文本、数据填充
pad_size = config.pad_size
if pad_size:
if len(token) < pad_size:
# 填充,制作mask
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids = token_ids + ([0] * (pad_size - len(token)))
else:
#截断
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(lable), seq_len, mask))
return contents
#加载数据函数
def bulid_dataset(config):
"""
返回值值是 train,dev,test
4个list ids,label,ids_len,mask
:param config:
:return:
"""
train = load_dataset(config.train_path,config)
dev = load_dataset(config.dev_path,config)
test = load_dataset(config.dev_path,config)
return train,test,dev
2.2 数据Batch迭代器
get_time_dif函数主要用于获取当前时间,用户统计模型运行时间
bulid_iterator函数用户返回相应的每次迭代得到的数据
bulid_iterator中的DatasetIterator才是迭代器
DatasetIterator中的n_batches表示按照当前的batchsize可以迭代几次
self.index记录已经迭代了几次
bert的训练需要传入相应的(ids, seq_len, mask)
#构建迭代器类
class DatasetIterator(object):
def __init__(self, dataset, batch_size, device):
self.batch_size = batch_size
self.dataset = dataset
self.n_batches = len(dataset) // batch_size
self.residue = False #记录batch数量是否为整数
if len(dataset) % self.n_batches != 0: #不能刚好被完整迭代,有剩余
self.residue = True
self.index = 0
self.device = device
# 将数据转成bert模型需要的函数
def _to_tensor(self, datas):
x = torch.LongTensor([item[0] for item in datas]).to(self.device) #样本数据ids
y = torch.LongTensor([item[1] for item in datas]).to(self.device) #标签数据label
seq_len = torch.LongTensor([item[2] for item in datas]).to(self.device) #每一个序列的真实长度
mask = torch.LongTensor([item[3] for item in datas]).to(self.device)
return (x, seq_len, mask), y
#迭代
def __next__(self):
#迭代到最后一次batch
if self.residue and self.index == self.n_batches:
batches = self.dataset[self.index * self.batch_size : len(self.dataset)]
self.index += 1
batches = self._to_tensor(batches) #用该函数转成bert需要的数据类型
return batches
elif self.index > self.n_batches:
#跌代到最后一次batch后,还剩余的
self.index = 0
raise StopIteration
else:
#重头迭代,到最后一次batch的前一次。每次切一部分数据
batches = self.dataset[self.index * self.batch_size : (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
#构建迭代器函数,调用迭代器类
def bulid_iterator(dataset, config):
iter = DatasetIterator(dataset, config.batch_size, config.device) #传入数据,传入每次迭代的数量,以及设备类型
return iter
#获取时间的函数
def get_time_dif(start_time):
"""
获取已经使用的时间
:param start_time:
:return:
"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
三、模型训练
3.1 模型训练函数
模型训练,需要启动模型训练model.train()
模型训练中,有些参数不需要衰减,需要拿到所有参数,先定义出来
需要衰减的’weight_decay’:0.01’,不需要衰减的’weight_decay’:0.0’
每100个batch就输出一次
训练完过程中,需要定义一个评估函数evaluate,用于评估当前模型对验证集的识别性能,返回dev_acc, dev_loss
import numpy as np
import torch
import torch.nn as nn
import utils
import torch.nn.functional as F
from sklearn import metrics
import time
from pytorch_pretrained.optimization import BertAdam
def train(config, model, train_iter, dev_iter, test_iter):
"""
模型训练方法
:param config:
:param model:
:param train_iter:
:param dev_iter:
:param test_iter:
:return:
"""
start_time = time.time()
#启动 BatchNormalization 和 dropout
model.train()
#拿到所有mode中的参数
param_optimizer = list(model.named_parameters())
# -------------------不需要衰减的参数---------------------
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params':[p for n,p in param_optimizer if not any( nd in n for nd in no_decay)], 'weight_decay':0.01},
{'params':[p for n,p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_deacy':0.0}
]
#------------------------优化器-----------------------
optimizer = BertAdam(params = optimizer_grouped_parameters,
lr=config.learning_rate,
warmup=0.05,
t_total=len(train_iter) * config.num_epochs)
#---------------------训练----------------------------------
total_batch = 0 #记录进行多少batch
dev_best_loss = float('inf') #记录校验集合最好的loss
last_imporve = 0 #记录上次校验集loss下降的batch数
flag = False #记录是否很久没有效果提升,停止训练
model.train()
