多个文件中的数据处理,输出自己想要是数据
测试数据:
data.txt【需要处理的数据】
China
china
American
Apple
Apples
banana
this
it
aa
bb
aaa
does
mean
f
s
what zz
invalid.txt 【无效的数据】
what
is
it is
aa
does
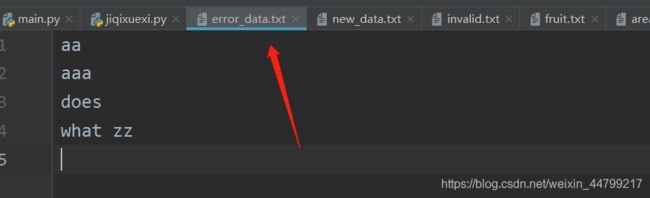
aaa需求一:通过代码实现:凡是需要处理的数据中的任何一行的其中任意一个单词在无效数据中的任何一行中出现过【无效数据中的一行看作一个整体】,则把需要处理的数据的改行给去掉,最后输出想要的数据new_data.txt和排除的数据error_data.txt。
示例代码:
import pandas as pd
# 原始数据
data_base = pd.read_csv('invalid.txt', header=None)
base_list = [i for i in data_base[0]]
# print(base_list)
# 需要处理的数据
data = pd.read_csv('data.txt', header=None)
data_list = [i for i in data[0]]
# print(data_list)
# 获取有效数据的索引
count_list = []
i = 0
for j in data_list:
x_list = [x for x in j.split() if x not in base_list]
if len(x_list) == len(j.split(' ')):
count_list.append(i)
i += 1
# 获取无效数据的列表索引
count_list_2 = []
count_list_all = [i for i in range(len(data_list))]
for i in count_list_all:
if i not in count_list:
count_list_2.append(i)
# print(count_list_2)
# 有效数据生成
for i in count_list:
with open('new_data.txt', 'a') as f:
my_data = f.write(data_list[i] + '\n')
print(data_list[i])
# 无效数据生成
for i in count_list_2:
with open('error_data.txt', 'a') as f:
my_data = f.write(data_list[i] + '\n')
print(data_list[i])
生成结果:

需求二:通过代码实现:凡是需要处理的数据中的任何一行的其中任意一个单词在无效数据中的任何一行中出现过【无效数据中的一行看作一个整体】,则把需要处理的数据的改行给去掉,最后输出想要的数据new_data.txt和排除的数据error_data.txt。然后再从想要是数据new_data.txt中筛选出包含水果词fruit.txt的数据include_fruit_data.txt和再new_data.txt中不包含水果词的数据not_include_fruit_data.txt。最后再从not_include_fruit_data.txt中筛选出包含地域词areas.txt的数据文件include_areas_data.txt和其它剩余的有效数据other_valid_data.txt。
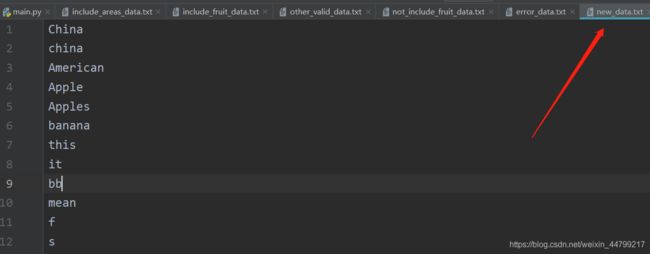
new_data.txt:【上一步代码执行输出的结果】
China
china
American
Apple
Apples
banana
this
bb
mean
f
s
fruit.txt
banana
apple
Appleareas.txt
China
beijing
示例代码:
import pandas as pd
# 原始数据
data_base = pd.read_csv('invalid.txt', header=None)
base_list = [i for i in data_base[0]]
# print(base_list)
# 需要处理的数据
data = pd.read_csv('data.txt', header=None)
data_list = [i for i in data[0]]
# print(data_list)
# 获取有效数据的索引
count_list = []
i = 0
for j in data_list:
x_list = [x for x in j.split() if x not in base_list]
if len(x_list) == len(j.split(' ')):
count_list.append(i)
i += 1
# 获取无效数据的列表索引
count_list_2 = []
count_list_all = [i for i in range(len(data_list))]
for i in count_list_all:
if i not in count_list:
count_list_2.append(i)
# print(count_list_2)
# 有效数据生成
for i in count_list:
with open('new_data.txt', 'a') as f:
my_data = f.write(data_list[i] + '\n')
print(data_list[i])
# 无效数据生成
for i in count_list_2:
with open('error_data.txt', 'a') as f:
my_data = f.write(data_list[i] + '\n')
print(data_list[i])
# 读取有效生成的数据
new_data_base = pd.read_csv('new_data.txt', header=None)
new_base_list = [i for i in new_data_base[0]]
# 读取水果词
fruit_data = pd.read_csv('fruit.txt', header=None)
fruit_data_list = [i for i in fruit_data[0]]
# 获取有效数据中包含水果词的索引
fruit_count_list = []
i = 0
for j in new_base_list:
x_list = [x for x in j.split() if x in fruit_data_list]
if len(x_list) > 0:
fruit_count_list.append(i)
i += 1
# 获取无效数据的列表索引
fruit_count_list_2 = []
fruit_count_list_all = [i for i in range(len(new_base_list))]
