手把手教你百度飞桨PP-YOLOE部署到瑞芯微RK3588
目录
前言
一、环境搭建
1、Anaconda3安装
1.1、下载
1.2、安装
2、paddle模型导出环境
2.1、创建环境
2.2、进入环境
2.3、paddle安装
2.4、PaddleDetection安装
2.5、解决相关依赖问题
3、paddle转onnx转rknn环境
3.1、创建环境
3.2、进入环境
3.3、RKNN-Toolkit2工具安装
3.3、paddle2onnx工具安装
3.4、解决相关依赖问题
二、模型转换
1、模型导出
2、paddle转onnx
3、onnx转rknn
三、运行例程
前言
PP-YOLOE是百度飞桨团队发布的目标检测模型,PP-YOLOE是基于PP-YOLOv2的卓越的单阶段Anchor-free模型,超越了多种流行的YOLO模型。PP-YOLOE有一系列的模型,即s/m/l/x,可以通过width multiplier和depth multiplier配置。PP-YOLOE避免了使用诸如Deformable Convolution或者Matrix NMS之类的特殊算子,以使其能轻松地部署在多种多样的硬件上.
RK3588是瑞芯微发布的新一代高性能旗舰Soc芯片,采用ARM架构,采用先进的8nm制程工艺,集成了四核Cortex-A76和四核Cortex-A55(共8核),以及单独的NEON协处理器,支持8K视频编解码,内部集成独立的NPU处理器,可提供高达6TOPS算力,可以满足绝大多数终端设备的边缘计算需求,提供了许多功能强大的嵌入式硬件引擎,为高端应用提供了极致的性能,同时提供了丰富的功能接口,可满足不同行业的产品定制需求。
本文着重介绍如何将百度飞桨PP-YOLOE模型部署到瑞芯微RK3588,内容包括:环境搭建、模型转换、运行例程等。另外,整个部署过程的难点在于模型转换,模型转换的总体框架如下:
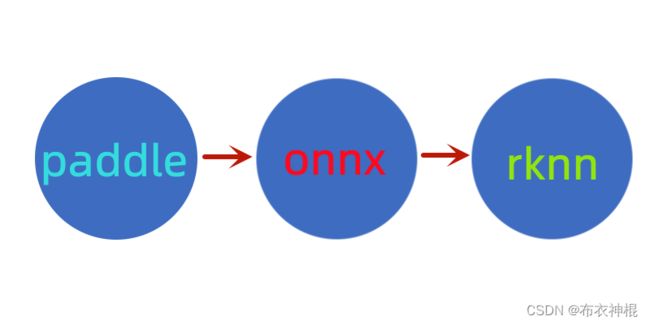
paddle模型无法直接转为瑞芯微的rknn格式,所以要先将paddle模型转换为onnx,再将onnx转rknn。
一、环境搭建
系统:Ubuntu18.04.5(x64)
用户:root
在部署过程中,不同步骤下的操作要求的环境会有所差异,甚至会有一些软件包版本冲突的问题,所以这边使用conda来进行环境管理。
1、Anaconda3安装
1.1、下载
清华镜像官网下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
此处下载Anaconda3-2022.10-Linux-x86_64.sh
1.2、安装
使用bash命令安装:
# bash Anaconda3-2022.10-Linux-x86_64.sh 然后一路输入yes回车,默认在用户主目录下创建一个名为anaconda3的文件夹作为安装地址,此处用的是root账号,所以安装在/root/anaconda3目录下。
Anaconda安装完成以后出现的个提示解读:
(1)For changes to take effect, close and re-open your current shell.,翻译过来就是:关闭当前命令行,并重新打开,刚刚安装和初始化Anaconda设置才可以生效,重新打开一个命令行后直接就进入了conda的base环境。
(2)If you'd prefer that conda's base environment not be activated on startup, set the auto_activate_base parameter to false: ,翻译过来就是:如果您希望 conda 的基础环境在启动时不被激活,请将 auto_activate_base 参数设置为 false,命令如下:
# conda config --set auto_activate_base false当然这一条命令执行完毕后,想要再次进入conda的base环境,只需要使用对应的conda指令即可,如下:
# conda activate base到此,Anaconda3安装完毕。
2、paddle模型导出环境
PP-YOLOE是百度飞桨paddle的目标检测模型,paddle目标检测模型的导出依赖于PaddleDetection,所以要安装PaddleDetection工具包。之所以要单独搭建此环境,是因为PaddleDetection工具依赖的onnx、numpy等软件包版本与瑞星微RK3588的rknn-toolkit2不兼容。
PaddleDetection版本:2.5.0
rknn-toolkit2版本:1.3.0
2.1、创建环境
选择python3.8.13包进行创建环境,命令如下:
# conda create --name paddleExport python==3.8.132.2、进入环境
命令如下:
# conda activate paddleExport注:如无特别说明,本章节下文所有操作均在所创建的环境中进行。
2.3、paddle安装
在安装PaddleDetection工具之前先安装paddle包,使用清华大学开源软件镜像站安装paddle包,地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/
安装之前可以先查看下各个版本依赖库:
# conda search --full-name paddlepaddle --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ --info这里选择2.3.2的cpu版本进行安装:
# conda install paddlepaddle=2.3.2 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/验证安装:
输入python回车,进入python解释器,输入import paddle ,再输入 paddle.utils.run_check()如果出现PaddlePaddle is installed successfully!,说明已成功安装。
(paddleExport) root@micro:~# python
Python 3.8.13 (default, Oct 21 2022, 23:50:54)
[GCC 11.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import paddle
>>> paddle.utils.run_check()
Running verify PaddlePaddle program ...
PaddlePaddle works well on 1 CPU.
W1102 17:33:39.837543 4740 fuse_all_reduce_op_pass.cc:76] Find all_reduce operators: 2. To make the speed faster, some all_reduce ops are fused during training, after fusion, the number of all_reduce ops is 2.
PaddlePaddle works well on 2 CPUs.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
>>>
2.4、PaddleDetection安装
安装文档参考:https://toscode.gitee.com/paddlepaddle/PaddleDetection/blob/release/2.5/docs/tutorials/INSTALL_cn.md
创建工作目录并切换到工作目录后下载源码:
# mkdir -p /home/tools/baidu/paddle
# cd /home/tools/baidu/paddle
# git clone https://github.com/PaddlePaddle/PaddleDetection安装PaddleDetection依赖库:
# cd /home/tools/baidu/paddle/PaddleDetection
# pip install -r requirements.txt编译安装PaddleDetection:
# python setup.py install验证安装:
# python ppdet/modeling/tests/test_architectures.py
.......
----------------------------------------------------------------------
Ran 7 tests in 5.532s
OK看见以上输出提示,说明安装成功。
2.5、解决相关依赖问题
到此,paddle模型导出环境基本搭建完成,但是还要解决一下包依赖的问题。
安装pip依赖查看工具:
# pip install pipdeptree查看依赖关系:
# pipdeptree -p paddlepaddle
Warning!!! Possibly conflicting dependencies found:
* paddlepaddle==2.3.2
- paddle-bfloat [required: ==0.1.7, installed: ?]
------------------------------------------------------------------------
paddlepaddle==2.3.2
- astor [required: Any, installed: 0.8.1]
- decorator [required: Any, installed: 5.1.1]
- numpy [required: >=1.13, installed: 1.23.3]
- opt-einsum [required: ==3.3.0, installed: 3.3.0]
- numpy [required: >=1.7, installed: 1.23.3]
- paddle-bfloat [required: ==0.1.7, installed: ?]
- Pillow [required: Any, installed: 9.2.0]
- protobuf [required: >=3.1.0,<=3.20.0, installed: 3.19.1]
- requests [required: >=2.20.0, installed: 2.28.1]
- certifi [required: >=2017.4.17, installed: 2022.9.24]
- charset-normalizer [required: >=2,<3, installed: 2.0.4]
- idna [required: >=2.5,<4, installed: 3.4]
- urllib3 [required: >=1.21.1,<1.27, installed: 1.26.12]
- six [required: Any, installed: 1.16.0]
从上面打印信息得知一些依赖包问题,进行修复:
# pip install paddle-bfloat==0.1.73、paddle转onnx转rknn环境
paddle转onnx和onnx转rknn两个环境可以分开搭建,也可以搭建在一起。这里选择搭建在一起,方便onnx版本对齐,避免转换过程中onnx版本不兼容造成的失败。
3.1、创建环境
选择python3.8.13包进行创建环境
# conda create --name paddle2rknn libprotobuf python==3.8.133.2、进入环境
命令如下:
# conda activate paddle2rknn注:如无特别说明,本章节下文所有操作均在所创建的环境中进行。
3.3、RKNN-Toolkit2工具安装
RKNN-Toolkit2是为用户提供在 PC、Rockchip NPU 平台上进行模型转换、推理和性能评估的开发套件,RKNN-Toolkit2适用于RK3566、RK3568、RK3588/RK3588S、RV1103、RV1106等型号的芯片。RKNN-Toolkit2的开源地址https://github.com/rockchip-linux/rknn-toolkit2,从中我们可以获取它的百度网盘下载地址。
百度网盘地址:https://eyun.baidu.com/s/3eTDMk6Y#sharelink/path=%2F
密码:rknn
这边拿到的RK3588开发板上rknpu的API及驱动版本是1.3.0,所以这里选择RK_NPU_SDK_1.3.0的release版本进行下载。下载解压后这里RKNN-Toolkit2的根目录为/home/tools/rockchip/RK_NPU_SDK_1.3.0/rknn-toolkit2-1.3.0。目前提供两种方式安装RKNN-Toolkit2:一是通过Python包安装与管理工具pip进行安装;二是运行带完整RKNN-Toolkit2工具包的docker镜像。本文采用第一种方式。
切换到RKNN-Toolkit2根目录:
# cd /home/tools/rockchip/RK_NPU_SDK_1.3.0/rknn-toolkit2-1.3.0安装依赖,因为我们环境的python版本是3.8.13,所以这里执行:
# pip3 install -r doc/requirements_cp38-1.3.0.txt安装RKNN-Toolkit2:
# pip3 install packages/rknn_toolkit2-1.3.0_11912b58-cp38-cp38-linux_x86_64.whl3.3、paddle2onnx工具安装
paddle2onnx支持将PaddlePaddle模型格式转化到ONNX模型格式。paddle2onnx也依赖于paddle包,在新的环境中需要重新安装paddle包,paddle包的安装请参考前面章节。
查看paddle2onnx可安装版本:
# pip3 index versions paddle2onnx
WARNING: pip index is currently an experimental command. It may be removed/changed in a future release without prior warning.
paddle2onnx (1.0.1)
Available versions: 1.0.1, 1.0.0, 0.9.8, 0.9.7, 0.9.6, 0.9.5, 0.9.4, 0.9.2, 0.9.1, 0.9.0, 0.8.2, 0.8.1, 0.8, 0.7, 0.6, 0.5.1, 0.5, 0.4, 0.3.2, 0.3.1默认安装的就是最新版本,这里指定0.9.8版本,否则会因为onnx版本版本太高,与RKNN-Toolkit2不兼容:
# pip install paddle2onnx==0.9.83.4、解决相关依赖问题
到此,paddle转onnx转rknn环境基本搭建完成,但是还要解决一下包依赖的问题。
安装pip依赖查看工具:
# pip install pipdeptree查看依赖关系:
# pipdeptree -p paddle2onnx
Warning!!! Possibly conflicting dependencies found:
* paddlepaddle==2.3.2
- paddle-bfloat [required: ==0.1.7, installed: ?]
* rknn-toolkit2==1.3.0-11912b58
- numpy [required: ==1.17.3, installed: 1.23.3]
- protobuf [required: ==3.12.0, installed: 3.19.1]
- requests [required: ==2.21.0, installed: 2.28.1]
------------------------------------------------------------------------
paddle2onnx==0.9.8从上面打印信息得知一些依赖包版本不对,进行修复:
# pip install paddle-bfloat==0.1.7
# pip install numpy==1.17.3
# pip install protobuf==3.12.0
# pip install requests==2.21.0二、模型转换
paddle目前有四大类模型:目标检测、分类、OCR以及分割,这里选择的ppyoloe是目标检测的一种。
1、模型导出
参考文档:
https://gitee.com/paddlepaddle/PaddleDetection/tree/develop
https://gitee.com/paddlepaddle/PaddleDetection/blob/develop/deploy/EXPORT_MODEL.md
切换到前面搭建的模型导出环境并进入PaddleDetection工作目录:
# conda activate paddleExport
# cd /home/tools/baidu/paddle/PaddleDetection模型导出可以在线下载模型进行导出:
# python tools/export_model.py \
-c configs/ppyoloe/ppyoloe_crn_s_300e_coco.yml \
--output_dir=/home/tools/baidu/paddle/model/ppyoloe \
-o weights=https://paddledet.bj.bcebos.com/models/ppyoloe_crn_s_300e_coco.pdparams \
use_gpu=False exclude_nms=True也可以将原始模型文件下载到本地进行导出:
# python tools/export_model.py \
-c configs/ppyoloe/ppyoloe_crn_s_300e_coco.yml \
--output_dir=/home/tools/baidu/paddle/model/ppyoloe \
-o weights=/home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco.pdparams \
use_gpu=False exclude_nms=True参数说明:
-c 指定配置文件
--output_dir 模型保存路径
-o 输出相关配置,其中:
weights:训练得到的模型,扩展名为pdparams
use_gpu:是否使用gpu
exclude_nms:裁剪掉模型中后处理的nms部分
当前环境没有gpu,所以设置use_gpu=False;
rknn目前不支持NonZero算子,所以要裁剪掉模型中后处理的nms部分,设置 exclude_nms=True
预测模型会导出到/home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco目录下,分别为infer_cfg.yml, model.pdiparams, model.pdiparams.info, model.pdmodel。
2、paddle转onnx
参考:https://toscode.gitee.com/paddlepaddle/Paddle2ONNX
切换到paddle转onnx转rknn环境:
# conda activate paddle2rknnpaddle转onnx命令:
# paddle2onnx --model_dir /home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/ \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 12 \
--save_file /home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/model.onnx \
--enable_onnx_checker True参数说明:
--model_dir:配置包含 Paddle 模型的目录路径
--model_filename:配置位于 --model_dir 下存储网络结构的文件名
--params_filename:配置位于 --model_dir 下存储模型参数的文件名称
--opset_version:配置转换为 ONNX 的 OpSet 版本,目前支持 7~16 等多个版本,默认为 9,这里选择12,为了与rknn-toolkit2兼容。
--save_file:指定转换后的模型保存目录路径
--enable_onnx_checker:配置是否检查导出为 ONNX 模型的正确性, 建议打开此开关, 默认为 False
转换完的onnx文件位于:/home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/model.onnx,但是这个模型没法拿去转换成rknn,原因是rknn需要固定输入shape,所以我们在转换的时候还需要使用input_shape_dict来设置固定输入shape。那如何确定输入shape的参数呢?从以下网址:https://toscode.gitee.com/paddlepaddle/PaddleDetection/blob/release/2.5/deploy/EXPORT_MODEL.md
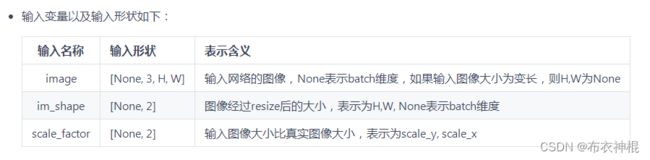
我们可以得知,paddle目标检测模型有1~3个输入,那又如何确定具体要填什么样的值?我们可以使用以下python代码,先把之前转的onnx模型的输入输出打印出来:
import onnx
import numpy as np
import logging
logging.basicConfig(level=logging.INFO)
def onnx_datatype_to_npType(data_type):
if data_type == 1:
return np.float32
else:
raise TypeError("don't support data type")
def parser_initializer(initializer):
name = initializer.name
logging.info(f"initializer name: {name}")
dims = initializer.dims
shape = [x for x in dims]
logging.info(f"initializer with shape:{shape}")
dtype = initializer.data_type
logging.info(f"initializer with type: {onnx_datatype_to_npType(dtype)} ")
# print tenth buffer
weights = np.frombuffer(initializer.raw_data, dtype=onnx_datatype_to_npType(dtype))
logging.info(f"initializer first 10 wights:{weights[:10]}")
def parser_tensor(tensor, use='normal'):
name = tensor.name
logging.info(f"{use} tensor name: {name}")
data_type = tensor.type.tensor_type.elem_type
logging.info(f"{use} tensor data type: {data_type}")
dims = tensor.type.tensor_type.shape.dim
shape = []
for i, dim in enumerate(dims):
shape.append(dim.dim_value)
logging.info(f"{use} tensor with shape:{shape} ")
def parser_node(node):
def attri_value(attri):
if attri.type == 1:
return attri.i
elif attri.type == 7:
return list(attri.ints)
name = node.name
logging.info(f"node name:{name}")
opType = node.op_type
logging.info(f"node op type:{opType}")
inputs = list(node.input)
logging.info(f"node with {len(inputs)} inputs:{inputs}")
outputs = list(node.output)
logging.info(f"node with {len(outputs)} outputs:{outputs}")
attributes = node.attribute
for attri in attributes:
name = attri.name
value = attri_value(attri)
logging.info(f"{name} with value:{value}")
def parser_info(onnx_model):
ir_version = onnx_model.ir_version
producer_name = onnx_model.producer_name
producer_version = onnx_model.producer_version
for info in [ir_version, producer_name, producer_version]:
logging.info("onnx model with info:{}".format(info))
def parser_inputs(onnx_graph):
inputs = onnx_graph.input
for input in inputs:
parser_tensor(input, 'input')
def parser_outputs(onnx_graph):
outputs = onnx_graph.output
for output in outputs:
parser_tensor(output, 'output')
def parser_graph_initializers(onnx_graph):
initializers = onnx_graph.initializer
for initializer in initializers:
parser_initializer(initializer)
def parser_graph_nodes(onnx_graph):
nodes = onnx_graph.node
for node in nodes:
parser_node(node)
t = 1
def onnx_parser():
model_path = '/home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/model.onnx'
model = onnx.load(model_path)
# 0.
parser_info(model)
graph = model.graph
# 1.
parser_inputs(graph)
# 2.
parser_outputs(graph)
# 3.
#parser_graph_initializers(graph)
# 4.
#parser_graph_nodes(graph)
if __name__ == '__main__':
onnx_parser()
代码保存为printOnnx.py,然后执行:
# python printOnnx.py
INFO:root:onnx model with info:7
INFO:root:onnx model with info:PaddlePaddle
INFO:root:onnx model with info:
INFO:root:input tensor name: image
INFO:root:input tensor data type: 1
INFO:root:input tensor with shape:[-1, 3, 640, 640]
INFO:root:input tensor name: scale_factor
INFO:root:input tensor data type: 1
INFO:root:input tensor with shape:[-1, 2]
INFO:root:output tensor name: tmp_17
INFO:root:output tensor data type: 1
INFO:root:output tensor with shape:[-1, 8400, 4]
INFO:root:output tensor name: concat_14.tmp_0
INFO:root:output tensor data type: 1
INFO:root:output tensor with shape:[-1, 80, 8400]从打印信息我们可以看到ppyoloe有两个输入shape,其中batch为-1表示不确定的,其它如图像大小等参数可以从中得知。使用以下新命令转出固定输入shape的onnx模型:
# paddle2onnx --model_dir /home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/ \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 12 \
--save_file /home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/model.onnx \
--input_shape_dict="{'image':[1,3,640,640], 'scale_factor':[1,2]}" \
--enable_onnx_checker True如果是高版本的paddle2onnx(貌似 > 0.9.8),则需使用以下命令:
# paddle2onnx --model_dir /home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/ \
--model_filename model.pdmodel \
--params_filename model.pdiparams \
--opset_version 12 \
--save_file /home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/model.onnx \
--enable_onnx_checker True
# python -m paddle2onnx.optimize \
--input_model /home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/model.onnx \
--output_model /home/tools/baidu/paddle/model/ppyoloe/ppyoloe_crn_s_300e_coco/model.onnx \
--input_shape_dict "{'image':[1,3,640,640], 'scale_factor':[1,2]}"转换完后,可以看到输入输出shape都固定下来了:
# python printOnnx.py
INFO:root:onnx model with info:7
INFO:root:onnx model with info:PaddlePaddle
INFO:root:onnx model with info:
INFO:root:input tensor name: image
INFO:root:input tensor data type: 1
INFO:root:input tensor with shape:[1, 3, 640, 640]
INFO:root:input tensor name: scale_factor
INFO:root:input tensor data type: 1
INFO:root:input tensor with shape:[1, 2]
INFO:root:output tensor name: tmp_17
INFO:root:output tensor data type: 1
INFO:root:output tensor with shape:[1, 8400, 4]
INFO:root:output tensor name: concat_14.tmp_0
INFO:root:output tensor data type: 1
INFO:root:output tensor with shape:[1, 80, 8400] 3、onnx转rknn
在前面下载RKNN-Toolkit2里有rknpu2_1.3.0.tar.gz文件,解压后参考RK_NPU_SDK_1.3.0/rknpu2_1.3.0/examples/rknn_yolov5_demo/convert_rknn_demo/yolov5/onnx2rknn.py编写ppyoloe的onnx转rknn的代码:
# coding=gbk
import cv2
import numpy as np
from rknn.api import RKNN
import os
ONNX_MODEL = 'ppyoloe_crn_s_300e_coco/model.onnx'
RKNN_MODEL = 'ppyoloe_crn_s_300e_coco/model.rknn'
if __name__ == '__main__':
NEED_BUILD_MODEL = True
# NEED_BUILD_MODEL = False
#生成scale_factor.npy
arr = np.array([1.0, 1.0])
np.save("scale_factor.npy", arr)
# Create RKNN object
rknn = RKNN(verbose=True)
if NEED_BUILD_MODEL:
DATASET = './dataset.txt'
#mean_values和std_values查看相应的infer_cfg.yml文件
#注意:infer_cfg.yml下is_scale:值为true,所以values值要除以scale[1.0/255],即:将values*255得到的值填入下面代码
#rknn默认读图方式是RGB,如果这里训练时是使用BGR,则量化时需要RGB转BGR
#rknn.config(mean_values=[[123.675, 116.28, 103.53]], std_values=[[58.395, 57.12, 57.375]], target_platform="rk3588")
rknn.config(mean_values=[[123.675, 116.28, 103.53]], std_values=[[58.395, 57.12, 57.375]], target_platform="rk3588", quant_img_RGB2BGR=True)
# Load model
print('--> Loading model')
#ret = rknn.load_onnx(model=ONNX_MODEL)
ret = rknn.load_onnx(model=ONNX_MODEL, input_size_list=[[1,3,640,640],[1,2]])
if ret != 0:
print('load model failed!')
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset=DATASET) #量化
#ret = rknn.build(do_quantization=False, dataset=DATASET) #不量化
if ret != 0:
print('build model failed.')
exit(ret)
print('done')
# Export rknn model
print('--> Export RKNN model: {}'.format(RKNN_MODEL))
ret = rknn.export_rknn(RKNN_MODEL)
if ret != 0:
print('Export rknn model failed.')
exit(ret)
print('done')
else:
ret = rknn.load_rknn(RKNN_MODEL)
rknn.release()
这里针对量化的时候,有几个地方需要注意:
(1)、rknn默认读图方式是RGB,如果这里训练时是使用BGR,则量化时需要RGB转BGR,在rknn.config时需要配置quant_img_RGB2BGR=True,ppyoloe是使用什么样的格式去训练的,这里还没有去验证。
(2)、从前面paddle转onnx时,我们得知ppyoloe有两个输入shape,所以在准备量化校正数据集时,我们也需要提供两个输入shape数据,即dataset.txt每行有两个文件,用空格隔开:
# cat dataset.txt
bus.jpg scale_factor.npy
1.jpg scale_factor.npy
第一个文件为图片文件
第二个文件为输入名称是scale_factor的shape信息,npy格式,表示输入图像大小比真实图像大小,这边都设置为1.0,在以上代码直接生成该文件。
运行以上代码,实现onnx转rknn:
# python3 onnx2rknn.py可能会碰到的错误:
E build: Catch exception when building RKNN model!
E build: Traceback (most recent call last):
E build: File "rknn/api/rknn_base.py", line 1680, in rknn.api.rknn_base.RKNNBase.build
E build: File "rknn/api/rknn_base.py", line 363, in rknn.api.rknn_base.RKNNBase._generate_rknn
E build: File "rknn/api/rknn_base.py", line 270, in rknn.api.rknn_base.RKNNBase._build_rknn
E build: ImportError: /lib/x86_64-linux-gnu/libm.so.6: version `GLIBC_2.29' not found (required by /root/anaconda3/envs/paddle2rknn/lib/python3.8/site-packages/rknn/api/lib/linux-x86_64/cp38/librknnc_v2.so)
build model failed.原因是需要2.29版本的GLIBC,解决方法参考:https://www.cnblogs.com/chenyirong/p/16342370.html
然后重新转换,不出意外的话,在代码设置的路径下就会生成我们想要的rknn模型文件,把它部署到开发板上就可以愉快的玩耍了~
三、运行例程
目前手上没有开发板,等有了再补上!