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch+1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
#------------------模型训练----------------------------
outputs = model(trains) #喂数据,获得预测结果
model.zero_grad() #torch,需要训练完成后,梯度清零
loss = F.cross_entropy(outputs, labels)#计算损失
loss.backward(retain_graph=False) #反向传播
optimizer.step() # 优化
#每100输出一次结果
if total_batch % 100 == 0: #每多少次输出在训练集和校验集上的效果
true = labels.data.cpu() #如果在gpu上,将数据换成cpu上
predit = torch.max(outputs.data, 1)[1].cpu()
#------------------训练集评估准确率----------------------------
train_acc = metrics.accuracy_score(true, predit)
#-------------------验证集准确率---------------------------------
dev_acc, dev_loss = evaluate(config, model, dev_iter) #调用结果评估函数
#将当前验证集准确率最好的模型保存下来
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
imporve = '*' #最优后面打印一个'*'
last_imporve = total_batch #记录上次最优模型所在的batch数
model.train()
else:
imporve = ''
time_dif = utils.get_time_dif(start_time)
msg = 'Iter:{0:>6}, Train Loss:{1:>5.2}, Train Acc:{2:>6.2}, Val Loss:{3:>5.2}, Val Acc:{4:>6.2%}, Time:{5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, imporve))
model.train()
total_batch = total_batch + 1 #记录batch数
#--------------------------------终止条件---------------------------
if total_batch - last_imporve > config.require_improvement: #当前批次,比上次最优已经训练了1000以上还没优化,就停止。
#在验证集合上loss超过1000batch没有下降,结束训练
print('在校验数据集合上已经很长时间没有提升了,模型自动停止训练')
flag = True
break
#终止,跳出训练
if flag:
break
#训练完成后,就用测试集测试
test(config, model, test_iter)
3.2 模型结果评估函数
evaluate函数
model.eval()表示开启评估模式,停掉梯度
#评估函数(包含测试)
def evaluate(config, model, dev_iter, test=False):
"""
:param config:
:param model:
:param dev_iter:
:return:
"""
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad(): #评估时候不需要求梯度
for texts, labels in dev_iter:#获取数据,和标签
outputs = model(texts)
#获取当前文本的loss
loss = F.cross_entropy(outputs, labels)
#获取所有文本loss
loss_total = loss_total + loss
#将label转为numpy
labels = labels.data.cpu().numpy()
#将预测结果转为numpy
predict = torch.max(outputs.data,1)[1].cpu().numpy()
#------------------获取所有文本的label和预测值
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predict)
#计算准确率
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(dev_iter), report, confusion
return acc, loss_total / len(dev_iter) #平均损失
#模型测试
def test(config, model, test_iter):
"""
模型测试
:param config:
:param model:
:param test_iter:
:return:
"""
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss ,test_report, test_confusion = evaluate(config, model, test_iter, test = True)
msg = 'Test Loss:{0:>5.2}, Test Acc:{1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score")
print(test_report)
print("Confusion Maxtrix")
print(test_confusion)
time_dif = utils.get_time_dif(start_time)
print("使用时间:",time_dif)
四、主函数
4.1 主函数
description=‘Bert’表示项目所在文件夹名称
parser.add_argument(’–model’, type=str, default=‘Bert’, help = ‘choose a model’)中default='Bert’表示调用Bert.py
import time
import torch
import numpy as np
from importlib import import_module
import argparse
import utils
import train
parser = argparse.ArgumentParser(description='Bert')
# print(parser)
parser.add_argument('--model', type=str, default='Bert', help = 'choose a model')
# print(parser)
args = parser.parse_args()
# print(args)
if __name__ == '__main__':
dataset = 'THUCNews' #数据集地址
model_name = args.model
# print(model_name)
x = import_module('models.' + model_name)
# print(x)
config = x.Config(dataset)
#--------------------设置随机种子,保证每次结果一样------------------
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(4)
torch.backends.cudnn.deterministic = True
start_time = time.time()
print('加载数据集')
train_data,dev_data,test_data = utils.bulid_dataset(config)
#构建数据迭代器,一个批次一个批次的送数据给模型
train_iter = utils.bulid_iterator(train_data[:300], config)
dev_iter = utils.bulid_iterator(dev_data[:200], config)