for i in fruit_count_list_all:
if i not in fruit_count_list:
fruit_count_list_2.append(i)
# 从有效数据中筛选出包含水果词的数据
for i in fruit_count_list:
with open('include_fruit_data.txt', 'a') as f:
my_data = f.write(new_base_list[i] + '\n')
print(new_base_list[i])
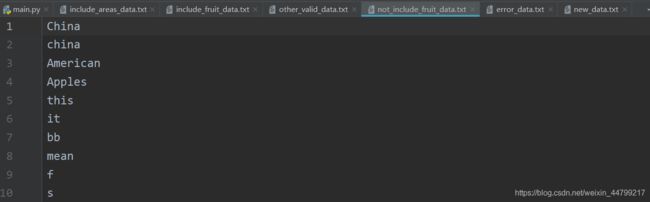
# 从有效数据中筛选出不包含水果词的数据
for i in fruit_count_list_2:
with open('not_include_fruit_data.txt', 'a') as f:
my_data = f.write(new_base_list[i] + '\n')
print(new_base_list[i])
# 读取有效数据中不包含水果词的数据
new_new_data_base = pd.read_csv('not_include_fruit_data.txt', header=None)
new_new_base_list = [i for i in new_new_data_base[0]]
# 读取地域词
areas_data = pd.read_csv('areas.txt', header=None)
areas_data_list = [i for i in areas_data[0]]
# 获取不包含水果词的数据中包含地域词的索引
areas_count_list = []
i = 0
for j in new_new_base_list:
x_list = [x for x in j.split() if x in areas_data_list]
if len(x_list) > 0:
areas_count_list.append(i)
i += 1
# 获取不包含水果词的数据中不包含地域词的索引
areas_count_list_2 = []
areas_count_list_all = [i for i in range(len(new_new_base_list))]
for i in areas_count_list_all:
if i not in areas_count_list:
areas_count_list_2.append(i)
# 获取不包含水果词的数据中包含地域词的数据
for i in areas_count_list:
with open('include_areas_data.txt', 'a') as f:
my_data = f.write(new_new_base_list[i] + '\n')
print(new_new_base_list[i])
# 获取不包含水果词的数据中且不包含地域词的有效数据
for i in areas_count_list_2:
with open('other_valid_data.txt', 'a') as f:
my_data = f.write(new_new_base_list[i] + '\n')
print(new_new_base_list[i])
执行结果:




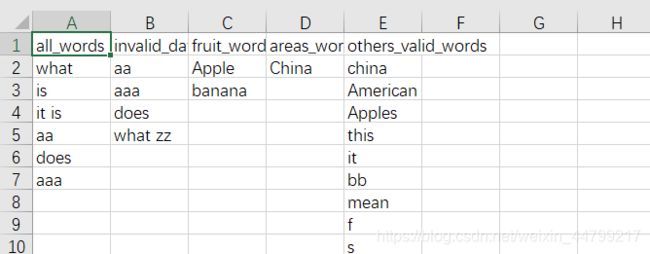
为了让生成的这些数据在一个excel表格中明显的看出来,可以在上面代码的同一个目录下执行下面代码,生成my_data.csv文件
示例代码:
import csv
import pandas as pd
# 0.获取数据
# 原始无效数据
data_base = pd.read_csv('invalid.txt', header=None)
base_list = [i for i in data_base[0]]
# 错误数据
error_data = pd.read_csv('error_data.txt', header=None)
error_list = [i for i in error_data[0]]
# 水果词数据
fruit_data = pd.read_csv('include_fruit_data.txt', header=None)
fruit_list = [i for i in fruit_data[0]]
# 区域词数据
areas_data = pd.read_csv('include_areas_data.txt', header=None)
areas_list = [i for i in areas_data[0]]
# 剩下的其它词
other_data = pd.read_csv('other_valid_data.txt', header=None)
other_data_list = [i for i in other_data[0]]
# 1.创建文件对象
f = open('my_data.csv', 'w', encoding='utf-8', newline="")
# 2.基于文件对象构建csv写入对象
csv_write = csv.writer(f)
# 3.构建列表头
csv_write.writerow(['all_words', 'invalid_data', 'fruit_words', 'areas_words', 'others_valid_words'])
# 4.写入csv文件
data1_len = len(base_list)
data2_len = len(error_list)
data3_len = len(fruit_list)
data4_len = len(areas_list)
data5_len = len(other_data_list)
max_len = max(data1_len, data2_len, data3_len, data4_len, data5_len)
for i in range(max_len):
if data1_len < max_len:
base_list.append(' ')
data1_len += 1
if data2_len < max_len:
error_list.append(' ')
data2_len += 1
if data3_len < max_len:
fruit_list.append(' ')
data3_len += 1
if data4_len < max_len:
areas_list.append(' ')
data4_len += 1
if data5_len < max_len:
other_data_list.append(' ')
data5_len += 1
csv_write.writerow([base_list[i], error_list[i], fruit_list[i], areas_list[i], other_data_list[i]])
# 5.关闭文件
f.close()
执行效果: