【笔记】GraphSAIL: Graph Structure Aware Incremental Learning for Recommender Systems(面向推荐系统的图结构感知增量学习)
GraphSAIL: Graph Structure Aware Incremental Learning for Recommender Systems(面向推荐系统的图结构感知增量学习)
CIKM 2020
实际情况下,我们使用固定时间段内(例如最近30天)的数据来训练模型。并没有获取最近数据,而最新数据却是一个模型捕获用户最新偏好的关键。然而只使用最新的数据对模型进行重新训练往往会导致遗忘问题,模型会丢失捕获长期偏好所需要的用户信息。
本研究在模型进行增量训练过程中保留图中的每一个节点的局部结构、全局结构和自身信息,从而保留了用户的信息以解决增量学习的遗忘问题,建立一个能够准确地捕捉用户长期和短期偏好的模型。
Incremental Learning(增量学习)
增量学习是能够不断地处理新数据,在吸收新知识的同时保留甚至整合、优化旧知识的能力。
在机器学习领域,增量学习致力于解决模型训练灾难性遗忘这一缺陷 ,即一般模型在新任务上训练时,在旧任务上的表现通常会显著下降。
为了克服灾难性遗忘,我们希望模型一方面具备从新数据中整合新知识,提炼已有知识的能力(可塑性),另一方面又必须防止新输入对已有知识的显著干扰(稳定性)。
增量学习方法的种类有很多种划分方式,主要存在:
- 正则化(regularization)
- 回放(replay)
- 参数隔离(parameter isolation)
本研究采用的是基于正则化的增量学习**:通过在新任务的损失函数添加约束来保护旧知识不被新知识覆盖**。
该模型是基于GCN和知识蒸馏构建的。
Knowledge Distillation(知识蒸馏)
知识蒸馏核心思想是先训练一个复杂网络模型,然后使用这个复杂网络的输出和数据去训练一个更小的网络,因此知识蒸馏框架通常包含了一个复杂模型(被称为Teacher模型)和一个小模型(被称为Student模型)。
知识蒸馏采取Teacher-Student模式:将复杂且大的模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。
本文的知识蒸馏用于增量训练一个基于GNN的推荐模型,本研究提出了三个通用组件:
Local Structure Distillation(局部结构蒸馏)
以User-Item二部图的User节点为例,用户 U U U在 t − 1 t-1 t−1时间段的邻域集表示为 N u t − 1 N_u^{t-1} Nut−1,它包含该用户在该时间帧中交互过的项目。在新的时间帧 t t t,我们希望将已经训练好的用户嵌入表示 e m b u t − 1 emb_u^{t-1} embut−1和其邻居的嵌入表示 c u , N u t − 1 t − 1 c_{u,N_u^{t-1}}^{t-1} cu,Nut−1t−1的点积从 t − 1 t-1 t−1时间帧转移至增量训练的学生模型中。我们通过最小化在 t − 1 t-1 t−1时间帧的数据训练的教师模型和使用 t t t时间帧的最新数据训练的学生模型的点积只差来实现。
邻域的平均嵌入 c u , N u t − 1 t − 1 c_{u,N_u^{t-1}}^{t-1} cu,Nut−1t−1和 c u , N u t − 1 t c_{u,N_u^{t-1}}^{t} cu,Nut−1t分别在 t − 1 t-1 t−1和 t t t时间帧对用户 U U U的一般偏好进行编码。通过确保 e m b u t − 1 emb_u^{t-1} embut−1与 c u , N u t − 1 t − 1 c_{u,N_u^{t-1}}^{t-1} cu,Nut−1t−1的点积接近于 e m b u t emb_u^{t} embut与 c u , N u t − 1 t c_{u,N_u^{t-1}}^{t} cu,Nut−1t的点积。该模型即可显式地保留用户的历史偏好。Item节点同理。