test_iter = utils.bulid_iterator(test_data[:200], config)
time_dif = utils.get_time_dif(start_time)
print("模型开始之前,准备数据时间:", time_dif)
# 模型训练,评估与测试
model = x.Model(config).to(config.device)
train.train(config, model, train_iter, dev_iter, test_iter)
#-------------模型评估-----------------
train.test(config, model, test_iter)
print('-------------结束运行----------------------------')
4.2 完整代码
main.py
import time
import torch
import numpy as np
from importlib import import_module
import argparse
import utils
import train
parser = argparse.ArgumentParser(description='Bert')
# print(parser)
parser.add_argument('--model', type=str, default='Bert', help = 'choose a model')
# print(parser)
args = parser.parse_args()
# print(args)
if __name__ == '__main__':
dataset = 'THUCNews' #数据集地址
model_name = args.model
# print(model_name)
x = import_module('models.' + model_name)
# print(x)
config = x.Config(dataset)
#--------------------设置随机种子,保证每次结果一样------------------
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(4)
torch.backends.cudnn.deterministic = True
start_time = time.time()
print('加载数据集')
train_data,dev_data,test_data = utils.bulid_dataset(config)
#构建数据迭代器,一个批次一个批次的送数据给模型
train_iter = utils.bulid_iterator(train_data[:300], config)
dev_iter = utils.bulid_iterator(dev_data[:200], config)
test_iter = utils.bulid_iterator(test_data[:200], config)
time_dif = utils.get_time_dif(start_time)
print("模型开始之前,准备数据时间:", time_dif)
# 模型训练,评估与测试
model = x.Model(config).to(config.device)
train.train(config, model, train_iter, dev_iter, test_iter)
#-------------模型评估-----------------
train.test(config, model, test_iter)
print('-------------结束运行----------------------------')
models文件夹下的Bert.py
import torch
import torch.nn as nn
from pytorch_pretrained import BertModel,BertTokenizer
print('Torch版本',torch.__version__)
class Config(object):
"""
配置参数
"""
def __init__(self,dataset):
self.model_name = "BruceBert"
#训练集
self.train_path = dataset + '/data/train.txt'
#测试集
self.test_path = dataset + '/data/test.txt'
#校验集
self.dev_path = dataset + '/data/dev.txt'
#类别
self.class_list = [x.strip() for x in open(dataset + '/data/class.txt').readlines()]
#模型保存路径
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt'
#模型设备,cpu或者gpu
self.device = torch.device('cuda'if torch.cuda.is_available() else 'cpu')
# 如果超过1000batch,效果没提升,就提前结束训练
self.require_improvement = 1000
#类别数
self.num_class = len(self.class_list)
#epoch数
self.num_epochs = 3
#batch_size每一个批次是数目
self.batch_size = 128
#每句话处理长度,短填长截
self.pad_size = 32
#学习率
self.learning_rate = 1e-5
#bert预训练的模型位置
self.bert_path = 'bert_pretrain'
#bert切词器
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
#隐藏层个数
self.hidden_size = 768
class Model(nn.Module):
def __init__(self,config):
#继承父类
super(Model, self).__init__()
#加载模型
self.bert = BertModel.from_pretrained(config.bert_path)
#Bert参数的是否微调
for param in self.bert.parameters():
param.requires_grad = True #不固定参数,梯度需要变换
#最后一层,FC全连接
self.fc = nn.Linear(config.hidden_size,config.num_class)
#前向传播
#x,包含词ids,seq_len,attention—mask
def forward(self,x):
context = x[0] #输入的句子,shape[128,32]
mask = x[2] #对padding部分进行mask,shape[128,32]
_,pooled = self.bert(context,attention_mask=mask,output_all_encoded_layers=False)#,shape[128,768]
out = self.fc(pooled) #,shape[128,10]
return out
train.py
import numpy as np
import torch
import torch.nn as nn
import utils
import torch.nn.functional as F
from sklearn import metrics
import time
from pytorch_pretrained.optimization import BertAdam
def train(config, model, train_iter, dev_iter, test_iter):
"""
模型训练方法
:param config:
:param model:
:param train_iter:
:param dev_iter:
:param test_iter:
:return:
"""
start_time = time.time()
#启动 BatchNormalization 和 dropout
model.train()
#拿到所有mode种的参数
