卷积神经网络基础知识四(VGG)
一.简单介绍
1.1 绪论
论文下载地址:https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1409.1556
VGG是Oxford的VisualGeometryGroup的组提出的(大家应该能看出VGG名字的由来了)。该网络是在ILSVRC 2014上的相关工作,主要工作是证明了增加网络的深度能够在一定程度上影响网络最终的性能。VGG有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样。
1.2VGG优缺点
VGG优点
VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)。
几个小滤波器(3x3)卷积层的组合比一个大滤波器(5x5或7x7)卷积层好:
验证了通过不断加深网络结构可以提升性能。
VGG缺点
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3x3卷积的锅),导致更多的内存占用(140M)。其中绝大多数的参数都是来自于第一个全连接层。VGG可是有3个全连接层啊!
PS:有的文章称:发现这些全连接层即使被去除,对于性能也没有什么影响,这样就显著降低了参数数量。
1.3VGG创新点
1)数据层堆叠,通过2至3个33卷积层堆叠来形成55和77大小的感受野。其中2个33的卷积层可以形成55大小的感受野,第一参数量更少,比1个77的卷积层拥有更少的参数量,只有后者的(333)/ (7*7)=55%的参数量,拥有更多的非线性变化,3个卷积层可以进行3次非线性变化,而1个卷积层只能1次
2)训练和预测时的技巧,训练时先训练级别A的简单网络,再复用A网络的权重来初始化后面的几个复杂模型,这样训练收敛的速度更快。预测时采用Multi-Scale的方法,同时还再训练时VGGNet也使用了Multi-Scale的方法做数据增强
3)得出LRN层作用不大,越深的网络效果越好。11的卷积也是很有效的,但是没有33的好,大一些的卷积核可以学习更大的空间特征
二.基础理论部分
2.1网络结构
如下图VGG-19的网络结构。
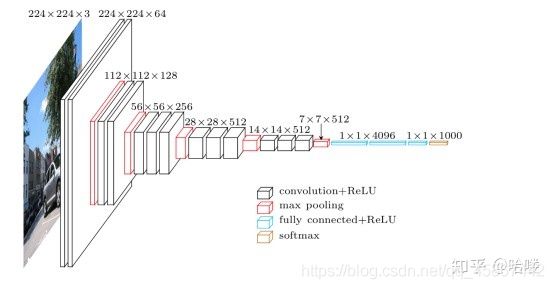
VGG网络相比AlexNet层数多了不少,但是其结构却简单不少。
VGG的输入为224×224×3224×224×3的图像
对图像做均值预处理,每个像素中减去在训练集上计算的RGB均值。
网络使用连续的小卷积核(3×33×3)做连续卷积,卷积的固定步长为1,并在图像的边缘填充1个像素,这样卷积后保持图像的分辨率不变。
连续的卷积层会接着一个池化层,降低图像的分辨率。空间池化由五个最大池化层进行,这些层在一些卷积层之后(不是所有的卷积层之后都是最大池化)。在2×2像素窗口上进行最大池化,步长为2。
卷积层后,接着的是3个全连接层,前两个每个都有4096个通道,第三是输出层输出1000个分类。
所有的隐藏层的激活函数都使用的是ReLU
使用1×11×1的卷积核,为了添加非线性激活函数的个数,而且不影响卷积层的感受野。
没有使用局部归一化,作者发现局部归一化并不能提高网络的性能。
2.2VGG原理
VGG16相比AlexNet的一个改进是采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)。对于给定的感受野(与输出有关的输入图片的局部大小),采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且代价还比较小(参数更少)。
感受野:在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野(receptivefield)。通俗的解释是,输出feature map上的一个单元对应输入层上的区域大小。
简单来说,在VGG中,使用了3个3x3卷积核来代替7x7卷积核,使用了2个3x3卷积核来代替5*5卷积核,这样做的主要目的是在保证具有相同感知野的条件下,提升了网络的深度,在一定程度上提升了神经网络的效果。
比如,3个步长为1的3x3卷积核的一层层叠加作用可看成一个大小为7的感受野(其实就表示3个3x3连续卷积相当于一个7x7卷积),其参数总量为 3x(9xC^2) ,如果直接使用7x7卷积核,其参数总量为 49xC^2 ,这里 C 指的是输入和输出的通道数。很明显,27xC2小于49xC2,即减少了参数;而且3x3卷积核有利于更好地保持图像性质。
这里解释一下为什么使用2个3x3卷积核可以来代替5*5卷积核:
5x5卷积看做一个小的全连接网络在5x5区域滑动,我们可以先用一个3x3的卷积滤波器卷积,然后再用一个全连接层连接这个3x3卷积输出,这个全连接层我们也可以看做一个3x3卷积层。这样我们就可以用两个3x3卷积级联(叠加)起来代替一个 5x5卷积。
三.网络实战(Pytorch)
3.1 数据集准备
本文采用博主提供的花分类数据集,下载地址如下:
https://link.zhihu.com/?target=http%3A//download.tensorflow.org/example_images/flower_photos.tgz
3.2 项目下载
项目下载链接:
https://link.zhihu.com/?target=https%3A//github.com/WZMIAOMIAO/deep-learning-for-image-processing
3.3 开发环境搭建
Anaconda创建虚拟环境 编辑器pycharm 深度学习框架Pytorch python3.6
详细环境可参考我的知乎主页:
https://www.zhihu.com/people/shi-wo-89-57/posts
3.4 模型训练
在项目Test3_vggnet文件夹下创建新文件夹"flower_data";
将下载的数据集解压到flower_data文件夹下;
执行"split_data.py"脚本自动将数据集划分成训练集train和验证集val;
执行train.py文件 注意将数据路径修改为当前文件夹下;
生成vgg16Net.pth权重文件 。
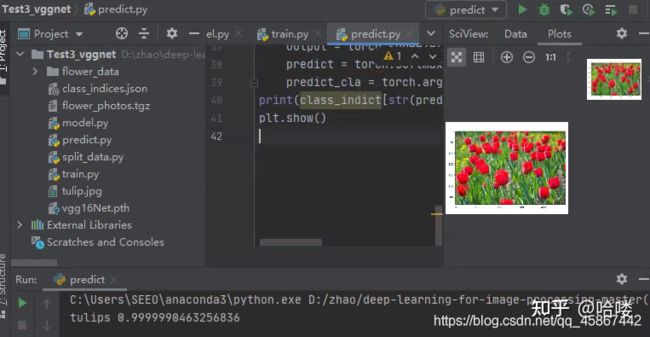
3.5 结果展示
利用生成vgg16Net.pth权重文件 下载一张tulip.jpg照片用于测试
执行predict.py文件用于测试
结果展示图
参考
https://zhuanlan.zhihu.com/p/41423739
https://link.zhihu.com/?target=https%3A//www.cnblogs.com/wangguchangqing/p/10338560.html
https://link.zhihu.com/?target=https%3A//blog.csdn.net/qq_37902216/article/details/89327761
由于水平有限,文章中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!有任何疑问的小伙伴都可以私信,大家一起学习交流。

