杂七杂八知识点的摸索
文章目录
-
- 一、tcp/ip协议栈
-
- 1.1 OSI七层模型
- 1.2 TCP timewait太多是什么原因
- 1.3 TCP建立详细过程和UDP区别
- 1.4 介绍一下tcp包头有什么内容
- 1.5 TCP 三次丢包了怎么办,过多久重传
- 1.6 TCP 4次为什么要4次关闭
- 1.7 TCP 4次关闭服务端先关闭好还是客户端先关闭好
- 1.8 TCP UDP 区别分别用在那?举例说出应用到 TCP UDP 的协议
- 1.9 TCP 如何实现可靠传输的?——超时重传+确认机制
- 1.10 TCP滑动窗口什么情况下会变化,怎么变
- 1.11 HTTP协议与TCP协议的关系
- 1.12 HTTP和HTTPS的区别
- 1.13 介绍HTTPS加密原理
- 1.14 如何加快TCP socket连接的回收
- 二、网络相关
-
- 2.1 五层模型
- 2.2 TCP三次握手四次挥手
- 2.3 TCP和UDP区别
- 2.4 路由器和交换机区别
- 2.5 交换机性能优化
- 2.6 四次挥手为什么有timewait
- 2.7 HTTP协议
- 2.8 交换机与路由器的区别,各自的应用场景
- 三、操作系统原理
-
- 3.1 硬盘接口类型
-
- 3.1.1 IDE
- 3.1.2 SATA
- 3.1.3 SCSI
- 3.1.4 SAS
- 3.2 中断机制
-
- 3.2.1 中断类型
- 3.2.2 中断数据处理结构
- 3.2.3 Linux中断机制
- 3.3 进程和线程的关系,父进程和子进程的关系
- 3.4 线程和进程的区别
- 四、linux基础知识
-
- 4.1 tr命令和sar命令
- 4.2 管道符和重定向的区别
- 4.3 cache和buffer区别
- 4.4 Linux怎么设置开机自启动某个脚本
-
- 4.4.1 第一种 chkconfig管理
- 4.4.2 第二种 修改/etc/rc.local
- 4.5 kill和kill-9区别
- 4.6 写一个脚本来判断文件是否存在
- 4.7 ping一个地址的实现过程,协议
- 4.8 用脚本实现最简单的两个数相除(精确到小数点后四位)
- 4.9 权限体系,755,一些特殊文件为什么是600.400
- 4.10 查看内存的命令,内存占用最大的进程,怎么看这个进程调用了哪些文件,以及查看核数
-
- 4.10.1 查看内存的命令
- 4.10.2 内存占用最大的进程
- 4.10.3 看这个进程调用了哪些文件
- 4.10.4 查看核数
- 4.11 tcpdump指定源端口,过滤8000-9000端口
- 4.12 几种下载安装的步骤,报错有哪些情况,怎么解决
-
- 4.12.1 yum安装
- 4.12.2 编译安装
- 4.12.3 二进制安装
- 4.12.4 三种安装方法优缺点比较
- 4.12.5 常见错误
- 4.13 iptables的操作,过滤一个IP,与firewall的区别,了解ipset
-
- 4.13.1 iptables过滤一个IP
- 4.13.2 查看output策略
- 4.13.3 建立自定义链
- 4.13.4 清理防火墙选项
- 4.13.5 7以上防火墙命令
- 4.13.6 iptables与firewall的区别
- 4.13.7 ipset
- 4.14 查看网卡信息,MTU与MSS的区别
-
- 4.14.1 查看网卡信息
- 4.14.2 MTU
- 4.14.3 MSS
- 4.14.4 MTU和MSS的区别
- 4.15 cpu的使用率是怎样计算的,120%是什么意思,一个什么样的进程能让他达到200%
- 4.16 查看系统io状态,iostat里面的io百分比是怎么算的
-
- 4.16.1 查看系统io状态
- 4.16.2 iostat里面的io百分比
- 4.17 运行一个shell脚本怎样调试,怎样看到执行的整个过程,中间有一句错了后面还会不会执行,怎样解决
-
- 4.17.1 脚本调试
- 4.17.2 调试器bashdb
- 4.18 free
-
- 4.18.1 free
- 4.18.2 /proc/meminfo 文件
- 4.19 一个脚本重定向到另一个文件,另一个文件却是空的是怎么回事(排除权限问题)
- 4.20 shell重定向有几种方式,标准错误输出,一条命令不要他的输出与标准错误输出怎么做
-
- 4.20.1 shell重定向
- 4.20.2 >/dev/null 2>&1 和 2>&1 >/dev/null区别
- 4.21 top显示内容,第一行最后三个的含义,负载是什么意思,为什么不能超过核心数,是什么原理
- 4.22 查看磁盘读写的MB用什么参数,查看tps用什么参数
- 4.23 linux socket建立和关闭的原理
- 4.24 如何知道系统block大小
- 4.25 proc伪文件系统
- 4.26 LVM逻辑卷
-
- 4.26.1 逻辑卷优点
- 4.26.2 创建逻辑卷过程
- 4.26.3 扩大缩小逻辑卷/卷组
- 4.26.4 备份逻辑卷
- 4.26.5 /扩容的方法
- 4.27 MBR的作用
- 4.28 /var/log目录下有什么,日志分别是哪些服务的,日志里面的内容是什么
-
- 4.28.1 /var/log/目录
- 4.28.2 日志有哪些服务
- 4.28.3 日志里面的内容
- 4.29 文件系统中文件查找快的原因
-
- 4.29.1 查找文件
- 4.29.2 查找快的原因(可以从最底层的磁盘讲起)
- 4.30 raid0与raid1的区别,raid5一块盘坏了会怎么办,具体原理
-
- 4.30.1 raid0与raid1的区别
- 4.30.2 raid5一块盘坏,怎么处理
- 4.30.3 软raid
- 4.31 一条定时任务没有执行,有几种可能的原因
- 4.32 网卡的配置文件在哪里
- 4.33 怎样查看占用80端口的进程
- 4.34 怎样查看系统的性能
- 4.35 怎样看磁盘的io
- 4.36 awk怎样把最后一列拎出来
- 4.37 介绍一个w,uptime,iostat,top,ps
- 4.38 ab web服务器性能测试
- 4.39 查看某服务是否打开
- 4.40 一次性关闭某服务的所有进程
- 4.41 查看进程的命令
- 4.42 Linux杀死僵尸进程
- 4.43 文本处理/替换
-
- 4.43.1 awk文本处理
- 4.43.2 sed文本替换
- 4.43.3 用多种方法获取一个特殊字段并计数
- 4.44 系统启动流程
-
- 4.44.1 加电检查了那些外围设备,检查的顺序
- 4.44.2 bios存在的意义
- 4.44.3 /boot分区的内容
- 4.44.4 如何找到grub
- 4.44.5 grub和grub2的区别
- 4.44.6 initramfs文件的作用
- 4.44.7 grub的各个阶段功能
- 4.44.8 内核是什么,功能,如何修改内核参数
- 4.45 linux如何获取对方的arp(arping)
- 4.46 linux绑定双网卡,数据怎么走
- 4.47 文件权限linux 发行版本
-
- 4.47.1 文件权限
- 4.47.2 发行版本
- 4.48 常见的http状态码
- 4.49 netstat常见的选项
- 4.50 维护一个系统的安全有哪几方面
- 4.51 linux常用的分区格式
- 4.52 PYTHON
-
- 4.52.1 python的内存回收机制
- 4.52.2 python中+=
- 4.52.3 元组与列表的区别
- 4.52.4 python中有哪些复制的方式
- 4.52.5 Django的模块使用情况
- 4.52.6 Python和shell的区别
- 4.52.7 python的常见数据类型
- 五、数据库知识
-
- 5.1 部署数据库的整一个流程
-
- 5.1.1 安装
- 5.1.2 部署多实例
- 5.1.3 主从复制
- 5.2 数据库大数据类型
- 5.3 数据库存储引擎
- 5.4 索引
- 5.5 SQL查询语句的优化
- 5.6 数据库触发器
- 5.7 当创建好一个数据库,都生成了哪些文件,这些文件的本质是什么
- 5.8 MySQL主从不一致出现报错要怎么解决,简历主从的命令是什么
-
- 5.8.1 slave运行过慢不能与master同步,也就是MySQL数据库主从同步延迟
- 5.8.2 slave同步状态中出现Slave_IO_Running: NO
- 5.8.3 slave同步状态中出现Slave_IO_Running: Connecting
- 5.8.4 slave中继日志relay-log损坏
- 5.8.5 slave连接超时且重新连接频繁
- 5.8.6 在master更新一条记录,而slave却找不到
- 5.8.7 mysql主从同步(跨机房情况)不一致问题
- 5.9 查看Mysql发现查询特别慢,可能的原因,对于慢查询,你的分析思路
-
- 5.9.1 查询速度慢的原因
- 5.9.2 查询优化
- 5.9.3 查看
- 六、服务器知识
-
- 6.1 Docker的原理
- 6.2 CDN
-
- 6.2.1 CDN概念
- 6.2.2 CDN架构
- 6.3 LVS(Linux Virtual Server)
-
- 6.3.1 lvs架构
- 6.3.2 工作原理
- 6.3.3 工作模式
- 6.3.4 做高可用
- 6.4 Apache服务器怎么搭建, IO复用模型, select epoll
-
- 6.4.1 配置apache服务器
- 6.4.2 nginx架构
- 6.4.3 IO复用模型
- 6.5 公钥私钥原理,公钥文件存放哪里,权限是多少
-
-
- 6.5.1 对称加密算法原理
- 6.5.2 非对称加密算法原理
- 6.5.3 公钥文件以及权限
-
- 6.6 了解云计算
-
- 6.6.1 云计算分层
- 6.7 DNS的解析过程
-
- 6.7.1 实际查询过程分析
- 6.7.2 解析顺序
- 6.7.3 DNS服务器查找根域时丢包怎么办
- 6.8 为什么nginx支持高并发?
-
- 6.8.1 搭建静态资源web服务器
- 6.8.2 为什么nginx支持高并发
- 6.8.3 动态网页和静态网页有什么区别?
- 6.8.4 介绍一下nginx的日志
- 6.8.5 nginx的虚拟主机
- 6.8.6 nginx如何部署django
- 6.9 ansible的原理和使用方法
-
- 6.9.1 原理
- 6.9.2 使用方法
- 6.9.3 SaltStack、Ansible、Puppet比较
- 6.10 redis
-
- 6.10.1 redis的作用
- 6.10.2 redis哨兵怎么做
- 6.10.3 redis数据库存放文件的地方
- 6.10.4 主从复制的过程
- 6.10.5 Redis常见问题和解决办法梳理
- 6.10.6 RDB和AOF持久化对比
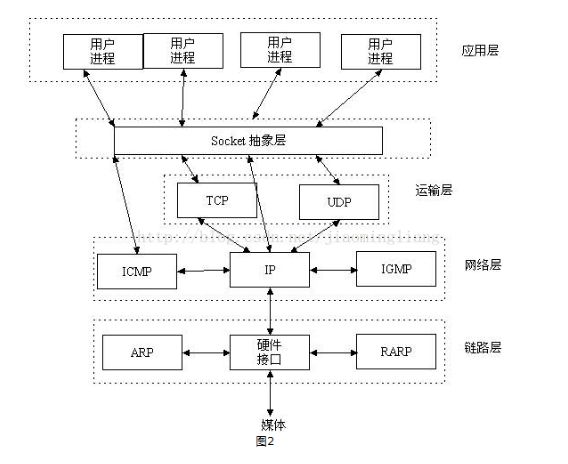
一、tcp/ip协议栈
1.1 OSI七层模型
OSI七层模型:https://blog.csdn.net/yaopeng_2005/article/details/7064869
1.2 TCP timewait太多是什么原因
TCP timewait:https://www.cnblogs.com/softidea/p/5741192.html
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接。这个场景下会出现大量socket处于TIME_WAIT状态。
net.ipv4.tcp_tw_reuse=1 #表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;该文件表示是否允许重新应用处于TIME-WAIT状态的socket用于新的TCP连接(这个对快速重启动某些服务,而启动后提示端口已经被使用的情形非常有帮助)
net.ipv4.tcp_tw_recycle=1 #表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_timestamps #开启时,net.ipv4.tcp_tw_recycle开启才能生效,原因可以参考以下代码
timewait过多问题:https://www.cnblogs.com/dadonggg/p/8778318.html
1.3 TCP建立详细过程和UDP区别
TCP建立详细过程:https://blog.csdn.net/caoyan_12727/article/details/52081269
TCP和UDP区别:https://blog.csdn.net/weixin_46108954/article/details/104488107
1.4 介绍一下tcp包头有什么内容
tcp包头:https://blog.51cto.com/13854765/2163296
1.5 TCP 三次丢包了怎么办,过多久重传
主要的考虑还是要区分包的丢失是由于链路故障还是乱序等其他因素引发。两次duplicated ACK时很可能是乱序造成的!三次duplicated ACK时很可能是丢包造成的!
TCP 快速重传为什么是三次冗余ack:https://blog.csdn.net/u010202588/article/details/54563648
2MSL
1.6 TCP 4次为什么要4次关闭
四次挥手:https://blog.csdn.net/weixin_46108954/article/details/104687671
1.7 TCP 4次关闭服务端先关闭好还是客户端先关闭好
服务端先关闭,这段时间服务器端绑定的端口号被占用了,套接字不会释放。
客户端继续写的话,会触发SIGPIPE信号,操作系统会强制关闭客户端。
服务器先关闭,客户端不关闭的情况分析:https://blog.csdn.net/qq_37941471/article/details/82054920
为什么在四次挥手的过程中一般都是客户端先发起:https://blog.csdn.net/daputao_net/article/details/81255499
1.8 TCP UDP 区别分别用在那?举例说出应用到 TCP UDP 的协议
基于TCP的应用层协议有:SMTP、TELNET、HTTP、FTP
基于UDP的应用层协议:DNS、TFTP(简单文件传输协议)、RIP(路由选择协议)、DHCP、BOOTP(是DHCP的前身)、IGMP(Internet组管理协议)
1.9 TCP 如何实现可靠传输的?——超时重传+确认机制
通过累计确认、超时重传、拥塞控制三大模块保证
实现可靠传输:https://blog.csdn.net/shawjan/article/details/45117945
1.10 TCP滑动窗口什么情况下会变化,怎么变
滑动窗口实现有两个作用:
1.B端来不及处理接收数据(控制不同速率主机间的同步),这时,A通过B端通知的接收窗口而减缓数据的发送。
2.B端来得及处理接收数据,但是在A与B之间某处如C,使得AB之间的整体带宽性能较差,此时,A端根据拥塞处理策略(慢启动,加倍递减和缓慢增加)来更新窗口,以决定数据的发送。
条件判定:
1.cwnd < ssthresh, 继续使用慢开始算法;
2.cwnd > ssthresh,停止使用慢开始算法,改用拥塞避免算法;
3.cwnd = ssthresh,既可以使用慢开始算法,也可以使用拥塞避免算法;
TCP滑动窗口:https://www.cnblogs.com/alifpga/p/7675850.html
1.11 HTTP协议与TCP协议的关系
TCP协议是传输层协议,主要解决数据如何在网络中传输
HTTP是应用层协议,主要解决如何包装数据。
HTTP协议与TCP协议的关系:https://blog.csdn.net/weixin_46108954/article/details/104704231
1.12 HTTP和HTTPS的区别
HTTP + 加密 + 认证 + 完整性保护 = HTTPS
1.https协议需要到CA (Certificate Authority,证书颁发机构)申请证书,一般免费证书较少,因而需要一定费用。(原来网易官网是http,而网易邮箱是https。)
2.http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3.http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4.http的连接很简单,是无状态的。Https协议是由SSL+Http协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。(无状态的意思是其数据包的发送、传输和接收都是相互独立的。无连接的意思是指通信双方都不长久的维持对方的任何信息。)
HTTP和HTTPS的区别 :https://blog.csdn.net/qq_38289815/article/details/80969419
数字签名、数字证书与HTTPS是什么关系:https://www.zhihu.com/question/52493697
TLS,SSL:https://blog.csdn.net/kobejayandy/article/details/52433660
1.13 介绍HTTPS加密原理
非对称加密算法:RSA,DSA/DSS
对称加密算法:AES,RC4,3DES
HASH算法:MD5,SHA1,SHA256
HTTPS加密原理与算法详解:https://www.wosign.com/News/news_2018082801.htm
1.14 如何加快TCP socket连接的回收
/etc/sysctl.conf文件
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_timestamp = 1
net.ipv4.tcp_syncookies = 1表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout修改系統默认的TIMEOUT时间
开启tcp_timestamp是开启tcp_tw_recycle,tcp_tw_reuse和tcp_timestamp的前提条件。
但是在nat模式下,不用将tcp_tw_recycle和tcp_timestamp同时开启,这会造成tcp超时引发故障。
二、网络相关
2.1 五层模型
五层模型:https://www.cnblogs.com/bqwzx/p/11053778.html
应用层
传输层
网络层
数据链路层
物理层
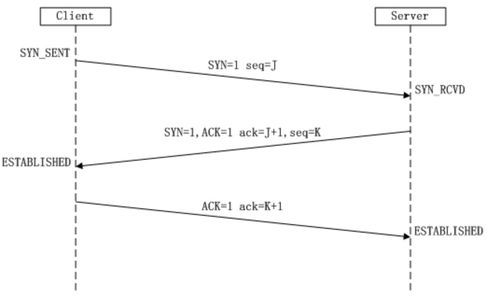
2.2 TCP三次握手四次挥手
三次握手
四次挥手
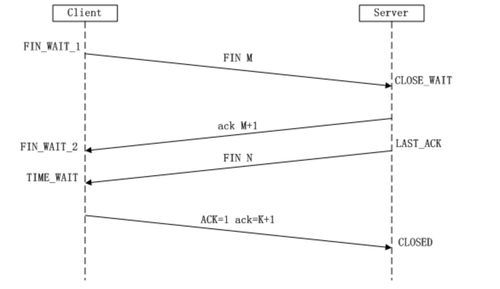
2.3 TCP和UDP区别
TCP和UDP区别 :https://blog.csdn.net/weixin_46108954/article/details/104488107
1、连接、无连接
2、可靠性
3、有序性
4、数据边界
5、速度
6、重量级、轻量级
7、头大小
8、拥塞或流控制
9、用法和应用
2.4 路由器和交换机区别
路由器和交换机:https://blog.csdn.net/qq_43624679/article/details/106238729
三层交换机和路由器:https://www.cnblogs.com/tianyao2020/p/12527817.html
路由器的工作原理
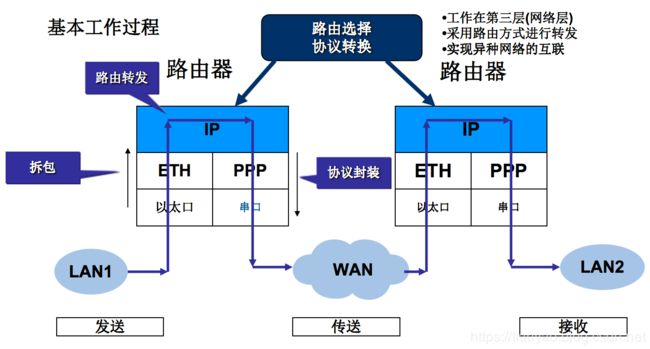
信息传输:路由转发
一个数据包进入路由器时,路由器先对其解封装到数据链路层以查看它的目标mac地址,然后再根据该目标mac地址判断是否进行下一步操作,具体分为以下:
①广播:解封装到第三层;
②组播:查看自己是否在组内,是,继续向上解封装,否,丢包;
③单播:判断该目标mac地址是否为数据包进入自身的端口的mac地址,是,继续向上解封装,否,丢包。
此时来到网络层,查看数据包的目标IP地址,再根据该目标IP地址判断是否进行下一步操作,具体分为以下:
①广播:继续向上解封装;
②组播:查看自己是否在组内,是,继续向上解封装,否,丢包;
③单播:查看目标IP地址是否为自己,是,继续向上解封装,否,路由器将查看本地路由表TCAM表进行下一步转发。
连接不同的网络:p2p、BMA、NBMA
路由器的另外一个功能是能互联不同的网络,具体的网络类型如下:
①p2p:点到点网络,仅允许存在两个物理接口;
②BMA:广播型多路访问,支持多路访问,可以洪泛;
③NBMA:非广播型多路访问,支持多路访问,但只能单播。
二层交换机的工作原理:
概括为:基于源mac地址学习,基于目标mac地址转发
即数据帧进入交换机时,首先查看源mac,交换机会将对应接口的VLAN ID+MAC地址+接口编号进行hash运算后的二进制记录到本地cam表中,然后查看数据包的目标mac地址,若目标mac地址存在本地的MAC地址表,则直接向其转发数据帧,否则进行洪泛,向除进入接口外的其他所有接口转发数据帧。
三层交换机的工作原理:
三层交换机是具有路由转发功能的二层交换机。
工作原理:当数据帧进入三层交换机后:
①查看源mac,生成cam表;
②再查看目标mac,此时目标mac
③查看目标IP地址,行为与上文路由器查看IP地址相同,不再赘述。
分为以下三种情况:
①广播:洪泛,向上解封装;
②组播:若交换机在该组,洪泛且向上解封装,否则丢包;
③单播:查看目标mac地址是否为在本地,是,继续向上解封装,否,基于cam表转发。
2.5 交换机性能优化
交换机性能:https://blog.51cto.com/774579/1412032
1、对于不变化的MAC地址和交换机端口,我们可以将MAC地址设置成静态的,这样,交换机一开机就知道恩,张三对应的是1号端口,李四对应的是2号端口
2、对于有变化但不是经常变化的MAC地址,我们可以设置老化时间,将老化时间设立的长一点,这样子交换机也就知道说,大家都是熟人,我就少喊两嗓子。
3、交换机的参数里面有两个重要的参数,那就是背板带宽和MAC地址表深度。个人感觉背板带宽比较重要。
2.6 四次挥手为什么有timewait
timewait :https://blog.csdn.net/u014053368/article/details/23117809
TIME_WAIT状态由两个存在的理由。
(1)可靠的实现TCP全双工链接的终止。
这是因为虽然双方都同意关闭连接了,而且握手的4个报文也都协调和发送完毕,按理可以直接回到CLOSED状态(就好比从SYN_SEND状态到ESTABLISH状态那样);但是因为我们必须要假想网络是不可靠的,你无法保证你最后发送的ACK报文会一定被对方收到,因此对方处于LAST_ACK状态下的SOCKET可能会因为超时未收到ACK报文,而重发FIN报文,所以这个TIME_WAIT状态的作用就是用来重发可能丢失的ACK报文。
(2)允许老的重复的分节在网络中消逝。
假设在12.106.32.254的1500端口和206.168.1.112.219的21端口之间有一个TCP连接。我们关闭这个链接,过一段时间后在相同的IP地址和端口建立另一个连接。后一个链接成为前一个的化身。因为它们的IP地址和端口号都相同。TCP必须防止来自某一个连接的老的重复分组在连接已经终止后再现,从而被误解成属于同一链接的某一个某一个新的化身。为做到这一点,TCP将不给处于TIME_WAIT状态的链接发起新的化身。既然TIME_WAIT状态的持续时间是MSL的2倍,这就足以让某个方向上的分组最多存活msl秒即被丢弃,另一个方向上的应答最多存活msl秒也被丢弃。通过实施这个规则,我们就能保证每成功建立一个TCP连接时。来自该链接先前化身的重复分组都已经在网络中消逝了。
2.7 HTTP协议
HTTP是应用层协议,主要解决如何包装数据。
2.8 交换机与路由器的区别,各自的应用场景
应用场景
交换机一般在已本地网中扩展用的,路由用来内网和外网的连接。
三、操作系统原理
3.1 硬盘接口类型
3.1.1 IDE
IDE接口的硬盘比较老款,其最大的表现在于数据线是一条像布条的东西。
IDE硬盘的传输模式有以下三种:PIO(Programmed I/O)模式,DMA(Driect Memory Access)模式,Ultra DMA(简称UDMA)模式。
PIO模式下的硬盘数据传输率在3MB/S到16.6MB/S不等;DMA(Direct Memory Access)模式分为Single-Word DMA及Multi-Word DMA两种,最高数据传输率分别为8.33MB/s和16.66MB/s;Ultra DMA模式随着科技的发展,传输速度已经高达100MB/S。
3.1.2 SATA
SATA接口硬盘
这种接口的硬盘又叫串口硬盘,是目前电脑硬盘的主流硬盘。它具备了更强的纠错能力,与以往相比其最大的区别在于能对传输指令(不仅仅是数据)进行检查,如果发现错误会自动矫正,这在很大程度上提高了数据传输的可靠性。
3.1.3 SCSI
这种接口并不是专门为硬盘设计的接口,是一种广泛应用于小型机上的高速数据传输技术。优点是应用范围广、多任务、带宽大、CPU占用率低,支持热插拔,不过缺点就是价格偏高。也因为如此SCSI接口的硬盘多用于服务器中而非个人。
3.1.4 SAS
SAS接口硬盘的一般用在服务器上面
可以看作是新一代的SCSI技术,其接口技术可以向下兼容SATA,所以SAS驱动器和SATA驱动器可以同时存在于一个存储系统之中。
3.2 中断机制
linux内核中断:https://blog.csdn.net/weixin_42092278/article/details/81989449
中断是指在CPU正常运行期间,由于内外部事件或由程序预先安排的事件引起的CPU暂时停止正在运行的程序,转而为该内部或外部事件或预先安排的事件服务的程序中去,服务完毕后再返回去继续运行被暂时中断的程序。
3.2.1 中断类型
同步中断由CPU本身产生,又称为内部中断。这里同步是指中断请求信号与代码指令之间的同步执行,在一条指令执行完毕后,CPU才能进行中断,不能在执行期间。所以也称为异常(exception)。
异步中断是由外部硬件设备产生,又称为外部中断,与同步中断相反,异步中断可在任何时间产生,包括指令执行期间,所以也被称为中断(interrupt)。
异常又可分为可屏蔽中断(Maskable interrupt)和非屏蔽中断(Nomaskable interrupt)。而中断可分为故障(fault)、陷阱(trap)、终止(abort)三类。
从广义上讲,中断又可分为四类:中断、故障、陷阱、终止。
| 类别 | 原因 | 异步/同步 | 返回行为 |
|---|---|---|---|
| 中断 | 来自I/O设备的信号 | 异步 | 总是返回到下一条指令 |
| 陷阱 | 有意的异常 | 同步 | 总是返回到下一条指令 |
| 故障 | 潜在可恢复的错误 | 同步 | 返回到当前指令 |
| 终止 | 不可恢复的错误 | 同步 | 不会返回 |
3.2.2 中断数据处理结构
Linux内核中处理中断主要有三个数据结构,irq_desc,irq_chip和irqaction。
-
irq_desc用于描述IRQ线的属性与状态,被称为中断描述符。
-
irq_chip用于描述不同类型的中断控制器。
-
在\include\linux\ interrupt.h中定义了 irqaction用来描述特定设备所产生的中断描述符。
3.2.3 Linux中断机制
Linux中断机制由三部分组成:
- 中断子系统初始化:内核自身初始化过程中对中断处理机制初始化,例如中断的数据结构以及中断请求等。
- 中断或异常处理:中断整体处理过程。
- 中断API:为设备驱动提供API,例如注册,释放和激活等。
注:IRQ线资源非常宝贵,我们在使用时必须先注册,不使用时必须释放IRQ资源。
ARM架构:https://blog.csdn.net/weixin_42092278/article/details/104491507
3.3 进程和线程的关系,父进程和子进程的关系
1、父子进程之间的关系
关于资源:子进程得到的是除了代码段是与父进程共享的意外,其他所有的都是得到父进程的一个副本,子进程的所有资源都继承父进程,得到父进程资源的副本,既然为副本,也就是说,二者并不共享地址空间。两个是单独的进程,继承了以后二者就没有什么关联了,子进程单独运行。(采用写时复制技术)
关于文件描述符:继承父进程的文件描述符时,相当于调用了dup函数,父子进程共享文件表项,即共同操作同一个文件,一个进程修改了文件,另一个进程也知道此文件被修改了。
2、线程与进程之间的关系
一个进程的线程之间共享由进程获得的资源,但线程拥有属于自己的一小部分资源,就是栈空间,保存其运行状态和局部自动变量的。堆是堆,栈是栈。栈可以叫做:堆栈,栈,栈和堆栈指的都是stack,只是叫法不一样。而堆就只能叫做堆。在线程中new出来的空间占的是进程的资源,也就是说是占用的堆资源(heap)。
3.4 线程和进程的区别
线程和进程的区别 :https://www.zhihu.com/question/25532384
进程是资源分配的最小单位,线程是CPU调度的最小单位
做个简单的比喻:进程=火车,线程=车厢
- 线程在进程下行进(单纯的车厢无法运行)
- 一个进程可以包含多个线程(一辆火车可以有多个车厢)
- 不同进程间数据很难共享(一辆火车上的乘客很难换到另外一辆火车,比如站点换乘)
- 同一进程下不同线程间数据很易共享(A车厢换到B车厢很容易)
- 进程要比线程消耗更多的计算机资源(采用多列火车相比多个车厢更耗资源)
- 进程间不会相互影响,一个线程挂掉将导致整个进程挂掉(一列火车不会影响到另外一列火车,但是如果一列火车上中间的一节车厢着火了,将影响到所有车厢)
- 进程可以拓展到多机,进程最多适合多核(不同火车可以开在多个轨道上,同一火车的车厢不能在行进的不同的轨道上)
- 进程使用的内存地址可以上锁,即一个线程使用某些共享内存时,其他线程必须等它结束,才能使用这一块内存。(比如火车上的洗手间)-“互斥锁”
- 进程使用的内存地址可以限定使用量(比如火车上的餐厅,最多只允许多少人进入,如果满了需要在门口等,等有人出来了才能进去)-“信号量”
四、linux基础知识
4.1 tr命令和sar命令
tr命令可以对来自标准输入的字符进行替换、压缩和删除。
tr命令:https://www.cnblogs.com/bingguoguo/articles/9188703.html
sar命令可以查看系统cpu、内存利用率、磁盘IO、流量等情况
sar -u 1 10 (1:每隔一秒,10:写入10次)
sar命令:https://blog.csdn.net/volitationlong/article/details/81741754
4.2 管道符和重定向的区别
管道符 |:把结果传给一个变量
重定向 >>:将定向符前面的命令输出的内容重定向到一个目标位置
管道符可以把标准输出转标准输入,以让可以接受标准输入的命令可以以此为输入执行命令
输入输出重定向就是取代了键盘屏幕,能够接受键盘输入的都可以用重定向改为文件输入,能够输出到屏幕的,都可以通过重定向保存到文件
4.3 cache和buffer区别
cache和buffer区别 :https://www.zhihu.com/question/26190832
cache 缓存
cache 是为了弥补高速设备和低速设备的鸿沟而引入的中间层,最终起到加快访问速度的作用。
因为CPU和memory之间的速度差异越来越大,所以人们充分利用数据的局部性(locality)特征,通过使用存储系统分级(memory hierarchy)的策略来减小这种差异带来的影响。
buffer 缓冲
buffer 的主要目的进行流量整形,把突发的大数量较小规模的 I/O 整理成平稳的小数量较大规模的 I/O,以减少响应次数。
比如生产者——消费者问题,他们产生和消耗资源的速度大体接近,加一个buffer可以抵消掉资源刚产生/消耗时的突然变化。
直观的区别:
cache是随机访问,buffer往往是顺序访问
释放buffffer和cache
[root@linux-server ~]# echo 3 > /proc/sys/vm/drop_caches
以读写来对两者分析:
在read(读取)的场合,cache通常被用于减少重复读取数据时的开销,而buffer则用于规整化每次读取数据的尺寸,在读取场合两者用途差别很大。
在write(写入)的场合,两者功能依然没变,但由于cache跟buffer的功能在写入场合可以融合使用,所以两者可以被混淆,写入缓冲跟写入缓存往往会同时担当规整化写入尺寸以及减少写入次数的功能,所以两者有时会被混淆,但这只是个名称问题,没有原则性关系。
4.4 Linux怎么设置开机自启动某个脚本
4.4.1 第一种 chkconfig管理
将脚本拷贝到/etc/init.d/目录下,
添加到系统服务
chkconfig --add name.sh
设置开机启动
chkconfig name.sh on
重启
4.4.2 第二种 修改/etc/rc.local
name.sh
#!/bin/bash
/bin/echo $(/bin/date +%F_%T) >> /tmp/name.log
/etc/rc.local,该文件为链接文件
[root@localhost ~]# ll /etc/rc.local
lrwxrwxrwx. 1 root root 13 Feb 5 10:03 /etc/rc.local -> rc.d/rc.local
修改/etc/rc.local文件
[root@localhost scripts]# tail -n 1 /etc/rc.local
/bin/bash /server/scripts/name.sh >/dev/null 2>/dev/null
重启系统,查看结果
[root@localhost ~]# cat /tmp/name.log
2020-06-19_23:30:56
已开机自启动该脚本
4.5 kill和kill-9区别
kill详解:https://www.cnblogs.com/liuhouhou/p/5400540.html
kill -15:一般不加参数kill是使用15来杀,这相当于正常停止进zhi程,停止进程的时候会释放进程所占用的资源;
kill - 9: 表示强制杀死该进程

附录:
linux signals
| Signal Name | Number | Description |
|---|---|---|
| SIGHUP | 1 | Hangup (POSIX) |
| SIGINT | 2 | Terminal interrupt (ANSI) |
| SIGQUIT | 3 | Terminal quit (POSIX) |
| SIGILL | 4 | Illegal instruction (ANSI) |
| SIGTRAP | 5 | Trace trap (POSIX) |
| SIGIOT | 6 | IOT Trap (4.2 BSD) |
| SIGBUS | 7 | BUS error (4.2 BSD) |
| SIGFPE | 8 | Floating point exception (ANSI) |
| SIGKILL | 9 | Kill(can’t be caught or ignored) (POSIX) |
| SIGUSR1 | 10 | User defined signal 1 (POSIX) |
| SIGSEGV | 11 | Invalid memory segment access (ANSI) |
| SIGUSR2 | 12 | User defined signal 2 (POSIX) |
| SIGPIPE | 13 | Write on a pipe with no reader, Broken pipe (POSIX) |
| SIGALRM | 14 | Alarm clock (POSIX) |
| SIGTERM | 15 | Termination (ANSI) |
| SIGSTKFLT | 16 | Stack fault |
| SIGCHLD | 17 | Child process has stopped or exited, changed (POSIX) |
| SIGCONT | 18 | Continue executing, if stopped (POSIX) |
| SIGSTOP | 19 | Stop executing(can’t be caught or ignored) (POSIX) |
| SIGTSTP | 20 | Terminal stop signal (POSIX) |
| SIGTTIN | 21 | Background process trying to read, from TTY (POSIX) |
| SIGTTOU | 22 | Background process trying to write, to TTY (POSIX) |
| SIGURG | 23 | Urgent condition on socket (4.2 BSD) |
| SIGXCPU | 24 | CPU limit exceeded (4.2 BSD) |