param_optimizer = list(model.named_parameters())
# -------------------不需要衰减的参数---------------------
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params':[p for n,p in param_optimizer if not any( nd in n for nd in no_decay)], 'weight_decay':0.01},
{'params':[p for n,p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_deacy':0.0}
]
#------------------------优化器-----------------------
optimizer = BertAdam(params = optimizer_grouped_parameters,
lr=config.learning_rate,
warmup=0.05,
t_total=len(train_iter) * config.num_epochs)
#---------------------训练----------------------------------
total_batch = 0 #记录进行多少batch
dev_best_loss = float('inf') #记录校验集合最好的loss
last_imporve = 0 #记录上次校验集loss下降的batch数
flag = False #记录是否很久没有效果提升,停止训练
model.train()
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch+1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward(retain_graph=False)
optimizer.step()
if total_batch % 100 == 0: #每多少次输出在训练集和校验集上的效果
true = labels.data.cpu()
predit = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predit)
dev_acc, dev_loss = evaluate(config, model, dev_iter) #调用结果评估函数
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
imporve = '*'
last_imporve = total_batch
else:
imporve = ''
time_dif = utils.get_time_dif(start_time)
msg = 'Iter:{0:>6}, Train Loss:{1:>5.2}, Train Acc:{2:>6.2}, Val Loss:{3:>5.2}, Val Acc:{4:>6.2%}, Time:{5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, imporve))
model.train()
total_batch = total_batch + 1
#--------------------------------终止条件---------------------------
if total_batch - last_imporve > config.require_improvement:
#在验证集合上loss超过1000batch没有下降,结束训练
print('在校验数据集合上已经很长时间没有提升了,模型自动停止训练')
flag = True
break
#终止,跳出训练
if flag:
break
#训练完成后,就用测试集测试
test(config, model, test_iter)
#评估函数(包含测试)
def evaluate(config, model, dev_iter, test=False):
"""
:param config:
:param model:
:param dev_iter:
:return:
"""
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in dev_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total = loss_total + loss
labels = labels.data.cpu().numpy()
predict = torch.max(outputs.data,1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predict)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(dev_iter), report, confusion
return acc, loss_total / len(dev_iter)
#模型测试
def test(config, model, test_iter):
"""
模型测试
:param config:
:param model:
:param test_iter:
:return:
"""
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss ,test_report, test_confusion = evaluate(config, model, test_iter, test = True)
msg = 'Test Loss:{0:>5.2}, Test Acc:{1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score")
print(test_report)
print("Confusion Maxtrix")
print(test_confusion)
time_dif = utils.get_time_dif(start_time)
print("使用时间:",time_dif)
utils.py
from tqdm import tqdm #显示进度条
import torch
import time
from datetime import timedelta
PAD,CLS = '[PAD]','[CLS]'
#构建数据输入函数
def load_dataset(file_path,config):
"""
返回结果:4个list:ids,label,ids_len,mask
:param file_path:
:param seq_len:
:return:
"""
contents = []
with open(file_path,'r',encoding='utf-8') as f:
for line in tqdm(f):
line = line.strip() #取掉空行
if not line: #跳过空行
continue
content,lable = line.split('\t')
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
#数据填充
pad_size = config.pad_size
if pad_size:
if len(token) < pad_size:
# 填充
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids = token_ids + ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(lable), seq_len, mask))
return contents
#加载数据函数
def bulid_dataset(config):
"""
返回值值是 train,dev,test
4个list ids,label,ids_len,mask
:param config:
:return:
"""
train = load_dataset(config.train_path,config)
dev = load_dataset(config.dev_path,config)
test = load_dataset(config.dev_path,config)
return train,test,dev
#构建迭代器类
class DatasetIterator(object):
def __init__(self, dataset, batch_size, device):
self.batch_size = batch_size
self.dataset = dataset
self.n_batches = len(dataset) // batch_size
self.residue = False #记录batch数量是否为整数
if len(dataset) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
# 将数据转成bert模型需要的函数
def _to_tensor(self, datas):
x = torch.LongTensor([item[0] for item in datas]).to(self.device) #样本数据ids
y = torch.LongTensor([item[1] for item in datas]).to(self.device) #标签数据label
seq_len = torch.LongTensor([item[2] for item in datas]).to(self.device) #每一个序列的真实长度
mask = torch.LongTensor([item[3] for item in datas]).to(self.device)
return (x, seq_len, mask), y
#迭代
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.dataset[self.index * self.batch_size : len(self.dataset)]
self.index += 1
batches = self._to_tensor(batches) #用该函数转成bert需要的数据类型
return batches
elif self.index > self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.dataset[self.index * self.batch_size : (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
#构建迭代器函数,调用迭代器类
def bulid_iterator(dataset, config):
iter = DatasetIterator(dataset, config.batch_size, config.device) #传入数据,传入每次迭代的数量,以及设备类型
return iter
#获取时间的函数
def get_time_dif(start_time):
"""
获取已经使用的时间
:param start_time:
:return:
"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))
```from tqdm import tqdm #显示进度条
import torch
import time
from datetime import timedelta
PAD,CLS = '[PAD]','[CLS]'
#构建数据输入函数
def load_dataset(file_path,config):
"""
返回结果:4个list:ids,label,ids_len,mask
:param file_path:
:param seq_len:
:return:
"""
contents = []
with open(file_path,'r',encoding='utf-8') as f:
for line in tqdm(f):
line = line.strip() #取掉空行
if not line: #跳过空行
continue
content,lable = line.split('\t')
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
#数据填充
pad_size = config.pad_size
if pad_size:
if len(token) < pad_size:
# 填充
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids = token_ids + ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(lable), seq_len, mask))
return contents
#加载数据函数
def bulid_dataset(config):
"""
返回值值是 train,dev,test
4个list ids,label,ids_len,mask
:param config:
:return:
"""
train = load_dataset(config.train_path,config)
dev = load_dataset(config.dev_path,config)
test = load_dataset(config.dev_path,config)
return train,test,dev
#构建迭代器类
class DatasetIterator(object):
def __init__(self, dataset, batch_size, device):
self.batch_size = batch_size
self.dataset = dataset
self.n_batches = len(dataset) // batch_size
self.residue = False #记录batch数量是否为整数
if len(dataset) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = device
# 将数据转成bert模型需要的函数
def _to_tensor(self, datas):
x = torch.LongTensor([item[0] for item in datas]).to(self.device) #样本数据ids
y = torch.LongTensor([item[1] for item in datas]).to(self.device) #标签数据label
seq_len = torch.LongTensor([item[2] for item in datas]).to(self.device) #每一个序列的真实长度
mask = torch.LongTensor([item[3] for item in datas]).to(self.device)
return (x, seq_len, mask), y
#迭代
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.dataset[self.index * self.batch_size : len(self.dataset)]
self.index += 1
batches = self._to_tensor(batches) #用该函数转成bert需要的数据类型
return batches
elif self.index > self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.dataset[self.index * self.batch_size : (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches + 1
else:
return self.n_batches
#构建迭代器函数,调用迭代器类
def bulid_iterator(dataset, config):
iter = DatasetIterator(dataset, config.batch_size, config.device) #传入数据,传入每次迭代的数量,以及设备类型
return iter
#获取时间的函数
def get_time_dif(start_time):
"""
获取已经使用的时间
:param start_time:
:return:
"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))