U \mathcal U U和 I \mathcal I I分别表示用户和项目集合。 ∣ U ∣ |\mathcal U| ∣U∣表示集合的元素个数。 N U t \mathcal N_U^t NUt表示 t t t时间帧用户 u u u的邻域节点集合。 c u , N u t − 1 t − 1 c_{u,N_u^{t-1}}^{t-1} cu,Nut−1t−1表 t − 1 t-1 t−1时间帧用户u邻域的平均嵌入向量表示。
Global Structure Distillation(全局结构蒸馏)
局部蒸馏方案能够促进教师模型的局部信息向学生模型转移,但不能捕获每个节点的全局位置信息。User节点的嵌入表示之间的距离可以编码User是否属于同一偏好组;User和Item节点的嵌入表示之间的距离可以编码User喜欢的Item类型。因此我们的任务就是保留每一个节点相对于其他节点的距离的嵌入表示。
本文提出使用一组锚点的embedding来编码全局结构信息。这些锚点的embedding是通过对User和Item进行K-Means操作,对得到的聚类的的嵌入表示求平均得来的。每一个聚类代表着一个用户的偏好组或者一个项目类别。
对于每个用户节点构造两个概率分布,第一个捕获用户属于用户偏好组的概率,第二个表示用户喜欢特定项目的概率。项目节点也同理。这些概率分布是通过考虑锚点嵌入向量的相似度来构造的。
在损失函数中引入正则化项,鼓励匹配教师和学生的聚类分布来实现知识转移。我们的目标是最小化教师模型和学生模型全局结构分布的KL散度之和。对于用户节点,教师模型和学生模型之间的全局结构相似性可以计算为:
A u t \mathcal A_u^t Aut和 A u t − 1 \mathcal A_u^{t-1} Aut−1是分别使用 e m b t 和 e m b t − 1 emb^t和emb^{t-1} embt和embt−1在 t − 1 t-1 t−1时间帧聚集每个节点的聚类的平均嵌入向量的集合。 G S u , A u t , k t GS_{u,\mathcal A_u^{t,k}}^t GSu,Aut,kt和 G S u , A u t − 1 , k t − 1 GS_{u,\mathcal A_u^{t-1,k}}^{t-1} GSu,Aut−1,kt−1分别是学生模型和教师模型的 A u t \mathcal A_u^t Aut和 A u t − 1 \mathcal A_u^{t-1} Aut−1中包含的K个用户锚点的嵌入表示关联的全局结构分布的第K个条目。
为了计算最终的全局结构蒸馏损失,我们计算给定图的所有节点上分布之间的KL散度的平均值:

Self-embedding Distillation(自嵌入蒸馏)
为了维护User和Item自身的信息,我们在损失函数中加入均方误差项,直接提取用户和项目的embedding中的知识。
这确保了每一个增量学习的embedding向量不会偏离以前的位置太远。 我们使用权重因子η来控制每个节点的精馏强度,权重因子η与新数据块中每个节点引入的新记录数成正比。 也就是说,对于历史记录更丰富的节点,我们增强了蒸馏强度。 自embedding向量的蒸馏损失项为:
η u η_u ηu和 η i η_i ηi是控制各节点蒸馏强度的系数
Loss
使用贝叶斯个性化排序(BPR)损失优化模型:
其中 O = { ( u , i , j ) ∣ ( u , i ) ∈ R + , ( u , j ) ∈ R − } \mathcal O=\{(u,i,j)|(u,i)∈\mathcal R^+,(u,j)∈\mathcal R^-\} O={(u,i,j)∣(u,i)∈R+,(u,j)∈R−}表示训练批次, θ θ θ是模型参数集。 R + , R − R^+,R^- R+,R−分别表示正样本和负样本。
总Loss
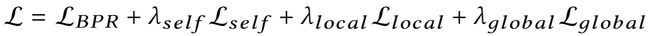
其中 λ s e l f λ_{self} λself, λ l o c a l λ_{local} λlocal和 λ g l o b a l λ_{global} λglobal分别是控制自embedding向量、局部结构蒸馏和全局结构蒸馏大小的超参数。