python拾遗
1.python的星号(*)和双星号(**)用法
一个表示 该位置接受**任意多个***非关键字**(non-keyword)参数,在函数中将其转化为元组(1,2,3,4)
两个*表示该位置接受任意多个关键字(keyword)参数,在函数位置上转化为词典** [key:value, key:value ]
def one(a,*b):
"""a是一个普通传入参数,*b是一个非关键字星号参数"""
print(b)
one(1,2,3,4,5,6)
#--------
def two(a=1,**b):
"""a是一个普通关键字参数,**b是一个关键字双星号参数"""
print(b)
two(a=1,b=2,c=3,d=4,e=5,f=6)
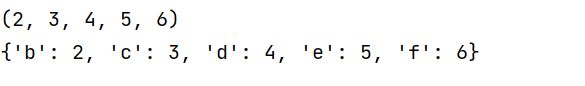
2.with的用法
源自 https://blog.csdn.net/sazass/article/details/116668755

3.next() 与 iter()
简单来说,iter()不管对象原先如何最后将其变成一个能够得到可迭代对象的 迭代器,
next()函数被用来多次提取迭代器中的数据
这边常用场合

用来不断抛出数据
3.1 iter 和 iter()
通俗的说:一个具备了__iter__方法的对象,就是一个可迭代对象
这个__iter__()里面甚至可以什么都不写
其实,当我们调用iter()函数提取一个可迭代对象的 迭代器时,实际上会自动调用这个对象的__iter__方法,并且这个方法返回迭代器
class MyList(object):
def __init__(self):
self.container = []
def add(self, item):
self.container.append(item)
def __iter__(self):
pass
3.1 next 和 next()
实际上,在使用next()函数的时候,调用的就是迭代器对象的__next__方法
4. hasattr()
hasattr(object, name)
object----对象
name----类名
这个是用来判断一个都对象里面有没有某个属性
eg.
class Test:
a=1
b=2
c=3
test=Test()
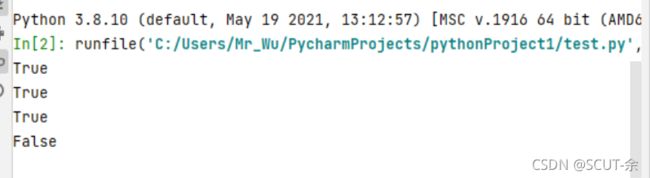
l=['a','b','c','no']
for i in l:
print(hasattr(test,i))
5. []*n
这是一个有些奇怪的表达
作用:用于形成一个基础的列表,列表的元素是原[]中的值,一共n个
class Accumulator: #@save
"""在`n`个变量上累加。"""
def __init__(self, n):
self.data = [0.0] * n
print(self.data)
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
metric=Accumulator(3)
效果:

6.assert
assert 判断句,表达式
if 判断句==1:
下个句子
else:
报错’AssertionError’并且执行表达式
经典例子 from 跟李沐学AI softmax
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)。"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc

意思是train_loss<0.5没有满足,并且给出了现在的train_loss的大小
AWFUL,MAN
7.super():
用于在子类中调用父类的函数
class Base(object):
def __init__(self):
print("enter Base")
print("leave Base")
class A(Base):
def __init__(self):
print("enter A")
super(A,self).__init__()
print("leave A")
class B(Base):
def __init__(self):
print("enter B")
super(B,self).__init__()
print("leave B")
class C(A,B):
def __init__(self):
print("enter C")
super(C,self).__init__()
print("leave C")
c=C()

效果解释,这里会用到C3算法,按照继承关系最后画出来的遍历图是 D-B-C-A
C3算法简单点说:
1.画出继承关系图
2.找到当前入度(就是指向它的线的数量)为0的点,无视层的影响,选出最左边的,一旦选了就把他的出度(指向其他点的线)删去
3.看向更新后的图,无视层的影响,从左往右选点(方法同2)
不断重复2与3(先2再3再2再3)
参考的
https://blog.csdn.net/m0_38063172/article/details/82250865?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163334143316780366591790%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=163334143316780366591790&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-82250865.pc_search_result_control_group&utm_term=python+super%E5%87%BD%E6%95%B0&spm=1018.2226.3001.4187
请自行观看
7.5 放在初始化的时候
这时候就是寻找 其父类,并且用其父类的初始化化函数去做初始化
下面就是Net类继承nn.Module,super(Net, self).init()就是对继承⾃⽗类nn.Module的属性进⾏初始
化,并且是⽤nn.Module的初始化⽅法来初始化继承的属性。
import torch
import torch.nn as nn
import torch.nn.functional as F
class QuantLinear(nn.Linear):
def __init__(self, in_features, out_features, bias=True):
super(QuantLinear, self).__init__(in_features, out_features, bias)
self.weight_labels = None
self.bias_labels = None
self.num_cent = None
self.quant_flag = False
self.quant_bias = False
8. (1,1)+x.shape
这个的效果是元组的拼接

import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape
9.super(class_name,self).init()
super是用于继承父类的方法 ,不用super的话,直接重写父类的方法会覆盖掉父类的方法,所以通过super来重写又能继承父类的方法
class Person(object):
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
class Student(Person):
def __init__(self, name, gender, age, school, score):
# super(Student,self).__init__(name,gender,age)
self.name = name.upper()
self.gender = gender.upper()
self.age = age
self.school = school
self.score = score
class Student2(Person):
def __init__(self, name, gender, age):
super(Student2,self).__init__(name, gender, age)
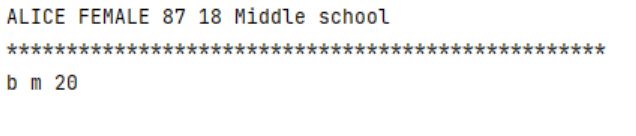
s1 = Student('Alice', 'female', 18, 'Middle school', 87)
s2= Student2('b', 'm', 20)
print(s1.name,s1.gender,s1.score,s1.age,s1.school)
print('*'*50)
print(s2.name,s2.gender,s2.age)
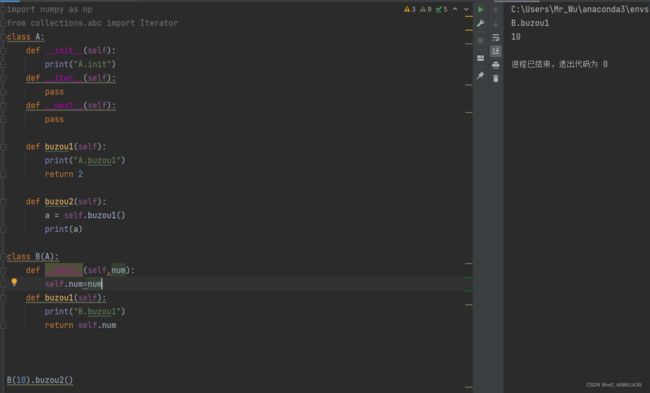
10,还是父类与子类的问题
这个是用来解释当子类调用父类的函数时,如果此父类函数调用的函数有在父类与子类中都有重名函数,用的是哪个
reference
https://www.cnblogs.com/empty16/p/6229538.html
https://blog.csdn.net/sazass/article/details/116668755
https://blog.csdn.net/weixin_42782150/article/details/109315355
https://blog.csdn.net/m0_38063172/article/details/82250865?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163334143316780366591790%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=163334143316780366591790&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-1-82250865.pc_search_result_control_group&utm_term=python+super%E5%87%BD%E6%95%B0&spm=1018.2226.3001.4187