今日 Paper | 新闻推荐系统;多路编码;知识增强型预训练模型等
2020-01-21 05:41:48
目录
-
用多尺度自监督表征提高小样本学习的表现
-
详细了解如何设计和使用一个基于深度学习的新闻推荐系统
-
几何GCN
-
提升鲁棒性的多路编码
-
常识故事生成的知识增强型预训练模型
用多尺度自监督表征提高小样本学习的表现
论文名称:Few-shot Learning with Multi-scale Self-supervision
作者:Zhang Hongguang /Torr Philip H. S. /Koniusz Piotr
发表时间:2020/1/6
论文链接:https://paper.yanxishe.com/review/9112
从深度学习流行以来,需要大量数据的这一特点就经常被指责,更有人指出人类的智慧只需要几个甚至一个样本就可以学会某个任务或者某种概念 —— 这就是小样本学习,有许多研究人员就在这个方向做着努力。近期,“二阶池化”(second-order pooling)的方法在小样本学习中发挥了很好的效果,主要是因为其中的聚合操作不需要对CNN网络做修改就可以处理各种不同的图像分辨率,同时还能找到有代表性的共同特征。
不过,学习每张图像的时候只使用一种分辨率不是最优的方法(即便整个数据集中所有图像的分辨率都各自不同),因为每张图像中的内容相比于整张图像的粒度粗细不是固定不变的,实际上这受到内容本身和图像标签的共同影响,比如,常见的大类物体的分类更依赖整体外观形状,而细粒度的物体分类更多依赖图像中局部的纹理模式。也所以,图像去模糊、超分辨率、目标识别等任务中都已经引入了多尺度表征的概念,用来更好地处理不同分类粒度。
这篇论文里作者们就尝试了在小样本学习中引入多尺度表征。他们主要需要克服的困难是,要避免多尺度表征把标准方法的使用变得过于复杂。他们的方法是,在二阶池化的属性的基础上设计一个新型的多尺度关系网络,用来在小样本学习中预测图像关系。作者们也设计了一系列方法优化模型的表现。最终,他们在几个小样本学习数据集上都刷新了最好成绩。



详细了解如何设计和使用一个基于深度学习的新闻推荐系统
论文名称:CHAMELEON: A Deep Learning Meta-Architecture for News Recommender Systems [Phd. Thesis]
作者:Moreira Gabriel de Souza Pereira
发表时间:2019/12/29
论文链接:https://paper.yanxishe.com/review/9113
这是一篇来自巴西航空理工学院的博士毕业论文,主要讨论了基于深度学习的新闻推荐系统的设计方法 —— 不是讨论某个具体的架构,而是讨论如何设计架构,也就是“元架构”。
新闻推荐系统对如今的许多媒体平台来说都是不可或缺的,给用户推荐他们喜欢的内容(以及广告),能让他们获得更好的浏览体验,从商业角度也能提高用户活跃度和平均使用时长。
这篇论文作为博士毕业论文,对新闻推荐系统这个子领域做了详细的研究讨论,包括介绍推荐系统的背景、比较现有的新闻推荐系统、介绍深度学习应用于推荐系统中的基础知识等。作者的主要研究成果是,可以根据具体的使用需求设计基于深度学习的新闻推荐系统的“元架构”(系统设计方法)CHAMELEON。它含有模块化的推理结构,可以具体选用不同的神经网络基础组件。作者详细介绍了CHAMELEON的特点和应用思路,也包括了针对冷启动情境的解决方案。
对于感兴趣详细理解这个任务的研究人员,以及对于正在设计、打算设计推荐系统的开发人员,这篇论文都具有极高的参考价值。


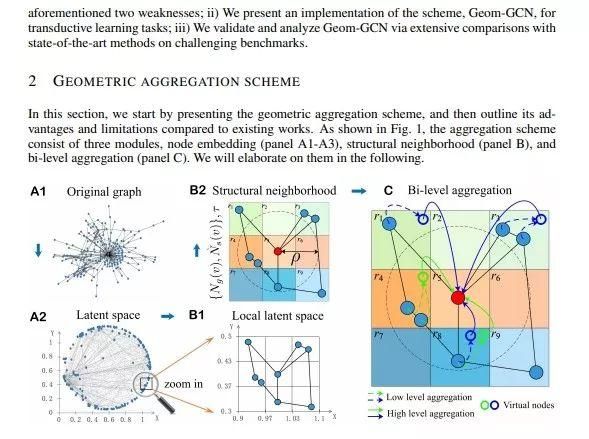
几何GCN
论文名称:Geom-GCN: Geometric Graph Convolutional Networks
作者:Hongbin Pei /Bingzhe Wei /Kevin Chen-Chuan Chang /Yu Lei /Bo Yang
发表时间:2020/1/1
论文链接:https://paper.yanxishe.com/review/8990
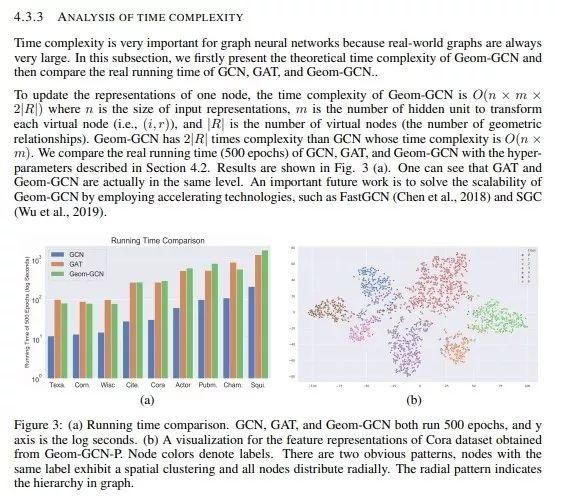
本文入选了ICLRL2020的oral是图神经网络的最新进展。作者将原始图通过graph embedding技术映射到一个隐空间,在隐空间基于相似度建立了新的图。这样每个节点的邻居就可以分为原始图和相似度图,相似度上的邻居可能是原始图邻居的k阶邻居,这样可以保持高阶的节点相似性。另一方面,作者又设计了可以感知节点间集合关系的聚合器,可以在聚合邻居的时候考虑节点之间的集合关系。综上,Geom-GCN解决了GNN的两个基础性问题。实验表明,本文的所提出的算法可以大幅度超越现有的GCN和GAT。

提升鲁棒性的多路编码
论文名称:Multi-way Encoding for Robustness
作者:Kim Donghyun /Bargal Sarah Adel /Zhang Jianming /Sclaroff Stan
发表时间:2019/6/5
论文链接:https://paper.yanxishe.com/review/9214
这篇论文被WACV 2020接收,考虑的是通过编码来提升模型鲁棒性的问题。
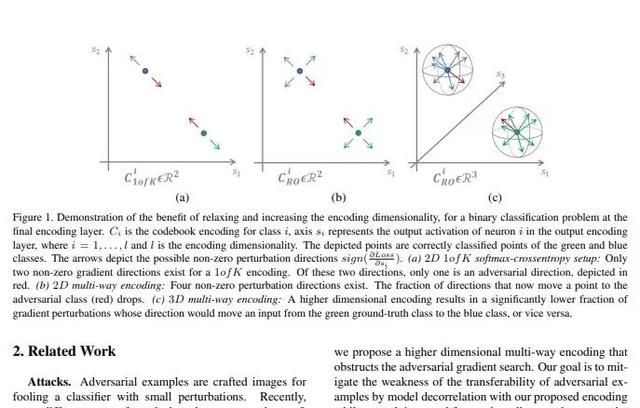
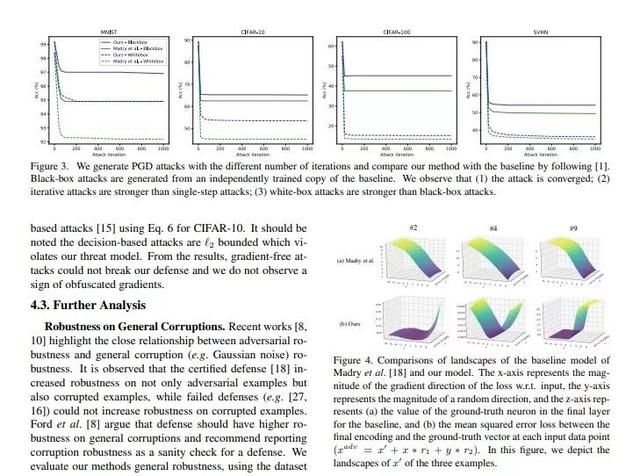
深度模型已经在许多计算机视觉任务上(例如图像分类和目标检测)上取得了巨大的成功,但是这些模型容易受到对抗性样本的攻击。这篇论文证明了One-Hot编码是导致这种情况的直接原因,并提出了一个新的方法,通过利用不同的输出编码和多路编码,可以对源模型和目标模型进行解相关操作,从而使目标模型更加安全。这种新提出的方法使攻击者更难以找到有用的梯度来进行对抗攻击。在MNIST,CIFAR-10,CIFAR-100和SVHN数据集上的黑盒和白盒攻击中,这篇论文提出的方法均提升了模型的鲁棒性。

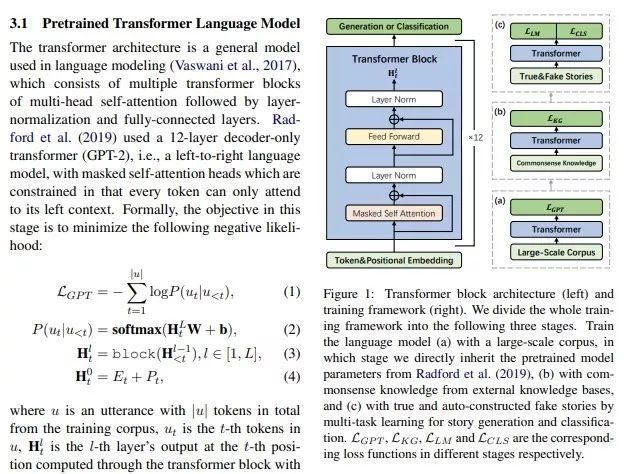
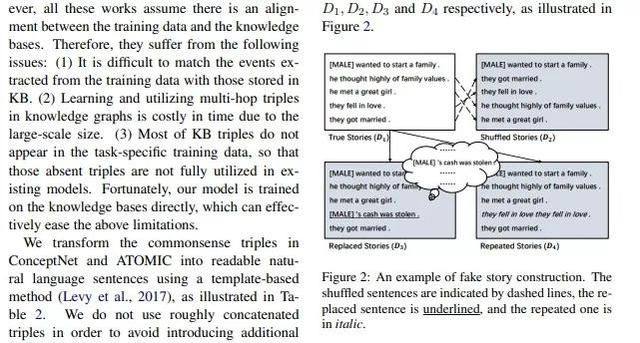
常识故事生成的知识增强型预训练模型
论文名称:A Knowledge-Enhanced Pretraining Model for Commonsense Story Generation
作者:Guan Jian /Huang Fei /Zhao Zhihao /Zhu Xiaoyan /Huang Minlie
发表时间:2020/1/15
论文链接:https://paper.yanxishe.com/review/9217
这篇论文来自于清华和北航,已经被Transactions of the Association for Computational Linguistics接收,考虑的是故事生成的问题。
故事生成指的是从一个输入上下文中生成出一个合理的故事。现有的神经语言生成模型,例如GPT-2,在文本流畅度和局部关联性方面取得了进步,但是仍然会在生成的故事里出现生成重复、逻辑冲突、缺乏长程关联等缺陷。这篇论文认为这些缺陷是由于缺乏相关常识和无法理解因果关系,进而无法合理规划正常时序里的实体和事件顺序导致的。为此这篇论文设计了一种知识增强的预训练模型,从外部知识库获取的常识来生成合理的故事。为了进一步捕获一个合理故事里句子间的因果和时序依赖关系,这篇论文使用多任务学习方法,将一个可以辨认真实和虚假故事的判别目标函数融入了微调过程。自动化和人工的评估表明这篇论文提出的方法在逻辑和全局关联方面优于当前的最佳基准。