机器学习笔记:scikit-learn pipeline使用示例
0. 前言
在机器学习中,管道机制是指将一系列处理步骤串连起来自动地一个接一个地运行的机制。Scikit-Learn提供了pipeline类用于实现机器学习管道,使用起来十分方便。
既然要将不同处理步骤串联起来,首先必须确保每个步骤的输出与下一个步骤的输入的数据是匹配的。所以,管道中的每个步骤都包含两个方法,fit()用于拟合(或者说训练),transform()用于数据转换(将数据转换为下一个步骤所需要的输入数据格式)。
管道的最后一个步骤应该是一个估计器,估计器不再需要数据转换,因此估计器只需要实现fit()方法。
管道的最有用的目的是串联几个可以一起交叉验证的steps,同时设置不同的参数,使得交叉验证可以以非常高效的方式进行。熟练地使用管道可以大大提高机器学习建模和优化的过程。管道的示意图如下所示:
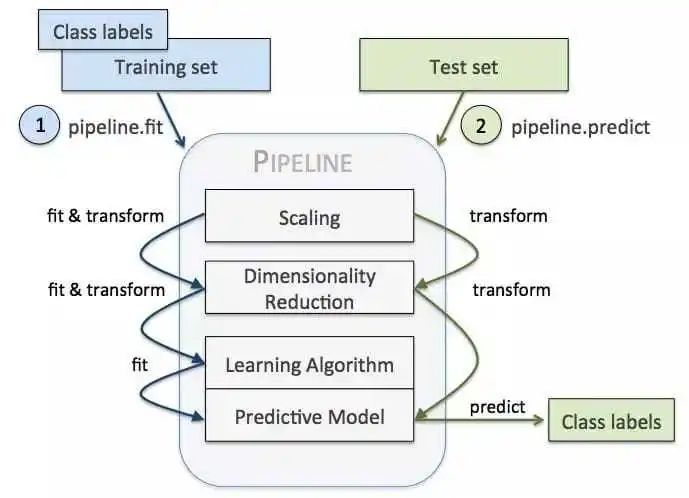
以下结合示例来介绍scikit-learn的管道使用方法。
1. 示例1:SVC分类器
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
X, y = make_classification(random_state=1)
x_train, x_test, y_train, y_test = train_test_split(X, y, random_state=1)
# non-pipeline modelling
scaler = StandardScaler()
scaler.fit(x_train)
x_train_scaled = scaler.transform(x_train)
x_test_scaled = scaler.transform(x_test)
svc = SVC()
svc.fit(x_train_scaled,y_train)
print(svc.score(x_test_scaled, y_test))
# pipeline modelling
pipe= Pipeline([('scaler', StandardScaler()), ('svc', SVC())])
print(pipe.fit(x_train, y_train))
print(pipe.score(x_test, y_test))以上代码中包含两种建模方式,一种是不使用pipeline,一种是使用pipeline。
非pipeline方式中,缩放处理和训练处理是分开来进行的。缩放处理采用的是StandardScaler,它先基于训练集进行训练,然后基于相同的训练模型对训练集和测试集实施相同的缩放处理。这一点非常重要,如果没有对训练集和测试集执行想用的缩放处理会导致模型训练失效。
在利用Pipeline的实现中,缩放处理和训练处理由Pipeline()串联起来,代码量只有前一种方法的一半都不到。而且没有显式地出现x_train_scaled和x_test_scaled。
当然,这本来就是一个非常简单的例子,所以利用管道建模训练所带的好处可能并不是那么显著。
运行以上结果会得到如下结果,可见两种方式的结果完全相同:
0.92
Pipeline(steps=[('scaler', StandardScaler()), ('svc', SVC())])
0.92
2. 示例2:基于PCA和决策树进行iris分类
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.tree import DecisionTreeClassifier
iris = datasets.load_iris()
x = iris.data
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25)
from sklearn.pipeline import Pipeline
pipeline = Pipeline([('pca', PCA(n_components = 4)), ('std', StandardScaler()), ('Decision_tree', DecisionTreeClassifier())], verbose = True)
pipeline.fit(x_train, y_train)
# to see all the hyper parameters
pipeline.get_params()在这个示例中,用先用PCA对数据进行降维处理,然后进行数据缩放处理,最后再利用决策树进行分类。运行结果如下。注意,在调用Pipeline时将verbose参数设置为True,这样会将训练过程中的一些细节信息打印出来。
[Pipeline] ............... (step 1 of 3) Processing pca, total= 0.0s [Pipeline] ............... (step 2 of 3) Processing std, total= 0.0s [Pipeline] ..... (step 3 of 3) Processing Decision_tree, total= 0.0s 0.8947368421052632
然后可以用get_params()方法显示训练所得的各步骤的参数。
3. 示例3:用朴素贝叶斯方法进行iris分类,以及make_pipeline()
scikit-learn还提供一个快捷的构建管道的函数make_pipeline()。
以下利用make_pipeline()构建一个基于朴素贝叶斯算法的iris分类模型,如下所示:
from sklearn.naive_bayes import GaussianNB
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(StandardScaler(), GaussianNB(priors=None), verbose=True)
iris = datasets.load_iris()
x = iris.data
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.25)
pipe.fit(x_train, y_train)
print(pipeline.score(x_test, y_test))
# to see all the hyper parameters
pipe.get_params()[Pipeline] .... (step 1 of 2) Processing standardscaler, total= 0.0s [Pipeline] ........ (step 2 of 2) Processing gaussiannb, total= 0.0s 0.9736842105263158Out[18]:
{'memory': None, 'steps': [('standardscaler', StandardScaler()), ('gaussiannb', GaussianNB())], 'verbose': True, 'standardscaler': StandardScaler(), 'gaussiannb': GaussianNB(), 'standardscaler__copy': True, 'standardscaler__with_mean': True, 'standardscaler__with_std': True, 'gaussiannb__priors': None, 'gaussiannb__var_smoothing': 1e-09}
这种模型的测试机分类准确度达到97%,远远好于上面基于PCA加决策树算法的89%。
4. 示例4:基于Pipeline进行模型选择
模型选择 Pipeline 还可以用于模型选择。下面的示例中我们就尝试了许多 scikit-learn 分类器进行模型选择。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score, log_loss
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC, LinearSVC, NuSVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, GradientBoostingClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.pipeline import Pipeline
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="rbf", C=0.025, probability=True),
NuSVC(probability=True),
DecisionTreeClassifier(),
RandomForestClassifier(),
AdaBoostClassifier(),
GradientBoostingClassifier()
]
for classifier in classifiers:
pipe = Pipeline(steps=[('scaler', StandardScaler()),
('classifier', classifier)])
pipe.fit(X_train, y_train)
print(classifier)
print("model score: %.3f" % pipe.score(X_test, y_test))运行结果如下:
KNeighborsClassifier(n_neighbors=3) model score: 0.895 SVC(C=0.025, probability=True) model score: 0.579 NuSVC(probability=True) model score: 0.868 DecisionTreeClassifier() model score: 0.868 RandomForestClassifier() model score: 0.895 AdaBoostClassifier() model score: 0.947 GradientBoostingClassifier() model score: 0.868
有趣的是,其中居然有三种算法得到的了完全相同的结果86.8%。
5. 示例5:利用管道结合网格搜索进行模型参数最优搜索
Pipeline 可结合网格搜索以找到性能最佳的模型参数。
第一步是为所选模型创建参数网格。需要注意的是,这里需要把分类器的名称附加到每个参数名称中,比如如下的随机森林建模代码中,将分类器的名称定义为 classifier,所以这里就需要在每个参数前添加 classifier__ 的前缀。接下来,创建一个包含原始 pipeline 的网格搜索对象。这样当进行网格搜索时,都会包含数据预处理以及用相应参数创建模型的步骤。
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
rf = Pipeline(steps=[('scaler', StandardScaler()),
('classifier', RandomForestClassifier())])
param_grid = {
'classifier__n_estimators': [200, 500],
'classifier__max_features': ['auto', 'sqrt', 'log2'],
'classifier__max_depth' : [4,5,6,7,8],
'classifier__criterion' :['gini', 'entropy']}
from sklearn.model_selection import GridSearchCV
CV = GridSearchCV(rf, param_grid, n_jobs= 1)
CV.fit(X_train, y_train)
print(CV.best_params_)
print(CV.best_score_)运行结果(注意,由于以上是进行网格搜索,所以运行需要花一些时间)如下:
{'classifier__criterion': 'gini', 'classifier__max_depth': 4, 'classifier__max_features': 'auto', 'classifier__n_estimators': 200}
0.9731225296442687