| SIGXFSZ | 25 | File size limit exceeded (4.2 BSD) |
| SIGVTALRM | 26 | Virtual alarm clock (4.2 BSD) |
| SIGPROF | 27 | Profiling alarm clock (4.2 BSD) |
| SIGWINCH | 28 | Window size change (4.3 BSD, Sun) |
| SIGIO | 29 | I/O now possible (4.2 BSD) |
| SIGPWR | 30 | Power failure restart (System V) |
4.6 写一个脚本来判断文件是否存在
判断文件:https://blog.csdn.net/it8343/article/details/93207169
判断文件是否存在:
if [ -f "/data/filename" ];then
echo "文件存在"
else
echo "文件不存在"
fi
其他参数
-e 判断对象是否存在
-d 判断对象是否存在,并且为目录
-f 判断对象是否存在,并且为常规文件
-L 判断对象是否存在,并且为符号链接
-h 判断对象是否存在,并且为软链接
-s 判断对象是否存在,并且长度不为0
-r 判断对象是否存在,并且可读
-w 判断对象是否存在,并且可写
-x 判断对象是否存在,并且可执行
-O 判断对象是否存在,并且属于当前用户
-G 判断对象是否存在,并且属于当前用户组
-nt 判断file1是否比file2新 [ "/data/file1" -nt "/data/file2" ]
-ot 判断file1是否比file2旧 [ "/data/file1" -ot "/data/file2" ]
4.7 ping一个地址的实现过程,协议
Ping命令用ICMP实现的,ICMP是Internet控制消息协议,用于IP主机,路由器之间传递消息。控制消息是指网络通不通,主机是否可达,路由器是否可用等网络本身的消息,这些控制消息并不传输用户数据。
Ping的原理是:向指定IP发送一定长度的数据包,按照约定,若指定IP存在的话,会返回同样大小的数据包,若没有在特定时间返回就是超时,就认为指定IP不存在。但是由于防火墙会屏蔽ICMP协议,所以ping不通不一定说明对方IP不存在。
注:跟踪路由的Tracert命令也是基于ICMP协议
4.8 用脚本实现最简单的两个数相除(精确到小数点后四位)
第一种
[root@mysql ~]# awk 'BEGIN{printf "%0.4f",1/3}' | sed 's/[0-9]$/&\n/g'
0.3333
第二种
[root@mysql tmp]# vim shell.sh
#! /bin/bash
echo "此脚本用于计算1-1/2+1/3-1/4+....-1/N的值"
echo "请输入 N:"
read N
sum=0
for ((i=1;i
4.9 权限体系,755,一些特殊文件为什么是600.400
权限掩码umask
umask设置的是权限“补码”:如上umask值为022,则对应目录权限为7-0=7,7-2=5,7-2=5,即用777减去umask的相应位上的值;而对应的文件权限是用666减去umask的相应位上的值。
查看
[root@mysql tmp]# umask
0022
默认情况下
- 目录权限rwx r-x r-x (755) 这就是目录创建缺省权限 777
- 文件权限rw- r– r– (644) 这就是文件创建缺省权限 666
4.10 查看内存的命令,内存占用最大的进程,怎么看这个进程调用了哪些文件,以及查看核数
内存查看:https://www.cnblogs.com/sunyllove/p/9968219.html
内存占用进程:https://www.cnblogs.com/sparkbj/p/6148817.html
4.10.1 查看内存的命令
free
sar
top(htop itop)
ps aux
cat /proc/meminfo
4.10.2 内存占用最大的进程
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
查看占用内存最高的进程
ps aux|head -1;ps aux|grep -v PID|sort -rn -k +4|head
或者top (然后按下M,注意这里是大写)
4.10.3 看这个进程调用了哪些文件
查看该进程打开的文件:lsof -p ID
查看内存分配:cat /proc/ID/maps
4.10.4 查看核数
cat /proc/cpuinfo
查看linux系统核数
cat /proc/cpuinfo| grep "processor"
总核数 = 物理CPU个数 X 每颗物理CPU的核数
总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
或grep 'physical id' /proc/cpuinfo | sort -u | wc -l
查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
或者grep 'core id' /proc/cpuinfo | sort -u | wc -l
查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
或者grep 'processor' /proc/cpuinfo | sort -u | wc -l
查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
或者dmidecode -s processor-version
#查看内 存信息cat /proc/meminfo
4.11 tcpdump指定源端口,过滤8000-9000端口
tcpdump帮助页:https://www.tcpdump.org/manpages/tcpdump.1.html
tcpdump帮助页中文版:https://www.cnblogs.com/ggjucheng/archive/2012/01/14/2322659.html
tcpdump高级包过滤:https://blog.csdn.net/wzx19840423/article/details/50836761
tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。
[root@mysql ~]# tcpdump --help
tcpdump version 4.9.2
libpcap version 1.5.3
OpenSSL 1.0.2k-fips 26 Jan 2017
Usage: tcpdump [-aAbdDefhHIJKlLnNOpqStuUvxX#] [ -B size ] [ -c count ]
[ -C file_size ] [ -E algo:secret ] [ -F file ] [ -G seconds ]
[ -i interface ] [ -j tstamptype ] [ -M secret ] [ --number ]
[ -Q|-P in|out|inout ]
[ -r file ] [ -s snaplen ] [ --time-stamp-precision precision ]
[ --immediate-mode ] [ -T type ] [ --version ] [ -V file ]
[ -w file ] [ -W filecount ] [ -y datalinktype ] [ -z postrotate-command ]
[ -Z user ] [ expression ]
过滤8000-9000端口
tcpdump -i eth0 src port 'tcp[0:2] not 8000-9000'
另外:
time tcpdump -nn -i eth0 'tcp[tcpflags] = tcp-syn' -c 10000 > /dev/null
上面的命令计算抓10000个SYN包花费多少时间,可以判断访问量大概是多少。
指定某个IP抓
tcpdump -i eth0 host 192.168.1.1
4.12 几种下载安装的步骤,报错有哪些情况,怎么解决
4.12.1 yum安装
一般来说配置镜像站比较好,这样可以安装自己想要的软件包
(默认下,会找最近的镜像站)
yum install -y (apt-get install)
rpm -ivh
升级rpm -Uvh
4.12.2 编译安装
xxx.tar.gz
tar -xzf
./configure
make
make install
4.12.3 二进制安装
xxx.tar.gz
tar -xzf
通过配置文件来完成
4.12.4 三种安装方法优缺点比较
| rpm | 二进制 | 源码 | |
|---|---|---|---|
| 优点 | 安装简单,适合初学者学习使用 | 安装简单 可以安装在任何路径下,灵活性好 一台服务器可以安装多个mysql |
在实际安装的操作系统进行可根据需要定制编译,最灵活 性能最好 一台服务器可以安装多个mysql |
| 缺点 | 需要单独下载客户端和服务器 安装路径不灵活,默认路径不能修改,一台服务器只能安装一个mysql |
已经经过编译,性能不如源码编译的好 不能灵活定制编译参数 |
安装过程较复杂 编译时间长 |
4.12.5 常见错误
1)BASE镜像多个问题:https://www.cnblogs.com/kaiziwu/p/12101742.html
Repository base is listed more than once in the configuration"和"没有可用软件包 XXX"的问题
从对报错内容的分析来看, 应该是软件源有重复(“listed more than once”), 所以这里我们尝试删除一些上面的软件源配置文件.
在删除之前, 先对 /etc/yum.repos.d/ 目录下的文件做一个整体的备份, 以便于尝试失败后的还原.
删除之后重建缓存 yum clean all; yum makecache
2)epel库没装
导致有些软件包没有
yum install -y epel-release
3)没有更新源或者已安装软件包
yum update (apt-get update)(更新源)
yum upgrade (apt-get install upgrade) (更新已安装的包) (这个要慎重)
4.13 iptables的操作,过滤一个IP,与firewall的区别,了解ipset
4.13.1 iptables过滤一个IP
iptables用法:https://www.cnblogs.com/chanix/p/12744074.html
过滤某个IP
iptables -A INPUT -s 192.168.80.121 -p tcp -d 192.168.217.155 --dport 80 -j DROP
其他iptables指令:https://blog.csdn.net/chengxuyuanyonghu/article/details/51897666
4.13.2 查看output策略
iptables -L [-t (filter/nat/mangle/raw)] OUTPUT
4.13.3 建立自定义链
iptables -N NAME 创建自定义链
iptables -A INPUT -p tcp -s 192.168.217.154 --dport 80 -j NAME 引用自定义链
iptables -E OLD NEW 重命名自定义链
iptables -X NAME 删除自定义链
4.13.4 清理防火墙选项
iptables -F
4.13.5 7以上防火墙命令
firewalld操作命令:https://www.cnblogs.com/leoxuan/p/8275343.html
firewalld-cmd
参数
--get-default-zone 查询默认的区域名称
--set-default-zone=<区域名称> 设置默认的区域,使其永久生效
--get-services 显示预先定义的服务
4.13.6 iptables与firewall的区别
iptables和firewalld的详解:https://blog.csdn.net/weixin_40658000/article/details/78708375
firewall是centos7里面的新的防火墙命令,它底层还是使用 iptables 对内核命令动态通信包过滤的,简单理解就是firewall是centos7下管理iptables的新命令
1)最本质的不同在于配置文件的位置
iptables 在/etc/sysconfig/iptables中储存配置,而firewalld将配置储存在/usr/lib/firewalld/和/etc/firewalld/中的各种XML文件里
2)iptables通过控制端口来控制服务,而firewalld则是通过控制协议来控制端口
3)一个黑名单,一个白名单
4)一个centos6,一个centos7
4.13.7 ipset
ipset详解:https://blog.csdn.net/gymaisyl/article/details/101695697
ipset是iptables的扩展,它允许你创建 匹配整个地址集合的规则。而不像普通的iptables链只能单IP匹配, ip集合存储在带索引的数据结构中,这种结构即时集合比较大也可以进行高效的查找,除了一些常用的情况,比如阻止一些危险主机访问本机,从而减少系统资源占用或网络拥塞,IPsets也具备一些新防火墙设计方法,并简化了配置.
应用:
- 一口气存储多个IP地址或端口号,并与iptables 进行匹配;
- 针对IP地址或端口动态更新iptables规则,而不会影响性能;
- 通过一个iptables规则表达基于IP地址和端口的复杂规则集, 并受益于IP集的速度
ipset官网:http://ipset.netfilter.org/
[root@localhost ~]# ipset --help
ipset v6.29
Usage: ipset [options] COMMAND
Commands:
create SETNAME TYPENAME [type-specific-options]
Create a new set
SETNAME是创建的ipset的名称,TYPENAME是ipset的类型:
add SETNAME ENTRY
Add entry to the named set
del SETNAME ENTRY
Delete entry from the named set
test SETNAME ENTRY
Test entry in the named set
destroy [SETNAME]
Destroy a named set or all sets
list [SETNAME]
List the entries of a named set or all sets
save [SETNAME]
Save the named set or all sets to stdout
restore
Restore a saved state
flush [SETNAME]
Flush a named set or all sets
rename FROM-SETNAME TO-SETNAME
Rename two sets
swap FROM-SETNAME TO-SETNAME
Swap the contect of two existing sets
help [TYPENAME]
Print help, and settype specific help
version
Print version information
quit
Quit interactive mode
Options:
-o plain|save|xml
Specify output mode for listing sets.
Default value for "list" command is mode "plain"
and for "save" command is mode "save".
-s
Print elements sorted (if supported by the set type).
-q
Suppress any notice or warning message.
-r
Try to resolve IP addresses in the output (slow!)
-!
Ignore errors when creating or adding sets or
elements that do exist or when deleting elements
that don't exist.
-n
When listing, just list setnames from the kernel.
-t
When listing, list setnames and set headers
from kernel only.
-f
Read from the given file instead of standard
input (restore) or write to given file instead
of standard output (list/save).
Supported set types:
list:set 3 skbinfo support
list:set 2 comment support
list:set 1 counters support
list:set 0 Initial revision
hash:mac 0 Initial revision
hash:net,iface 6 skbinfo support
hash:net,iface 5 forceadd support
hash:net,iface 4 comment support
hash:net,iface 3 counters support
hash:net,iface 2 /0 network support
hash:net,iface 1 nomatch flag support
hash:net,iface 0 Initial revision
hash:net,port 7 skbinfo support
hash:net,port 6 forceadd support
hash:net,port 5 comment support
hash:net,port 4 counters support
hash:net,port 3 nomatch flag support
hash:net,port 2 Add/del range support
hash:net,port 1 SCTP and UDPLITE support
hash:net,port,net 2 skbinfo support
hash:net,port,net 1 forceadd support
hash:net,port,net 0 initial revision
hash:net,net 2 skbinfo support
hash:net,net 1 forceadd support
hash:net,net 0 initial revision
hash:net 6 skbinfo support
hash:net 5 forceadd support
hash:net 4 comment support
hash:net 3 counters support
hash:net 2 nomatch flag support
hash:net 1 Add/del range support
hash:net 0 Initial revision
hash:ip,port,net 7 skbinfo support
hash:ip,port,net 6 forceadd support
hash:ip,port,net 5 comment support
hash:ip,port,net 4 counters support
hash:ip,port,net 3 nomatch flag support
hash:ip,port,net 2 Add/del range support
hash:ip,port,net 1 SCTP and UDPLITE support
hash:ip,port,ip 5 skbinfo support
hash:ip,port,ip 4 forceadd support
hash:ip,port,ip 3 comment support
hash:ip,port,ip 2 counters support
hash:ip,port,ip 1 SCTP and UDPLITE support
hash:ip,mark 2 sbkinfo support
hash:ip,mark 1 forceadd support
hash:ip,mark 0 initial revision
hash:ip,port 5 skbinfo support
hash:ip,port 4 forceadd support
hash:ip,port 3 comment support
hash:ip,port 2 counters support
hash:ip,port 1 SCTP and UDPLITE support
hash:ip 4 skbinfo support
hash:ip 3 forceadd support
hash:ip 2 comment support
hash:ip 1 counters support
hash:ip 0 Initial revision
bitmap:port 3 skbinfo support
bitmap:port 2 comment support
bitmap:port 1 counters support
bitmap:port 0 Initial revision
bitmap:ip,mac 3 skbinfo support
bitmap:ip,mac 2 comment support
bitmap:ip,mac 1 counters support
bitmap:ip,mac 0 Initial revision
bitmap:ip 3 skbinfo support
bitmap:ip 2 comment support
bitmap:ip 1 counters support
bitmap:ip 0 Initial revision
源和目的都使用ipset(源ip集合为aaa,目的ip集合为bbb)
iptables -I INPUT -m set --match-set aaa src -m set --match-set bbb dst -j DROP
4.14 查看网卡信息,MTU与MSS的区别
4.14.1 查看网卡信息
查看网卡详解:https://blog.csdn.net/morigejile/article/details/78598645
ifconfig
lspci (pciutils)
iwconfig (wireless-tools)用于查看无线网络
ethtool 用于查询配置网卡参数
4.14.2 MTU
MTU:https://blog.csdn.net/passionkk/article/details/100538418
标准以太网长度上下限:https://blog.51cto.com/19880206/890070
Maximum Transmission Unit,缩写MTU,中文名是:最大传输单元。
标准以太网帧长度下限为:64 字节
标准以太网帧长度上限为:1518 字节
1518,头信息有14字节,尾部校验和FCS占了4字节,所以真正留给上层协议传输数据的大小就是:1518 - 14 - 4 = 1500
标准以太网帧长度下限:
一个帧从A-B,B-A的这个时间被称为slot time,这个时间计算出来为57.6 μs.
在10Mbit/s的网络中,在57.6μs的时间内,能够传输576个bit,所以要求以太网帧的大小最小为576个bits,从而让所有的碰撞都能够被检测到
在传输完一个数据帧以后,在传输下一个数据帧之前,要传输12bytes的空闲帧
12 bytes = 12×8 = 96 bits
在10Mbit/s的网络中,传输1个bit 需要的时间为 1×10-7s
所以Interframe Gap 的时间为 96×10-7=9.6×10-6 s= 9.6μs
在一个数据帧发送完以后,要等待9.6μs的时间,然后再传输下一个数据帧
576bits= 72 bytes
通常情况下我们所说的以太网长度,不包括preamble和start of frame delimiter,所以以太网最小长度为:72-8= 64 bytes
标准以太网帧长度上限:
标准的以太网的最大字节长度为1518/1522:
untagged的frame最大帧长为1518
tagged的frame 最大帧长为1522
4.14.3 MSS
Maximum Segment Size,缩写MSS,中文名是:最大报文段长度。
为了达到最佳的传输效能,TCP协议在建立连接的时候通常要协商双方的MSS值,这个值TCP协议在实现的时候往往用MTU值代替(需要减去IP数据包包头的大小20Bytes和TCP数据段的包头20Bytes)所以一般MSS值1460
4.14.4 MTU和MSS的区别
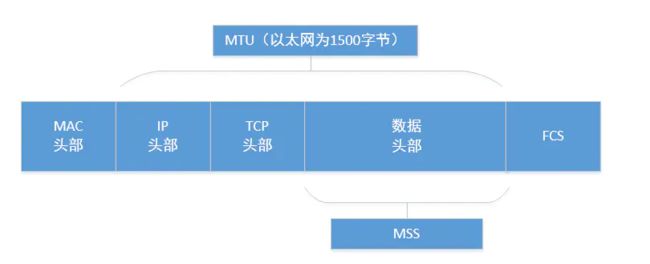
MTU: Maximum Transmit Unit,最大传输单元,即物理接口(数据链路层)提供给其上层(通常是IP层)最大一次传输数据的大小;以普遍使用的以太网接口为例,缺省MTU=1500 Byte,这是以太网接口对IP层的约束,如果IP层有<=1500 byte 需要发送,只需要一个IP包就可以完成发送任务;如果IP层有> 1500 byte 数据需要发送,需要分片才能完成发送,这些分片有一个共同点,即IP Header ID相同。
MSS:Maximum Segment Size ,TCP提交给IP层最大分段大小,不包含TCP Header和 TCP Option,只包含TCP Payload ,MSS是TCP用来限制application层最大的发送字节数。如果底层物理接口MTU= 1500 byte,则 MSS = 1500- 20(IP Header) -20 (TCP Header) = 1460 byte,如果application 有2000 byte发送,需要两个segment才可以完成发送,第一个TCP segment = 1460,第二个TCP segment = 540。
4.15 cpu的使用率是怎样计算的,120%是什么意思,一个什么样的进程能让他达到200%
CPU使用率计算:https://www.cnblogs.com/gatsby123/p/11127158.html
man top查看
1. %CPU -- CPU Usage
The task's share of the elapsed CPU time since the last
screen update, expressed as a percentage of total CPU
time.
In a true SMP environment, if a process is multi-threaded
and top is not operating in Threads mode, amounts greater
than 100% may be reported. You toggle Threads mode with
the `H' interactive command.
Also for multi-processor environments, if Irix mode is
Off, top will operate in Solaris mode where a task's cpu
usage will be divided by the total number of CPUs. You
toggle Irix/Solaris modes with the `I' interactive com‐
mand.
总结来说某个进程的CPU使用率就是这个进程在一段时间内占用的CPU时间占总的CPU时间的百分比。
比如某个开启多线程的进程1s内占用了CPU0 0.6s, CPU1 0.6s, 那么它的占用率是120%。
某进程cpu使用率 = 该进程cpu时间 / 总cpu时间。
200%:
占用系统内存高,
netstat -natp | awk ‘{print $7}’| sort|uniq -c|sort -rn可以统计进程中线程的连接数。
top 命令:查看进程级别的cpu使用情况。
vmstat 命令:查看系统级别的cpu使用情况。
4.16 查看系统io状态,iostat里面的io百分比是怎么算的
4.16.1 查看系统io状态
1)
iostat手册:http://sebastien.godard.pagesperso-orange.fr/man_iostat.html
iostat(sysstat)
[root@mysql ~]# iostat
Linux 3.10.0-693.el7.x86_64 (mysql) 07/01/2020 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.02 0.00 0.07 0.06 0.00 99.85
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.20 3.76 2.13 199863 113262
scd0 0.00 0.02 0.00 1028 0
解释一下各个输出项的含义:
avg-cpu段:
%user: 在用户级别运行所使用的CPU的百分比.
%nice: nice操作所使用的CPU的百分比.
%system: 在系统级别(kernel)运行所使用CPU的百分比.
%iowait: CPU等待硬件I/O时,所占用CPU百分比.
%steal显示在管理程序为另一个虚拟处理器提供服务时,一个或多个虚拟CPU在非自愿等待中花费的时间百分比.
%idle: CPU空闲时间的百分比.
Device段:
tps: 每秒钟发送到的I/O请求数.
Blk_read /s: 每秒读取的block数.
Blk_wrtn/s: 每秒写入的block数.
Blk_read: 读入的block总数.
Blk_wrtn: 写入的block总数.入门使用
1.若 %iowait 的值过高,表示硬盘存在I/O瓶颈
2.若 %idle 的值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量
3.若 %idle 的值持续低于1,则系统的CPU处理能力相对较低,表明系统中最需要解决的资源是 CPU
2)
/proc/diskstats文件
diskstats:https://blog.csdn.net/cyan_grey/article/details/82787686
[root@mysql ~]# cat /proc/diskstats
8 0 sda 6352 64 461774 52377 5356 5774 947786 277103 0 33088 328047
8 1 sda1 134 1 8668 330 3 0 18 0 0 104 330
8 2 sda2 6079 63 444530 51800 5353 5774 947768 277103 0 33009 327470
8 3 sda3 52 0 4424 214 0 0 0 0 0 190 214
11 0 sr0 18 0 2056 201 0 0 0 0 0 197 201
第一列为 设备号
第二列为 次设备号
第三列为 设备名称
第四列为 成功完成读的总次数----- 读磁盘的次数
第五列为 合并读次数,为了效率可能会合并相邻的读和写,从而两次4K的读在它最终被处理到磁盘上之前可能会变成一次8K的读,才被计数(和排队),因此只有一次I/O操作。
第六列为 读扇区的次数
第七列为 读花的时间(ms),这是所有读操作所花费的毫秒数(用__make_request()到end_that_request_last()测量)
第八列到第十一列分别是写
第十二列为 I/O的当前进度,只有这个域应该是0,如果这个值为0,同时write_complete read_complete io_processing 一直不变可能就就是IO hang了。
第十三列为 输入输入花的时间(ms),花在I/O操作上的毫秒数,这个域会增长只要field 9不为0。
第十四列为 输入/输出操作花费的加权毫秒数,
注:
zabbix中磁盘使用情况就是从diskstats采集,磁盘使用率计算方式为:
两次采集的输入/输出操作花费的毫秒数之差 / 采集间隔时间
例如:第一次采集输入/输出操作花费的毫秒数为90258834,间隔10秒后采集的值为90258710
那么磁盘使用率为 (90258710ms - 90258834ms)/ 10*1000ms = 0.0124,也就是1.24%
4.16.2 iostat里面的io百分比
IO的各指标计算方法:https://blog.csdn.net/qu1993/article/details/105702991/
iostat和iowait详细解析:https://www.cnblogs.com/549294286/p/6561900.html
%iowait = (cpu idle time)/(all cpu time)
4.17 运行一个shell脚本怎样调试,怎样看到执行的整个过程,中间有一句错了后面还会不会执行,怎样解决
4.17.1 脚本调试
sh -n/-x/-c:https://blog.csdn.net/weixin_42167759/article/details/80700719
-n/-x/-c
-n 只读取shell脚本,但不实际执行
-x 进入跟踪方式,显示所执行的每一条命令
-c “string” 从strings中读取命令
sh -x xxx.sh 加上-x会显示错在哪,显示脚本里面的内容,并且还会报错,显示过程
在shell中,默认当某行命令执行出错之后,后面的命令会继续执行,这会导致后面的代码会出现不可预知的错误,所以当我们的shell程序出错时,应该立即停止执行shell程序。
解决:
在shell文件中加上set -e(当执行语句的状态码不为0时,直接退出程序。)
但有时候又需要关掉set -e(如判断目录是否存在时会直接退出程序)
set -x #启动"-x"选项
要跟踪的程序段
set +x #关闭"-x"选项
输出调式信息:https://www.ibm.com/developerworks/cn/linux/l-cn-shell-debug/
trap命令,
tee命令,
4.17.2 调试器bashdb
bashdb:http://bashdb.sourceforge.net/
bashdb -debug 脚本名
l 列出当前行以下的10行
- 列出正在执行的代码行的前面10行
. 回到正在执行的代码行
w 列出正在执行的代码行前后的代码
/pat/ 向后搜索pat
?pat?向前搜索pat
查看帮助 debug类
[root@mysql tmp]# bashdb -h
Usage:
bashdb [OPTIONS]
Runs bash under a debugger.
options:
-h | --help Print this help.
-q | --quiet Do not print introductory and quiet messages.
-A | --annotate LEVEL Set the annotation level.
-B | --basename Show basename only on source file listings.
(Needed in regression tests)
--highlight {dark|light} Use dark or light background ANSI terminal sequence
syntax highlighting
| --no-highlight
Don't use ANSI terminal sequences for syntax
highlight
--highlight | --no-highlight
Use or don't use ANSI terminal sequences for syntax
highlight
--init-file FILE Source script file FILE. Similar to bash's
corresponding option. This option can be given
several times with different files.
-L | --library DIRECTORY
Set the directory location of library helper file: /usr/share/bashdb/dbg-main.sh
-c | --command STRING Run STRING instead of a script file
-n | --nx | --no-init Don't run initialization files.
-S | --style STYLE Run use pygments STYLE for formatting source code
--tty | --terminal DEV Set to terminal in debugger output to DEV
DEV can also be &1 for STDOUT
-T | --tempdir DIRECTORY
Use DIRECTORY to store temporary files
-V | --version Print the debugger version number.
-X | --trace Set line tracing similar to set -x
-x | --eval-command CMDFILE
Execute debugger commands from CMDFILE.
4.18 free
4.18.1 free
buffer/cache:https://www.cnblogs.com/ultranms/p/9254160.html
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer
参数
[root@mysql ~]# free --help
Usage:
free [options]
Options:
-b, --bytes show output in bytes 以Byte为单位显示内存使用情况
-k, --kilo show output in kilobytes 以KB为单位显示内存使用情况
-m, --mega show output in megabytes 以MB为单位显示内存使用情况
-g, --giga show output in gigabytes 以GB为单位显示内存使用情况
--tera show output in terabytes 以太字节为单位显示内存使用情况
-h, --human show human-readable output
--si use powers of 1000 not 1024
-l, --lohi show detailed low and high memory statistics
-t, --total show total for RAM + swap
-s N, --seconds N repeat printing every N seconds
-c N, --count N repeat printing N times, then exit
-w, --wide wide output
--help display this help and exit
-V, --version output version information and exit
简单实例
[root@mysql ~]# free
total used free shared buff/cache available
Mem: 999696 85448 403028 6852 511220 740156
Swap: 1048572 0 1048572
[root@mysql ~]# free -m
total used free shared buff/cache available
Mem: 976 83 393 6 499 723
Swap: 1023 0 1023
[root@mysql ~]# free -h
total used free shared buff/cache available
Mem: 976M 83M 393M 6.7M 499M 723M
Swap: 1.0G 0B 1.0G
字段解释:
Mem 行(第二行)是内存的使用情况。
Swap 行(第三行)是交换空间的使用情况。
total 列显示系统总的可用物理内存和交换空间大小。
used 列显示已经被使用的物理内存和交换空间。
free 列显示还有多少物理内存和交换空间可用使用。
shared 列显示被共享使用的物理内存大小。
buff/cache 列显示被 buffer 和 cache 使用的物理内存大小。
available 列显示还可以被应用程序使用的物理内存大小。
available = free + buffer + cache
4.18.2 /proc/meminfo 文件
其实 free 命令中的信息都来自于 /proc/meminfo 文件
[root@mysql ~]# cat /proc/meminfo
MemTotal: 999696 kB
MemFree: 403412 kB
MemAvailable: 740768 kB
Buffers: 16632 kB
Cached: 438216 kB
SwapCached: 0 kB
Active: 210600 kB
Inactive: 286932 kB
Active(anon): 43124 kB
Inactive(anon): 6408 kB
Active(file): 167476 kB
Inactive(file): 280524 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 1048572 kB
SwapFree: 1048572 kB
Dirty: 0 kB
Writeback: 0 kB
AnonPages: 42712 kB
Mapped: 28452 kB
Shmem: 6852 kB
Slab: 56504 kB
SReclaimable: 34160 kB
SUnreclaim: 22344 kB
KernelStack: 3568 kB
PageTables: 5852 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 1548420 kB
Committed_AS: 242444 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 176120 kB
VmallocChunk: 34359310332 kB
HardwareCorrupted: 0 kB
AnonHugePages: 10240 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
DirectMap4k: 57216 kB
DirectMap2M: 991232 kB
DirectMap1G: 0 kB
4.19 一个脚本重定向到另一个文件,另一个文件却是空的是怎么回事(排除权限问题)
stdout:https://cloud.tencent.com/developer/ask/172310
如果你用print要输出文本,其参数flush可能对你有帮助:
print('Hello, World', flush=True)
有一种情况,就是重定向的输入和输出都是同一文件
测试结果如下:
[root@mysql tmp]# cat 1.txt
a
b
c
[root@mysql tmp]# cat 1.txt > 1.txt
cat: 1.txt: input file is output file
[root@mysql tmp]# cat 1.txt
所以得到以下结论如果文件不存在会自动创建,如果存在会清空。
4.20 shell重定向有几种方式,标准错误输出,一条命令不要他的输出与标准错误输出怎么做
4.20.1 shell重定向
详解shell中的几种标准输出重定向方式:https://blog.csdn.net/yuki5233/article/details/85091314
重定向的方式:
>
tee
| 文件描述符 | 代表的含义 | 默认情况 | 对应文件句柄位置 |
|---|---|---|---|
| 1 | 标准正确输出(standard output) | 输出到屏幕(即控制台) | /proc/self/fd/1 |
| 2 | 标准错误输出(error output) | 输出到屏幕(即控制台) | /proc/self/fd/2 |
| 0 | 标准输入(standard input) | 从键盘获得输入 | /proc/self/fd/0 |
一条命令不要他的输出与标准错误输出: >/dev/null 2>&1
>/dev/null
这条命令等同于 1>/dev/null,作用是将标准正确输出1重定向到/dev/null中。 /dev/null代表linux的空设备文件,所有往这个文件里面写入的内容都会丢失,俗称“黑洞”。那么执行了>/dev/null之后,标准正确输出的内容就会不再存在,没有任何地方能够找到输出的内容。
2>&1
这条命令用到了重定向绑定,采用&可以将两个输出绑定在一起。这条命令的作用是将标准错误输出和标准正确输出输出同用一个文件描述符,说人话就是标准错误输出和标准正确输出重定向到同一个地方。
linux在执行shell命令之前,就会确定好所有的输入输出位置,并且从左到右依次执行重定向的命令,所以>/dev/null 2>&1的作用就是让标准正确输出重定向到/dev/null中(丢弃标准正确输出),然后标准错误输出由于重用了标准正确输出的描述符,所以标准错误输出也会被定向到了/dev/null中,标准错误输出同样也被丢弃了。执行了这条命令之后,该条shell命令将不会输出任何信息到控制台,也不会有任何信息输出到文件中。
4.20.2 >/dev/null 2>&1 和 2>&1 >/dev/null区别
结论:
| 命令 | 标准正确输出 | 标准错误输出 |
|---|---|---|
| >/dev/null 2>&1 | 丢弃 | 丢弃 |
| 2>&1 >/dev/null | 丢弃 | 屏幕 |
4.21 top显示内容,第一行最后三个的含义,负载是什么意思,为什么不能超过核心数,是什么原理
top各部分详解:https://blog.csdn.net/weixin_46108954/article/details/105492945
load average: 0.09, 0.03, 0.01
load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。
计算公式:load(t) = load(t-1) e^(-5/60) + n (1 - e^(-5/60)),迭代计算,其中n为run-queue length。
采用此公式的好处:局部的load抖动不会对load average造成重大影响,使其平滑。
Load Average的值应该小于CPU个数X核数X0.7
可以将CPU负载理解为车道的负载,对单车道而言:
- 如果路面上的车不多,没有占满车道,那么load < 1;
- 如果占满了车道,load = 1;
- 如果车道外面还有车在等待,load > 1;
判断load average状态:
1、状态为R和D的任务
2、CPU使用率高,IO无作业, Load Average低,系统反应颠簸
这种场景,通常是计算密集型任务,即大量生成耗时短的计算任务。
3、CPU使用率低,IO等待, Load Average高,系统不卡
这种场景,通常是IO密集型任务,如果大量请求都集中于相同的IO设备,超出设备的响应能力,会造成任务在运行队列里堆积等待,也就是D状态的进程堆积,那么此时Load Average就会飙高。
4、CPU使用率低,IO繁忙, Load Average低,系统卡
这种场景,通常是低频大文件读写,由于请求数量不大,所以任务都处于R状态,Load Average数值反映了当前运行的任务数,不会飙升,IO设备处于满负荷工作状态,导致系统响应能力降低。
5、CPU使用率高,IO繁忙/等待, Load Average高,系统卡
这种场景,通常是服务混部,即IO、计算密集型任务混部在一起,相当于CPU、IO都处于高负荷状态,那么Load Average 自然很高。
例子:
我们举个例子:高速公路收费站10个车道,那当有1-9辆车在不同的通道通过时,认为收费站的load<1;当正好10辆车在不同的通道时,load=1;当超过10辆车(假设每个通道是均匀有车)时,load>1.假设有100辆车,每个通道10辆,那就说明能有10辆车能过去,另外90辆车则需要等待。此时收费站的load为100/10=10. 这个10的负载表示系统当前满负荷运转,且还有相当于90%的满负载的请求在等待。
4.22 查看磁盘读写的MB用什么参数,查看tps用什么参数
查看TPS和吞吐量信息
[root@localhost ~]# iostat -d -m 1 2
Linux 3.10.0-693.el7.x86_64 (mg-nginx-02) 07/02/2020 _x86_64_ (1 CPU)
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 23.65 0.64 0.25 170 67
scd0 0.07 0.00 0.00 1 0
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
sda 0.00 0.00 0.00 0 0
scd0 0.00 0.00 0.00 0 0
sar -b 1 2 但这个没有以单位来查看
4.23 linux socket建立和关闭的原理
1、socket是对TCP/UDP协议的封装,Socket本身并不是协议,而是一个调用接口,通过Socket,我们才能使用TCP/UDP协议。
2、UDP和TCP都是通过『IP地址』与『TCP Port』形成一个『Socket』,透过此Socket与对方的Socket形成一个『Socket Pair』进行通讯。
3、通常我们在说到网络编程时默认是指TCP编程,即用socket函数创建一个socket用于TCP通讯.
4、UDP和TCP编程区别:http://blog.chinaunix.net/uid-26421509-id-3814684.html
TCP编程的服务器端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt(); * 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();
4、开启监听,用函数listen();
5、接收客户端上来的连接,用函数accept();
6、收发数据,用函数send()和recv(),或者read()和write();
7、关闭网络连接;
8、关闭监听;
TCP编程的客户端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选
4、设置要连接的对方的IP地址和端口等属性;
5、连接服务器,用函数connect();
6、收发数据,用函数send()和recv(),或者read()和write();
7、关闭网络连接;
总结:客户端的connect在三次握手的第二次返回,而服务器端的accept在三次握手的第三次返回。
与之对应的UDP编程步骤要简单许多,分别如下:
UDP编程的服务器端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();
4、循环接收数据,用函数recvfrom();
5、关闭网络连接;
UDP编程的客户端一般步骤是:
1、创建一个socket,用函数socket();
2、设置socket属性,用函数setsockopt();* 可选
3、绑定IP地址、端口等信息到socket上,用函数bind();* 可选
4、设置对方的IP地址和端口等属性;
5、发送数据,用函数sendto();
6、关闭网络连接;
优雅关闭和强制关闭:https://blog.51cto.com/3layer/1119552
关闭socket和关闭TCP连接的区别,关闭TCP连接是指TCP协议层的东西,就是两个TCP端之间交换了一些协议包(FIN,RST等),具体的交换过程可以看TCP协议,这里不详细描述了。而关闭socket是指关闭用户应用程序中的socket句柄,释放相关资源。但是当用户关闭socket句柄时会隐含的触发TCP连接的关闭过程。
TCP连接的关闭过程有两种,一种是优雅关闭(graceful close),一种是强制关闭(hard close或abortive close)。所谓优雅关闭是指,如果发送缓存中还有数据未发出则其发出去,并且收到所有数据的ACK之后,发送FIN包,开始关闭过程。而强制关闭是指如果缓存中还有数据,则这些数据都将被丢弃,然后发送RST包,直接重置TCP连接。
socket的底层创建与关闭:https://blog.csdn.net/jiaomingliang/article/details/45950591?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
二者的区别
close-----关闭本进程的socket id,但链接还是开着的,用这个socket id的其它进程还能用这个链接,能读或写这个socket id。
shutdown–破坏了socket 链接,读的时候可能侦探到EOF结束符,写的时候可能会收到一个SIGPIPE信号,这个信号可能直到socket buffer被填充了才收到,shutdown有一个关闭方式的参数,0 不能再读,1不能再写,2 读写都不能。
4.24 如何知道系统block大小
1.tune2fs命令查看block size大小:
tune2fs命令:http://blog.chinaunix.net/uid-7530389-id-2050094.html
[root@localhost ~]# tune2fs -l /dev/sda2 | grep 'Block size'
Block size: 4096
2.stat命令查看block size大小:
[root@localhost ~]# stat / | grep 'IO Block'
Size: 4096 Blocks: 8 IO Block: 4096 directory
3.dumpe2fs命令查看block size大小:
[root@localhost ~]# dumpe2fs /dev/sda2 | grep 'Block size'
dumpe2fs 1.42.9 (28-Dec-2013)
Block size: 4096
4.25 proc伪文件系统
proc文件系统是一种伪文件系统,只存在于内存中,只有内核运行时才会动态生成里面的内容。
创建proc文件的流程:https://blog.csdn.net/kokodudu/article/details/16368107
1、创建目录
struct proc_dir_entry *proc_mkdir(const char *name, struct proc_dir_entry *parent);
类似于mkdir()函数,name是目录名,如“example_dir”,parent是要创建的目录的父目录名(若parent = NULL则创建在/proc目录下)。
2、创建proc文件:
struct proc_dir_entry *create_proc_entry( const char *name, mode_t mode, struct proc_dir_entry *parent );
create_proc_entry函数用于创建一个一般的proc文件,其中name是文件名,比如“hello”,mode是文件模式,parent是要创建的proc文件的父目录(若parent = NULL则创建在/proc目录下)。
读回调函数原型:int mod_read( char *page, char **start, off_t off, int count, int *eof, void *data );
写回调函数原型:int mod_write( struct file *filp, const char __user *buff, unsigned long len, void *data );
4.26 LVM逻辑卷
物理卷(Phsical Volume):物理区段(Physical Extent)
卷组(Volume Group)
逻辑卷(Logic Volume):逻辑区段(Logical Extent)
4.26.1 逻辑卷优点
- 在磁盘池中添加磁盘和分区,对现有的文件系统进行在线扩展
- 用一个 160GB 磁盘替换两个 80GB 磁盘,而不需要让系统离线,也不需要在磁盘之间手工转移数据
- 当存储空间超过所需的空间量时,从池中去除磁盘,从而缩小文件系统
- 使用快照(snapshot)执行一致性的备份
4.26.2 创建逻辑卷过程
1)分区
2)制作物理卷 pvcreate 分区名
3)创建卷组 vgcreate -s PE大小 卷组名 物理卷路径
4)创建逻辑卷 lvcreate -n 逻辑卷名称 -L 逻辑卷大小 卷组名称
5)格式化 挂载
4.26.3 扩大缩小逻辑卷/卷组
1)卷组
删除卷组 vgremove 卷组
扩大卷组 vgextend 卷组名称 物理卷路径
缩小卷组 vgreduce
2)逻辑卷
扩大逻辑卷
1、扩逻辑卷 lvextend -L 1G /dev/mapper/plvg-lvmovie
2、扩文件系统 resize2fs /dev/mapper/plvg-lvmovie
缩小逻辑卷
1、卸载逻辑卷 umount /dev/mapper/plvg-lvmusic
2、文件系统检查 e2fsck -f /dev/mapper/plvg-lvmusic
3、缩小文件系统 resize2fs /dev/mapper/plvg-lvmusic 100M
4、缩小逻辑卷 lvreduce -L 100M /dev/mapper/plvg-lvmusic
5、挂载 mount -t ext4 /dev/mapper/plvg-lvmusic /mnt/music
扩大/缩小逻辑卷
lvresize -L +100M
lvresize -L -100M
4.26.4 备份逻辑卷
1)给源逻辑卷做快照卷
lvcreate -s -L 100M -n musicsnap /dev/mapper/plvg-lvmusic
2)将快照卷挂载
mount -t ext4 /dev/mapper/plvg-musicsnap /mnt/musicsnap
3)备份快照卷内容
tar / rsync
4)卸载
umount /mnt/musicsnap
5)删除快照卷
lvremove /dev/mapper/plvg-musicsnap
4.26.5 /扩容的方法
参照4.26.2和4.26.3
1)分区(partprobe更新分区)
2)制作物理卷 pvcreate 分区名
3)查看系统中的卷组 vgdisplay
4)扩大卷组 vgextend 卷组名 分区名
5)扩大逻辑卷 lvextend -L +1G 根目录挂载点
6)扩大文件系统 resize2fs 根目录挂载点
4.27 MBR的作用
MBR:http://www.found5.com/view/987.html
MBR 也就是主引导记录,位于硬盘的 0 磁道、0 柱面、1 扇区中,主要记录了启动引导程序和磁盘的分区表。
其中 446 Byte 安装了启动引导程序,其后 64 Byte 描述分区表,最后的 2 Byte 是结束标记。
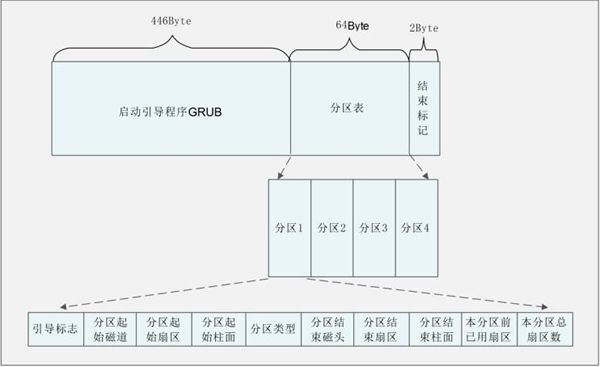
MBR 中最主要的功能就是存储启动引导程序。
4.28 /var/log目录下有什么,日志分别是哪些服务的,日志里面的内容是什么
4.28.1 /var/log/目录
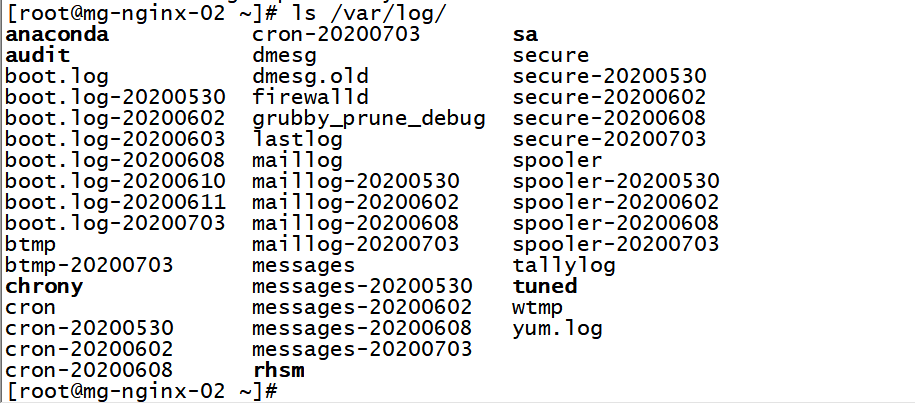
4.28.2 日志有哪些服务
/var/log/日志:https://www.cnblogs.com/kaishirenshi/p/7724963.html
1、/var/log/messages — 包括整体系统信息,其中也包含系统启动期间的日志。此外,mail,cron,daemon,kern和auth等内容也记录在var/log/messages日志中。
2、/var/log/dmesg — 包含内核缓冲信息(kernel ring buffer)。在系统启动时,会在屏幕上显示许多与硬件有关的信息。可以用dmesg查看它们。
3、/var/log/boot.log — 包含系统启动时的日志。
4、 /var/log/daemon.log — 包含各种系统后台守护进程日志信息。
5、 /var/log/yum.log – 包括安装或yum命令清除软件包的日志。
6、/var/log/kern.log – 包含内核产生的日志,有助于在定制内核时解决问题。
7、/var/log/lastlog — 记录所有用户的最近信息。这不是一个ASCII文件,因此需要用lastlog命令查看内容。
8、 /var/log/maillog /var/log/mail.log — 包含来着系统运行电子邮件服务器的日志信息。例如,sendmail日志信息就全部送到这个文件中。
9、/var/log/user.log — 记录所有等级用户信息的日志。
10、 /var/log/Xorg.x.log — 来自X的日志信息。
11、 /var/log/alternatives.log – 更新替代信息都记录在这个文件中。
12、/var/log/btmp – 记录所有失败登录信息。使用last命令可以查看btmp文件。例如,”last -f /var/log/btmp | more“。
13、/var/log/cups — 涉及所有打印信息的日志。
14、/var/log/anaconda.log — 在安装Linux时,所有安装信息都储存在这个文件中。
15、/var/log/cron — 每当cron进程开始一个工作时,就会将相关信息记录在这个文件中。
16、 /var/log/secure — 包含验证和授权方面信息。例如,sshd会将所有信息记录(其中包括失败登录)在这里。
17、 /var/log/wtmp或/var/log/utmp — 包含登录信息。使用wtmp可以找出谁正在登陆进入系统,谁使用命令显示这个文件或信息等。
4.28.3 日志里面的内容
例子
[root@mg-nginx-02 ~]# tail /var/log/yum.log
Apr 07 11:56:04 Installed: gcc-4.8.5-39.el7.x86_64
Apr 07 11:56:05 Updated: e2fsprogs-1.42.9-17.el7.x86_64
Apr 07 11:56:05 Updated: 1:openssl-1.0.2k-19.el7.x86_64
4.29 文件系统中文件查找快的原因
4.29.1 查找文件
二进制文件:which -a which #查看命令which所在位置,-a参数表示找出所有
二进制文件,源代码文件或帮助文档:whereis命令用于搜索程序的二进制文件,源代码文件或帮助文档
查找任何文件:locate (从一个系统数据库进行文件查找,而不需要遍历磁盘,速度极快)
查找任何文件:find (需要遍历磁盘文件,因此查找速度较慢,但较丰富)
具体用法就不了吧。。。
4.29.2 查找快的原因(可以从最底层的磁盘讲起)
inode:https://www.cnblogs.com/junjind/p/8999349.html
每一个文件都有一个对应的inode。
inode:文件的元信息,比如文件的属性,创建时间,权限,所占的块大小,数量等等
文件的存储方式:
文件是存储在硬盘上的。硬盘的最小单位是扇区,每个扇区的大小为512字节。
多个扇区整合成一个块(block),一个块的大小为4k。
所以硬盘在分区的时候会分为两个区域,一个区域存放数据,一个区域存放inode信息。
这里可以提软硬链接的区别。。。
4.30 raid0与raid1的区别,raid5一块盘坏了会怎么办,具体原理
4.30.1 raid0与raid1的区别
raid 0 条带
RAID 0可以把多块硬盘连成一个容量更大的硬盘群,可以提高磁 盘的性能和吞吐量。RAID 0没有冗余或错误修复能力,成本低,要求至少两个磁盘,一般只是在那些对数 据安全性要求不高的情况下才被使用。
raid 1 镜像
把一个磁盘的数据镜像到另一个磁盘上,在不影响性能情况下最大限度的保证系统的可靠性和可修复性上,具有很高的数据冗余能力,但磁盘利用 率为1/2,故成本最高,多用在保存关键性的重要数据的场合。RAID 1的操作方式是把用户写入硬盘的数据百分之百地自动复制到另外一个硬盘上。
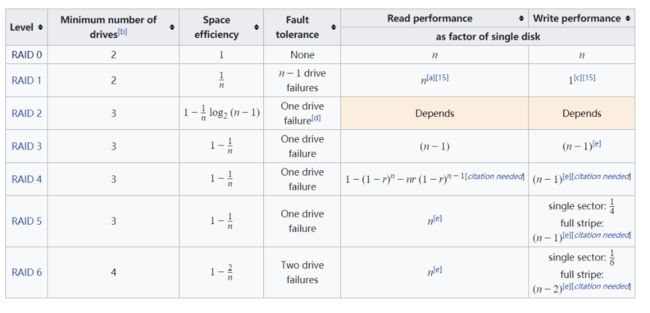
4.30.2 raid5一块盘坏,怎么处理
硬raid:拔出损坏的硬盘,插入新的硬盘
软raid:参考4.30.3
4.30.3 软raid
mdadm [模式]
- 准备磁盘或分区,以分区为例。
sdb1,2,3,5,大小200M - 使用mdadm命令创建RAID10,名称为"/dev/md0"。
mdadm -C /dev/md0 -n 4 -l 10 -a yes /dev/sdb{1,2,3,5} - 查看RAID设备信息
mdadm -D /dev/md0
损坏磁盘阵列及修复:
-
通过manage模式可以模拟阵列中的设备损坏
mdadm --manage /dev/md[0-9] [–add 设备名] [–remove 设备名] [–fail 设备名] -
模拟/dev/sdb1损坏
mdadm --manage /dev/md0 --fail /dev/sdb1 模拟sdb1损坏
查看raid状态 mdadm -D /dev/md0
由于4块磁盘组成的raid10允许损坏一块盘,且还允许坏第二块非对称盘。所以这里损坏了一块盘后raid10是可以正常工作的。
mdadm --manage /dev/md0 --remove /dev/sdb1
损坏的磁盘拔出,然后向raid中加入新的磁盘即可
mdadm --manage /dev/md0 --add /dev/sdb5
4.31 一条定时任务没有执行,有几种可能的原因
1)被执行的脚本没有执行权限:chmod 755 xxx.sh
2)被执行的脚本编码有问题,这种情况直接转码:dos2unix xxx.sh
3)crontab权限问题到/var/adm/cron/下一看,文件cron.allow和cron.deny是否存在
4.32 网卡的配置文件在哪里
/etc/sysconfig/network-scripts/ifcfg-ens33
4.33 怎样查看占用80端口的进程
1、首先查看下 80 端口的使用情况
netstat -tulnp | grep 80
查看80端口被被占用的PID
2、根据这个PID 来查看被哪个程序在使用
netstat -aux|grep PID
4.34 怎样查看系统的性能
top
sar
uptime
w
ntop
iftop
ntop
4.35 怎样看磁盘的io
几种查看磁盘io的方法:https://www.cnblogs.com/diaozhaojian/p/10497773.html
top
vmstat
iostat
4.36 awk怎样把最后一列拎出来
$NF
awk详解:https://blog.csdn.net/weixin_41477980/article/details/89511954
$0 表示整个当前行
$1 每行第一个字段
NF 字段数量变量
NR 每行的记录号,多文件记录递增
FNR 与NR类似,不过多文件记录不递增,每个文件都从1开始
\t 制表符
\n 换行符
FS BEGIN时定义分隔符
RS 输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~ 匹配,与==相比不是精确比较
!~ 不匹配,不精确比较
== 等于,必须全部相等,精确比较
!= 不等于,精确比较
&& 逻辑与
|| 逻辑或
+ 匹配时表示1个或1个以上
/[0-9][0-9]+/ 两个或两个以上数字
/[0-9][0-9]*/ 一个或一个以上数字
FILENAME 文件名
OFS 输出字段分隔符, 默认也是空格,可以改为制表符等
ORS 输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F'[:#/]' 定义三个分隔符
4.37 介绍一个w,uptime,iostat,top,ps
Linux系统负载:https://blog.csdn.net/weixin_34346099/article/details/92191458
[root@localhost ~]# w
21:54:31 up 23:05, 2 users, load average: 0.53, 0.55, 0.35
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 Thu22 23:05m 0.01s 0.01s -bash
root pts/0 192.168.217.1 Thu22 7.00s 0.15s 0.00s w
[root@localhost ~]# uptime
21:54:35 up 23:05, 2 users, load average: 0.49, 0.54, 0.35
[root@localhost ~]# iostat
Linux 3.10.0-693.el7.x86_64 (mg-nginx-02) 07/03/2020 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.11 0.00 0.10 0.05 0.00 99.73
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.40 2.52 8.03 209111 665634
scd0 0.00 0.01 0.00 1028 0
[root@localhost ~]# top
top - 21:56:26 up 23:07, 2 users, load average: 0.52, 0.60, 0.40
Tasks: 74 total, 1 running, 73 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si,
KiB Mem : 999696 total, 85896 free, 314324 used, 599476 buff/c
KiB Swap: 1048572 total, 1048572 free, 0 used. 503504 avail
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+
[root@localhost ~]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
PS
user:运行该进程的用户
PID:标志数
CPU:占用CPU百分比
MEM:占用内存百分比
VSZ:虚拟内存的大小
RSS:真实内存的大小
TTY:从哪里启动的 tty1 tty2
STAT:进程状态,S表示休眠Sleep,s表示主进程或叫父进程,<表示优先级比较高,N表示进程是低优先级,+表示是前台运行的进程,R正在运行running,L内存中被锁Lock,l多线程,Z僵尸进程,X死掉的进程,T暂停的进程,D不能中断的进程
START:启动日期
Time:一共用了CPU时间
COMMAND:进程的名称
4.38 ab web服务器性能测试
使用ab命令进行web server性能测试:https://www.cnblogs.com/leaves1024/p/10437335.html
ApacheBench 是 Apache 服务器自带的一个web压力测试工具,简称ab。**ab命令会创建多个并发访问线程,模拟多个访问者同时对某一URL地址进行访问。**它的测试目标是基于URL的,因此,既可以用来测试Apache的负载压力,也可以测试nginx、lighthttp、tomcat、IIS等其它Web服务器的压力。ab命令对发出负载的计算机要求很低,既不会占用很高CPU,也不会占用很多内存,但却会给目标服务器造成巨大的负载,可能会造成目标服务器资源耗尽,严重时可能会导致死机。
-n requests Number of requests to perform 请求总数
-c concurrency Number of multiple requests to make 并发数
-t timelimit Seconds to max. wait for responses
-b windowsize Size of TCP send/receive buffer, in bytes
4.39 查看某服务是否打开
ps aux | grep linux
lsof -i :PID
netstat -tnlp
4.40 一次性关闭某服务的所有进程
killall命令
killall命令用于终止某个指定名称的服务所对应的全部进程,格式为"killall[参数][服务名称]"。
4.41 查看进程的命令
ps:https://www.cnblogs.com/leeyongbard/p/10301206.html
top:4.21
htop:https://www.cnblogs.com/zangfans/p/8595000.html
4.42 Linux杀死僵尸进程
僵尸进程:https://www.cnblogs.com/lvcisco/p/9836701.html
4.43 文本处理/替换
4.43.1 awk文本处理
awk面试题:https://blog.51cto.com/14230436/2378328
1)处理以下⽂件内容,将域名取出并计数排序:
http://www.baidu.com/index.html
http://www.baidu.com/1.html
http://post.baidu.com/index.html
http://mp3.baidu.com/index.html
http://www.baidu.com/3.html
http://post.baidu.com/2.html
得到如下结果:
域名出现的次数 域名
3 www.baidu.com
2 post.baidu.com
1 MP3.baidu.com
如何取出?
awk -F “/” ‘{print $3}’|sort|uniq -c|sort -nr
2)统计apaceh的access.log中访问量最多的5个ip
cat access_log | awk ’{print $1}’ | sort | uniq -c | sort -nr | head -5
3)使⽤awk统计当前主机的并发访问量
netstat -ant | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,"\t",state[key]}'
4)已知文件a.txt,第一列是文件名,第二列是版本号,打印出每个文件最大的版本号一行
a.txt
file 100
dir 11
file 100
dir 11
file 102
dir 112
file 120
dir 119
测试
[root@localhost tmp]# awk '{if(code[$1]<$2) code[$1]=$2}END{for (i in code) print i,code[i] }' a.txt
dir 119
file 120
5)把2列和3列的值作为新的第5列,第5列的平均值为avg5,求第5列中大于avg5的行数。
b.txt
3 5 6 7
2 3 1 0
4 5 6 9
2 3 4 4
2 2 1 0
4 5 0 9
测试
[root@localhost tmp]# awk '{x+=$2+$3;a[NR]=$2+$3}END{y=x/NR;for(i in a){if(y
4.43.2 sed文本替换
1)把/tmp目录以及子目录下所有以扩展名为.sh结尾的文件包含old的字符串全部替换为new
find /tmp -type f -name "*.sh" | xargs sed "s/old/new/g"
2)把多行用,拼接成一行
[root@localhost tmp]#sed 'H;${x;s/\n/,/g;s/^,//};$!d' test
4.43.3 用多种方法获取一个特殊字段并计数
awk ‘{++a[$1]}END{for (i in a) print i,a[i]}’
grep -o ’ xxx’ | wc -c
4.44 系统启动流程
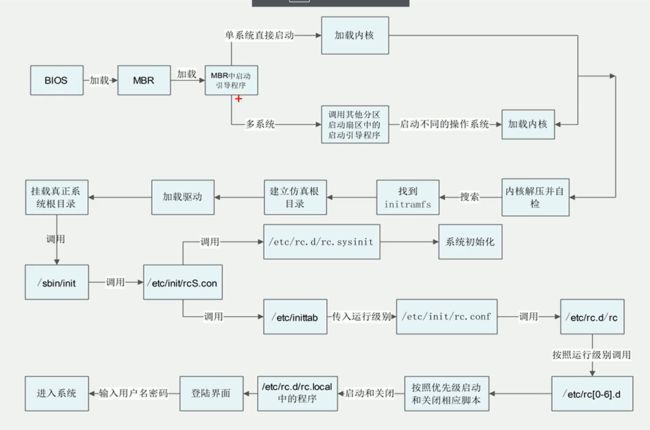
1.centos6
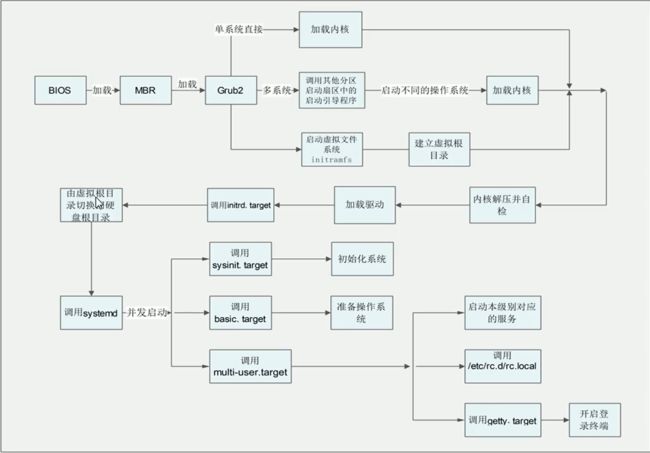
2.centos7
4.44.1 加电检查了那些外围设备,检查的顺序
POST:检查外围硬件设备是否正常,比如内存,cpu,显卡,键盘
4.44.2 bios存在的意义
Basic Input Output System
- 功能
一组固化到计算机内主板上一个ROM芯片上的程序,
它保存着计算机最重要的基本输入输出的程序、开机后自检程序和系统自启动程序,它可从CMOS中读写系统设置的具体信息。
其主要功能是为计算机提供最底层的、最直接的硬件设置和控制。
开启cpu虚拟化支持
启动项调整
4.44.3 /boot分区的内容
4.44.4 如何找到grub
删掉/boot/grub/grub.conf 配置文件,重启会自动进入grup界面
/boot/grub/grub.conf 文件内容
default=0 默认启动标题编号
timeout=5 超时时间
splashimage=(hd0,0)/grub/splash.xpm.gz 背景图片
hiddenmenu 隐藏菜单下的参数
title CentOS 6 (2.6.32-642.el6.x86_64) 标题名称 编号从0
root (hd0,0) 指定内核所在分区的物理位置 hd0,0硬盘第一个分区
kernel /vmlinuz-2.6.32-642.el6.x86_64 ro root=UUID=391fb1e7-63fc-4642-95ce-375d26494c8d rd_NO_LUKS rd_NO_LVM LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM rhgb quiet
ro 以只读方式挂载根文件系统
root=指定真正的根文件系统的位置
rhgb (redhat graphical boot)以进度条方式启动
quiet 静默模式,不显示硬件自检信息initrd /initramfs-2.6.32-642.el6.x86_64.img 提供内核初始化环境 --> 临时根文件系统
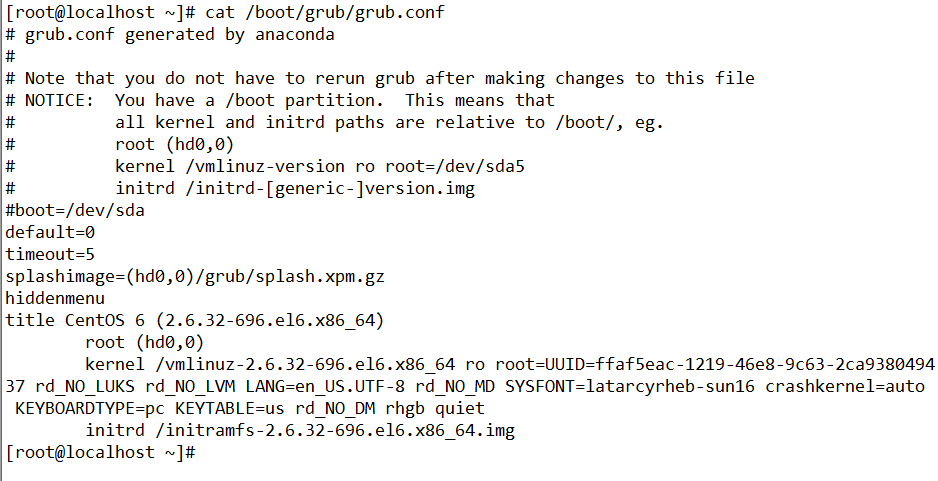
(课外扩展) 解压initramfs
4.44.5 grub和grub2的区别
GRUB 的最主要作用都是将内核加载到内存并运行。
1.配置文件的名称改变了。在grub中,配置文件为grub.conf或menu.lst(grub.conf的一个软链接),在grub2中改名为grub.cfg。
2.grub2增添了许多语法,更接近于脚本语言了,例如支持变量、条件判断、循环。
3.grub2中,设备分区名称从1开始,而在grub中是从0开始的。
4.grub2使用img文件,不再使用grub中的stage1、stage1.5和stage2。
5.支持图形界面配置grub,但要安装grub-customizer包,epel源提供该包。
6.在已进入操作系统环境下,不再提供grub命令,也就是不能进入grub交互式界面,只有在开机时才能进入。
7.在grub2中没有了好用的find命令。
4.44.6 initramfs文件的作用
1.initrd: initial Ramdisk
/linuxrc文件,基于ramdisk技术,文件系统(ext2等)镜像文件 ————> cpio格式镜像文件
在内核启动完成后把它复制到/dev/ram块设备中, 作为内核加载真正根文件系统的过渡根文件系统
2.initramfs: initial RAM file system
init文件,cpio格式镜像文件
在内核启动完成后把它复制到rootfs中,作为内核初始的根文件系统,完成挂载系统真正的根文件系统
常见的内存文件系统有:
rootfs,ramfs,ramdisk,tmpfs
1.rootfs:内核启动的初始始根文件系统,大部分linux系统正常运行后都会安装另外的文件系统,然后忽略rootfs
2.ramfs:基于内存的文件系统.ramfs文件系统没有容量大小的限制,它可以根据需要动态增加容量.直接利用了内核的磁盘高速缓存
3.ramdisk:基于ram的块设备,占据一块固定的内存,事先要使用特定的工具比如mke2fs格式化,还需要一个文件系统驱动来读写其上的文件空间固定导致容量有限,要想装入更多的文件需要重新格式化.Linux的块设备缓冲特性, ram disk上的数据被拷贝到page cache(对于文件数据)和dentry cache(对于目录项),导致内存浪费,它可能不停的动态增长直到耗尽系统的全部内存,所以只有root或授权用户允许使用ramfs
4.tmpfs:增加了容量大小的限制 + 允许把数据写入交换分区.由于增加了这两个特性,tmpfs允许普通用户使用
initramfs:https://www.cnblogs.com/CHYI1/p/5551022.html
initrd和initramfs的区别:https://blog.51cto.com/linuxzj/1409882
4.44.7 grub的各个阶段功能
分三个阶段stage1/stage1.5/stage2
这些功能都是放在/boot/grub目录下:
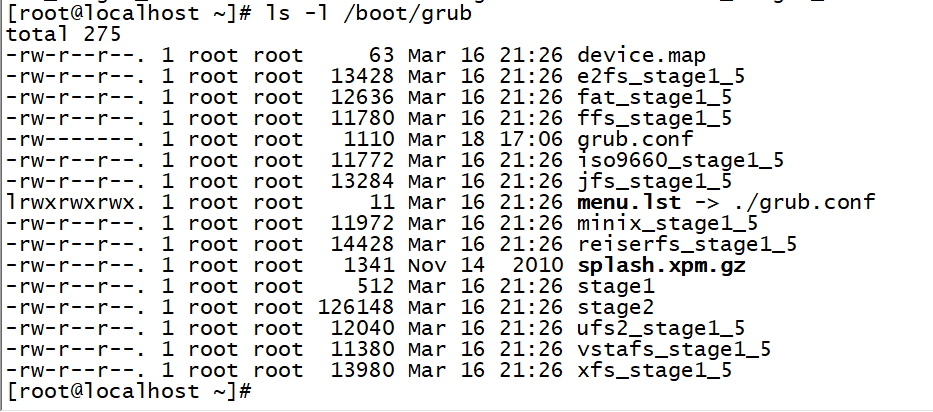
1.从上面可以看到,stage1文件的大小正好是512字节,事实上stage1文件其实就是MBR中bootloader的备份,而之所以是bootloader而不是MBR, 是因为这个文件的前446字节才是和MBR是一样的。
2.上面可以看到stage1_5形式的文件有很多,如e2fs_stage1_5、jfs_stage1_5等等,这些都是stage1.5阶段的文件,只是每个都针对不同的文件系统格式,而e2fs_stage1_5是默认的(ext系列的文件系统)。当stage1加载stage1.5之后,就访问文件系统目录,从而可以加载stage2文件。
而stage1.5要执行,是通过stage1加载它
3.平时开机启动的时候看到的Grub选项、信息,还有修改GRUB背景等功能都是stage2提供的,stage2会去读入/boot/grub/grub.conf或者menu.lst等配置文件。
4.44.8 内核是什么,功能,如何修改内核参数
- 内核的功能
进程管理
内核负责创建和销毁进程,并处理它们与外部世界的联系(输入和输出)
内存管理
内核为所有进程的每一个都在有限的可用资源上建立了一个虚拟地址空间
文件系统
内核在非结构化的硬件之上建立了一个结构化的文件系统, 结果是文件的抽象非常多地在整个系统中应用
设备控制
内核中必须嵌入系统中出现的每个外设的驱动, 从硬盘驱动到键盘和磁带驱动器
网络管理
所有的路由和地址解析问题都在内核中实现.
修改网络协议参数
/etc/sysctl.conf
1) /proc/sys/net/ipv4/icmp_echo_ignore_all
echo "1" > /proc/sys/net/ipv4/icmp_echo_ignore_all
2) 修改/etc/sysctl.conf
添加一行内容:net.ipv4.icmp_echo_ignore_all = 值
3) 立即生效
sysctl -p
Linux内核的功能:https://blog.csdn.net/u010889616/article/details/47868887
Linux修改内核的参数:https://zhuanlan.zhihu.com/p/43341587
4.45 linux如何获取对方的arp(arping)
arp:https://blog.csdn.net/qq_27627195/article/details/81942378
- arp -a
- cat /proc/net/arp
注:只有建立过连接的才能查看到对端mac,如果查找不到直接在命令行中ping一下对方ip即可查看到对方mac地址。
4.46 linux绑定双网卡,数据怎么走
双网卡bond:https://blog.csdn.net/dongfei2033/article/details/76222742
网卡bond是通过多张网卡绑定为一个逻辑网卡,实现本地网卡的冗余,带宽扩容和负载均衡,在生产场景中是一种常用的技术。
bond的模式
-
mode=0(balance-rr):表示负载分担round-robin,并且是轮询的方式比如第一个包走eth0,第二个包走eth1,直到数据包发送完毕。
-
mode=1(active-backup):表示主备模式,即同时只有1块网卡在工作。
-
mode=2(balance-xor)(平衡策略):表示XOR Hash负载分担,和交换机的聚合强制不协商方式配合。(需要xmit_hash_policy,需要交换机配置port channel)
-
mode=3(broadcast)(广播策略):表示所有包从所有网络接口发出,这个不均衡,只有冗余机制,但过于浪费资源。此模式适用于金融行业,因为他们需要高可靠性的网络,不允许出现任何问题。需要和交换机的聚合强制不协商方式配合。
-
mode=4(802.3ad)(IEEE 802.3ad 动态链接聚合):表示所有包从所有网络接口发出,这个不均衡,只有冗余机制,但过于浪费资源。此模式适用于金融行业,因为他们需要高可靠性的网络,不允许出现任何问题。需要和交换机的聚合强制不协商方式配合。
-
mode=5(balance-tlb)(适配器传输负载均衡):是根据每个slave的负载情况选择slave进行发送,接收时使用当前轮到的slave。该模式要求slave接口的网络设备驱动有某种ethtool支持;而且ARP监控不可用。
-
mode=6(balance-alb)(适配器适应性负载均衡):在5的tlb基础上增加了rlb(接收负载均衡receiveload balance).不需要任何switch(交换机)的支持。接收负载均衡是通过ARP协商实现的.
总结:mode5和mode6不需要交换机端的设置,网卡能自动聚合。mode4需要支持802.3ad。mode0,mode2和mode3理论上需要静态聚合方式。
4.47 文件权限linux 发行版本
4.47.1 文件权限
drwxr-xr-x.
十一位,
- 第1位 文件类型
- 第2~4位 拥有者
- 第5~7位 拥有组
- 第8~10位 所有人
- 第11位 acl
4.47.2 发行版本
linux 发行版一般称 GNU/linux,其中 GNU 与 linux 分别代表什么;
GNU:gnu’s not unix
gnu通用公共许可证(gnu general public license,gpl)
大致分为两类:
商业公司维护的发行版本,以著名的 Red Hat 为代表;
社区组织维护的发行版本,以 Debian 为代表。
| 版本名称 | 网 址 | 特 点 | 软件包管理器 |
|---|---|---|---|
| Debian Linux | www.debian.org | 开放的开发模式,且易于进行软件包升级 | apt |
| Fedora Core | www.redhat.com | 拥有数量庞人的用户,优秀的社区技术支持. 并且有许多创新 | up2date(rpm),yum (rpm) |
| CentOS | www.centos.org | CentOS 是一种对 RHEL(Red Hat Enterprise Linux)源代码再编译的产物,由于 Linux 是开发源代码的操作系统,并不排斥样基于源代码的再分发,CentOS 就是将商业的 Linux 操作系统 RHEL 进行源代码再编译后分发,并在 RHEL 的基础上修正了不少已知的漏洞 | rpm |
| SUSE Linux | www.suse.com | 专业的操作系统,易用的 YaST 软件包管理系统 | YaST(rpm),第三方 apt (rpm)软件库(repository) |
| Mandriva | www.mandriva.com | 操作界面友好,使用图形配置工具,有庞大的社区进行技术支持,支持 NTFS 分区的大小变更 | rpm |
| KNOPPIX | www.knoppix.com | 可以直接在 CD 上运行,具有优秀的硬件检测和适配能力,可作为系统的急救盘使用 | apt |
| Gentoo Linux | www.gentoo.org | 高度的可定制性,使用手册完整 | portage |
| Ubuntu | www.ubuntu.com | 优秀已用的桌面环境,基于 Debian 构建 | apt |
4.48 常见的http状态码
http状态码:https://blog.csdn.net/weixin_46108954/article/details/105171569
1开头的表示服务器收到请求并需要请求这继续处理;
2开头的成功响应,表示成功处理了请求;
3开头的重定向,引导浏览器跳转到另一个资源页面;
4开头表示请求出错,妨碍了服务器的处理,服务器会返回一个状态码解释到底是什么错误;
5开头的表示服务器错误,并不是请求者的原因;
常见的HTTP相应状态码
200:请求被正常处理
204:请求被受理但没有资源可以返回
206:客户端只是请求资源的一部分,服务器只对请求的部分资源执行GET方法,相应报文中通过Content-Range指定范围的资源。
301:永久性重定向
302:临时重定向
303:与302状态码有相似功能,只是它希望客户端在请求一个URI的时候,能通过GET方法重定向到另一个URI上
304:发送附带条件的请求时,条件不满足时返回,与重定向无关
307:临时重定向,与302类似,只是强制要求使用POST方法
400:请求报文语法有误,服务器无法识别
401:请求需要认证
403:请求的对应资源禁止被访问
404:服务器无法找到对应资源
500:服务器内部错误
503:服务器正忙
499 client has closed connection:这很有可能是因为服务器端处理的时间过长,客户端“不耐烦”了。
4.49 netstat常见的选项
[root@localhost ~]# netstat --help
usage: netstat [-vWeenNcCF] [] -r netstat {-V|--version|-h|--help}
netstat [-vWnNcaeol] [ ...]
netstat { [-vWeenNac] -I[] | [-veenNac] -i | [-cnNe] -M | -s [-6tuw] } [delay]
-r, --route display routing table
-I, --interfaces= display interface table for
-i, --interfaces display interface table
-g, --groups display multicast group memberships
-s, --statistics display networking statistics (like SNMP)
-M, --masquerade display masqueraded connections
-v, --verbose be verbose
-W, --wide don't truncate IP addresses
-n, --numeric don't resolve names
--numeric-hosts don't resolve host names
--numeric-ports don't resolve port names
--numeric-users don't resolve user names
-N, --symbolic resolve hardware names
-e, --extend display other/more information
-p, --programs display PID/Program name for sockets
-o, --timers display timers
-c, --continuous continuous listing
-l, --listening display listening server sockets
-a, --all display all sockets (default: connected)
-F, --fib display Forwarding Information Base (default)
-C, --cache display routing cache instead of FIB
-Z, --context display SELinux security context for sockets
={-t|--tcp} {-u|--udp} {-U|--udplite} {-S|--sctp} {-w|--raw}
{-x|--unix} --ax25 --ipx --netrom
=Use '-6|-4' or '-A ' or '--'; default: inet
List of possible address families (which support routing):
inet (DARPA Internet) inet6 (IPv6) ax25 (AMPR AX.25)
netrom (AMPR NET/ROM) ipx (Novell IPX) ddp (Appletalk DDP)
x25 (CCITT X.25)
tulnp
ant
4.50 维护一个系统的安全有哪几方面
linux安全配置:https://wenku.baidu.com/view/b84eaf87b9d528ea81c7790d.html
-
用户管理:删除默认创建的一些用户/用户组
-
服务管理:升级服务软件版本,关闭系统不使用的服务
-
系统文件权限:修改部分系统文件的权限
-
系统优化:虚拟内存优化
-
日志管理:系统引导/运行/操作日志
-
防火墙:iptables四表五链 firewalld
4.51 linux常用的分区格式
ext2
ext3
ext4
xfs
jfs
btrfs
文件系统比较:https://wenku.baidu.com/view/4c18863543323968011c92f7.html
大小:KB,MB,GB,TB,PB,EB,ZB
| 文件系统 | 最大卷容量 | 最大文件容量 | 目录结构 | 文件分配 | ACLS | checksum | 透明压缩 | 透明加密 | online defrag | shrink | 特性 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| btrfs | 16EB | 16EB | B tree | extents | Yes | Yes | Yes | No | Yes | Yes | SSD |
| ext3 | 32TB | 2TB | list/tree | bitmap/table | Yes | No | No | No | No | Yes | |
| ext4 | 1EB | 16TB | list/Htree | bitmap/extents | Yes | journal | No | No | Yes | Yes | |
| jfs | 32PB | 4PB | B tree | bitmap/extents | Yes | No | No | No | Yes | No | |
| reiserfs | 16TB | 8TB | B+ tree | bitmap | No | No | No | No | No | offline resize | |
| reiser4 | 8TB | dancing B* tree | No | No | Plugin | Plugin | Yes | offline | |||
| xfs | 16EB | 8EB | B+ tree | extents | Yes | No | No | No | Yes | No | |
| ntfs | 256TB | 16TB | B+ tree | bitmap | ACLS only | No | Yes | Yes | Yes | Yes | Stream |
| zfs | 16EB | 16EB | hash table | Yes | Yes | Yes | Yes | Yes | No |
4.52 PYTHON
4.52.1 python的内存回收机制
垃圾回收机制:https://blog.csdn.net/xiongchengluo1129/article/details/80462651
垃圾回收机制详解:https://www.jianshu.com/p/1e375fb40506
python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
引用计数法的原理是每个对象维护一个ob_ref,用来记录当前对象被引用的次数,也就是来追踪到底有多少引用指向了这个对象,当发生以下四种情况的时候,该对象的引用计数器+1
- 对象被创建 a=14
- 对象被引用 b=a
- 对象被作为参数,传到函数中 func(a)
- 对象作为一个元素,存储在容器中 List={a,”a”,”b”,2}
与上述情况相对应,当发生以下四种情况时,该对象的引用计数器-1
- 当该对象的别名被显式销毁时 del a
- 当该对象的引别名被赋予新的对象, a=26
- 一个对象离开它的作用域,例如 func函数执行完毕时,函数里面的局部变量的引用计数器就会减一(但是全局变量不会)
- 将该元素从容器中删除时,或者容器被销毁时。
注:当指向该对象的内存的引用计数器为0的时候,该内存将会被Python虚拟机销毁。
GC系统的主要任务:
- 为新生成的对象分配内存
- 识别那些垃圾对象
- 从垃圾对象那回收内存。
4.52.2 python中+=
-
两个值相加,然后返回值给符号左侧的变量
-
用于字符串连接(变量值带引号,数据类型为字符串)
4.52.3 元组与列表的区别
python列表元组区别:https://www.jianshu.com/p/f40f095f4e20
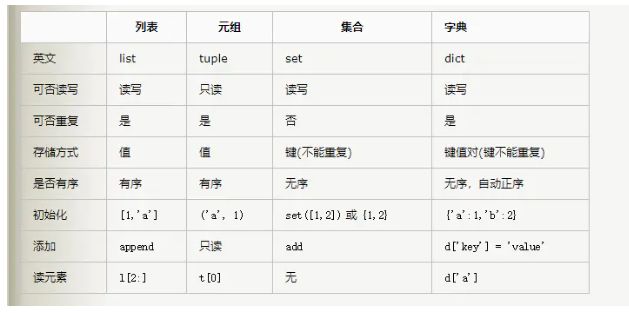
(1)列表:一个大仓库,你可以随时往里边添加和删除任何东西。
(2)元组:封闭的列表,一旦定义,就不可改变(不能添加、删除或修改)只读。
注:都可以使用下标索引来访问元组中的值
4.52.4 python中有哪些复制的方式
深浅拷贝:https://blog.csdn.net/qq_39290225/article/details/90451324
其他复制方式:https://blog.csdn.net/weixin_43305880/article/details/82891465?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
深浅拷贝的区别:https://blog.csdn.net/weixin_40576010/article/details/88848189
>>> import copy
>>> a = [[10], 20]
>>> b = a[:] #<---切片复制
>>> c = list(a) #<---构造函数
>>> d = a * 1 #<---乘一赋值
>>> e = a.copy() #<---copy方法
>>> f = copy.deepcopy(a) #<---deepcopy函数
>>> a.append(21)
>>> a[0].append(11)
>>> for i in (a,b,c,d,e,f):
... print(id(i),id(i[0]),i)
...
1827373681032 1827374668936 [[10, 11], 20, 21]
1827372347144 1827374668936 [[10, 11], 20]
1827373679752 1827374668936 [[10, 11], 20]
1827373674184 1827374668936 [[10, 11], 20]
1827373668744 1827374668936 [[10, 11], 20]
1827376420168 1827372453448 [[10], 20]
注:只有使用copy.deepcopy(a)方法得到的新列表f才是包括子列表在内的完全复制。
4.52.5 Django的模块使用情况
Django:https://www.cnblogs.com/ssyfj/p/9087545.html
Django应用:https://blog.csdn.net/lftaoyuan/article/details/79014251
from django.contrib.auth import authenticate,login,logout #可以用来做登录验证
from django.contrib.auth.decorators import login_required #装饰器,用于对用户是否登录进行验证
Django教程:https://www.liujiangblog.com/course/django/2
Django教程:https://code.ziqiangxuetang.com/django/django-tutorial.html
Django教程:https://www.runoob.com/django/django-tutorial.html
4.52.6 Python和shell的区别
Python和shell的区别 :https://www.cnblogs.com/chengjian-physique/p/9152988.html
Python和shell的思考:https://blog.csdn.net/monkey_d_meng/article/details/6173055
python定义和使用只需要使用变量名
shell定义变量只需要变量名,而使用变量的值则需要加$符号
python中没有数组的概念,但是有list,tuple,dict等可以代替其功能
shell中只有一维数组
4.52.7 python的常见数据类型
数据类型详解:https://blog.csdn.net/aurora_1970s/article/details/105519821
1.数字类型:整型(int),浮点型(float),复数类型(complex)
2.字符串类型:str
3.逻辑类型:bool True False
4.列表类型:list [ ] 有序可修改
5.元组类型:tuple () 有序不可修改
6.集合类型:set { } 无序不重复
7.字典类型:dict {key:value} 无序
五、数据库知识
5.1 部署数据库的整一个流程
5.1.1 安装
1)源码安装:
1.安装依赖
2.安装cmake、编译mysql
3.初始化mysql(mysql_install_db)
4.启动mysql服务
2)二进制安装:
1.创建用户、目录,修改权限
2.下载mysql.tar.gz,解压
3.配置my.cnf文件
4.初始化mysql(mysqld --initialize)
5.进入mysql修改密码
5.1.2 部署多实例
1.创建多实例目录
2.在不同的实例目录中编辑my.cnf
3.初始化数据文件
4.启动mysql多实例
5.登录到mysql多实例
6.关闭mysql多实例
5.1.3 主从复制
1.master开启binlog
并添加不同的server-id=101
2.创建用户并授权
show master status;
3.主库全量备份
4.从库做全量恢复
5.从库设定主库信息
6.从库开启主从复制
show slave status\G
5.2 数据库大数据类型
| 数据类型 | 含义(有符号) |
|---|---|
| int(m) | 4个字节 范围(-2147483648~2147483647) |
| float(m,d) | 单精度浮点型 8位精度(4字节) m总个数,d小数位 |
| double(m,d) | 双精度浮点型 16位精度(8字节) m总个数,d小数位 |
| decimal(m,d) | 参数m<65 是总个数,d<30且 d |
| char(n) | 固定长度,最多255个字符 |
| varchar(n) | 可变长度,最多65535个字节 |
5.3 数据库存储引擎
mysql的存储引擎包括:MyISAM、 InnoDB、BDB、MEMORY、MERGE、EXAMPLE、NDB Cluster、ARCHIVE、CSV、BLACKHOLE、FEDERATED等,其中InnoDB和BDB提供事务安全表,其他存储引擎都是非事务安全表。
| 特点 | MYISAM | BDB | MEMORY | INNODB | ARCHIVE |
|---|---|---|---|---|---|
| 存储限制 | 没有 | 没有 | 有 | 64TB | 没有 |
| 事务安全 | 支持 | 支持 | |||
| 锁机制 | 表锁 | 页锁 | 表锁 | 行锁 | 行锁 |
| B树索引 | 支持 | 支持 | 支持 | 支持 | |
| 哈希索引 | 支持 | 支持 | |||
| 全文索引 | 支持 | ||||
| 集群索引 | 支持 | ||||
| 数据缓存 | 支持 | 支持 | |||
| 索引缓存 | 支持 | 支持 | 支持 | ||
| 数据可压缩 | 支持 | 支持 | |||
| 空间使用 | 低 | 低 | N/A | 高 | 非常低 |
| 内存使用 | 低 | 低 | 中等 | 高 | 低 |
| 批量插入的速度 | 高 | 高 | 高 | 高 | 非常高 |
| 支持外键 |
innodb和myisam的主要区别
1、事务的支持不同
innodb支持事务
myisam不支持事务
2、锁粒度
innodb行锁
myisam表锁
3、存储空间
innodb既缓存索引文件又缓存数据文件
myisam只能缓存索引文件
4、存储结构
(myisam:数据文件的扩展名为.MYD myData ,索引文件的扩展名是.MYI myIndex)
(innodb:所有的表都保存在同一个数据文件里面 即为.Ibd)
5、统计记录行数
(myisam:保存有表的总行数,select count() from table;会直接取出出该值)
(innodb:没有保存表的总行数,select count() from table;就会遍历整个表,消耗相当大)
5.4 索引
索引进阶:https://blog.csdn.net/q402057192/article/details/87695498
1.索引是什么?有什么作用?
索引是对数据库表中一个或多个列的值进行排序的数据结构,以协助快速查询、更新数据库表中数据。索引的实现通常使用B_TREE及其变种。索引加速了数据访问,因为存储引擎不会再去扫描整张表得到需要的数据;相反,它从根节点开始,根节点保存了子节点的指针,存储引擎会根据指针快速寻找数据。
2.索引的优缺点
优点:
- 大大加快数据的检索速度,这也是创建索引的最主要的原因;
- 加速表和表之间的连接;
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间;
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性;
缺点:
-
时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度;
-
空间方面:索引需要占物理空间。
3.为什么说B+tree比B 树更适合实际应用中操作系统的文件索引和数据库索引
- B+tree的磁盘读写代价更低:B+tree的内部结点并没有指向关键字具体信息的指针(红色部分),因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多,相对来说IO读写次数也就降低了;
- B+tree的查询效率更加稳定:由于内部结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引,所以,任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当;
- 数据库索引采用B+树而不是B树的主要原因:B+树只要遍历叶子节点就可以实现整棵树的遍历,而且在数据库中基于范围的查询是非常频繁的,而B树只能中序遍历所有节点,效率太低。
4.什么情况下设置了索引但无法使用?
-
以“%(表示任意0个或多个字符)”开头的LIKE语句,模糊匹配;
-
OR语句前后没有同时使用索引;
-
数据类型出现隐式转化(如varchar不加单引号的话可能会自动转换为int型);
-
对于多列索引,必须满足 最左匹配原则 (eg:多列索引col1、col2和col3,则 索引生效的情形包括 col1或col1,col2或col1,col2,col3)
5.什么样的字段适合创建索引?
- 经常作查询选择的字段
- 经常作表连接的字段
- 经常出现在order by, group by, distinct 后面的字段
6.创建索引时需要注意什么?
- 非空字段:应该指定列为NOT NULL,除非你想存储NULL。在mysql中,含有空值的列很难进行查询优化,因为它们使得索引、索引的统计信息以及比较运算更加复杂。你应该用0、一个特殊的值或者一个空串代替空值;
- 取值离散大的字段:(变量各个取值之间的差异程度)的列放到联合索引的前面,可以通过count()函数查看字段的差异值,返回值越大说明字段的唯一值越多字段的离散程度高;
- 索引字段越小越好:数据库的数据存储以页为单位一页存储的数据越多一次IO操作获取的数据越大效率越高。
5.5 SQL查询语句的优化
1、在表中建立索引,优先考虑where、group by使用到的字段。
2、尽量避免使用select *,返回无用的字段会降低查询效率。如下:
SELECT * FROM t
优化方式:使用具体的字段代替*,只返回使用到的字段。
3、尽量避免使用in 和not in,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id IN (2,3)
SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)
4、尽量避免使用or,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3
(PS:如果or两边的字段是同一个,如例子中这样。貌似两种方式效率差不多,即使union扫描的是索引,or扫描的是全表)
5、尽量避免在字段开头模糊查询,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE username LIKE ‘%li%’
优化方式:尽量在字段后面使用模糊查询。如下:
SELECT * FROM t WHERE username LIKE ‘li%’
6、尽量避免进行null值的判断,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
7、尽量避免在where条件中等号的左侧进行表达式、函数操作,会导致数据库引擎放弃索引进行全表扫描。如下:
SELECT * FROM t2 WHERE score/10 = 9
SELECT * FROM t2 WHERE SUBSTR(username,1,2) = ‘li’
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT * FROM t2 WHERE score = 10*9
SELECT * FROM t2 WHERE username LIKE ‘li%’
8、当数据量大时,避免使用where 1=1的条件。通常为了方便拼装查询条件,我们会默认使用该条件,数据库引擎会放弃索引进行全表扫描。如下:
SELECT * FROM t WHERE 1=1
优化方式:用代码拼装sql时进行判断,没where加where,有where加and。
5.6 数据库触发器
创建触发器。创建触发器语法如下:
CREATE TRIGGER trigger_name trigger_time trigger_event
ON tbl_name FOR EACH ROW trigger_stmt
其中trigger_name标识触发器名称,用户自行指定;
trigger_time标识触发时机,用before和after替换;
trigger_event标识触发事件,用insert,update和delete替换;
tbl_name标识建立触发器的表名,即在哪张表上建立触发器;
trigger_stmt是触发器程序体;触发器程序可以使用begin和end作为开始和结束,中间包含多条语句;
例子
CREATE TRIGGER trig_insert_user
AFTER INSERT
ON test.student FOR EACH ROW
BEGIN
INSERT into test.user set username=NEW.name;
END
5.7 当创建好一个数据库,都生成了哪些文件,这些文件的本质是什么
oracle:https://docs.oracle.com/cd/E11882_01/server.112/e25494/create.htm#ADMIN11085
Oracle数据库至少执行以下操作:
- 为数据库创建数据文件
- 创建数据库的控制文件
- 为数据库创建重做日志文件并建立
ARCHIVELOG模式 - 创建
SYSTEM表空间 - 创建
SYSAUX表空间 - 创建数据字典
- 设置将数据存储在数据库中的字符集
- 设置数据库时区
- 挂载并打开数据库以供使用
mysql
有一个DatabaseName文件夹
接着创建TableName表的话会有三个文件 db.opt 文件、TableName.frm 文件、TableName .idb文件
db.opt 文件:字符集与排序规则信息
TableName.frm 文件:整个表框架的定义,但是它保存的是密文
TableName .idb文件:表中的数据
5.8 MySQL主从不一致出现报错要怎么解决,简历主从的命令是什么
MySQL主从不同步问题分析与处理思路:http://blog.itpub.net/31015730/viewspace-2154414/
mysql主从同步梳理:https://www.cnblogs.com/kevingrace/p/6261111.html
5.8.1 slave运行过慢不能与master同步,也就是MySQL数据库主从同步延迟
MySQL数据库slave服务器延迟的现象是非常普遍的,MySQL复制允许从机进行SELECT操作,但是在实际生产环境下,由于从机延迟的关系,很难将读取操作转向到从机。这就导致了有了以下一些潜规则:“实时性要求不高的读取操作可以放到slave服务器,实时性要求高的读取操作放到master服务器”,“从机仅能做前一天的统计类查询”。
slave滞后即slave不能快速执行来自于master的所有事件,从而不能避免更新slave数据延迟。
mysql的master-slave架构中master仅做写入、更新、删除操作,slave做select操作。造成slave滞后的原因有很多。
slave同步延迟的原理
MySQL的主从复制都是单线程的操作,主库对所有DDL和DML产生的日志写进binlog,由于binlog是顺序写,所以效率很高。
Slave的IO Thread线程从主库中bin log中读取取日志。
Slave的SQL Thread线程将主库的DDL和DML操作事件在slave中重放。DML和DDL的IO操作是随机的,不是顺序的,成本高很多。
由于SQL Thread也是单线程的,如果slave上的其他查询产生lock争用,又或者一个DML语句(大事务、大查询)执行了几分钟卡住了,那么所有之后的DML会等待这个DML执行完才会继续执行,这就导致了延时。那么:主库上那个相同的DDL也会执行几分钟,为什么slave会延时?原因是master可以并发执行,而Slave_SQL_Running线程却不可以。
slave同步延迟的可能原因
1–slave的I/O线程推迟读取日志中的事件信息;最常见原因是slave是在单线程中执行所有事务,而master有很多线程可以并行执行事务。
2–带来低效连接的长查询、磁盘读取的I/O限制、锁竞争和innodb线程同步启动等。
3–Master负载;Slave负载
4–网络延迟
5–机器配置(cpu、内存、硬盘)
(主从同步延迟怎么产生的?)总之,当主库的TPS并发较高时,产生的DDL数量超过slave一个sql线程所能处理的承受范围时,主从同步就会产生延时;或者当slave中有大型query语句产生了锁等待也会产生延时。
如何查看同步延迟
1–可以通过比对master、slave上的日志位置
2–通过"show slave status\G"查看Seconds_Behind_Master的值,这个值代表主从同步延迟的时间,值越大说明延迟越严重。值为0为正常情况,正值表示已经出现延迟,数字越大从库落后主库越多。
3–使用percona-toolkit的pt-hearbeat工具进行查看。
减少同步延迟的操作方案
1–减少锁竞争
如果查询导致大量的表锁定,需要考虑重构查询语句,尽量避免过多的锁。
2–负载均衡
搭建多少slave,并且使用lvs或nginx进行查询负载均衡,可以减少每个slave执行查询的次数和时间,从而将更多的时间用于去处理主从同步。
3–salve较高的机器配置
4–slave调整参数
为了保障较高的数据安全性,配置sync_binlog=1,innodb_flush_log_at_trx_commit=1等设置。而Slave可以关闭binlog,innodb_flush_log_at_trx_commit也可以设置为0来提高sql的执行效率(这两个参数很管用)
5–并行复制
即将单线程的复制改成多线程复制。
从库有两个线程与复制相关:io_thread 负责从主库拿binlog并写到relaylog, sql_thread 负责读relaylog并执行。
多线程的思路就是把sql_thread 变成分发线程,然后由一组worker_thread来负责执行。
几乎所有的并行复制都是这个思路,有不同的,便是sql_thread 的分发策略。
MySQL5.7的真正并行复制enhanced multi-threaded slave(MTS)很好的解决了主从同步复制的延迟问题。
5.8.2 slave同步状态中出现Slave_IO_Running: NO
报错:Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ‘Could not find first log file name in binary log index file’
原因1:清理数据导致主从库不同步(前提是主库的binlog日志没有被暴力删除或错误删除,即要确保正在使用的那个最新binlog文件在master主库机器上存在)。
解决办法:
1)先进入slave中执行:"slave stop;"来停止从库同步;
2)再去master中执行:"flush logs;"来清空日志;
3)然后在master中执行:"show master status;"查看下主库的状态,主要是日志的文件和position;
4)然后回到slave中,执行:"CHANGE MASTER TO …执行同步指令
原因2:该错误发生在从库的io进程从主库拉取日志时,发现主库的mysql_bin.index文件中第一个文件不存在。出现此类报错可能是由于你的slave 由于某种原因停止了好长一段时间,当你重启slave 复制的时候,在主库上找不到相应的binlog ,会报此类错误。或者是由于某些设置主库上的binlog被删除了,导致从库获取不到对应的binglog file。
解决办法:
1)为了避免数据丢失,需要重新进行slave同步操作。
2)注意主库binlog的清理策略,选择基于时间过期的删除方式还是基于空间利用率的删除方式。
3)记住最好不要使用"rm -rf"命令删除binlog file,这样不会同步修改mysql_bin.index 记录的binlog 条目。在删除binlog的时候确保主库保留了从库"show slave status\G"的Relay_Master_Log_File对应的binlog file。任何时候都不能删除正在使用的那个最新binlog文件;最好把bin-log文件不要删除,最好给备份出来。
5.8.3 slave同步状态中出现Slave_IO_Running: Connecting
导致这个错误的原因一般是:
1–网络不通
2–权限问题(连接master的用户名和密码跟master授权不一致)
3–连接时用的log file和pos节点跟"show master status"的结果不一致
5.8.4 slave中继日志relay-log损坏
什么是中继日志?
relay-log存放在从服务器上,从服务器将主服务器的二进制日志文件拷贝到自己的主机上放在中继日志中,然后调用SQL线程按照拷中继日志文件中的二进制日志文件执行以便就可达到数据的同步 。
如何避免中继日损坏:
mysql 5.6版本后,在my.cnf文件中开启relay_log_recover=1即可避免。
5.8.5 slave连接超时且重新连接频繁
若有多个slave,且没有设置server_id或两个slave设置相同的server_id,将有可能会出现服务器的ID冲突。这种情况下,其中一台slave可能会频繁超时或丢失后重新连接序列。
所以一定要确保每台slave及master在my.cnf中都要设置不一样的server_id。
5.8.6 在master更新一条记录,而slave却找不到
主从数据不致时,master有某条记录,但在salve上没有这条记录,若在master上进行更新这条记录,则在slave中可能报错。
解决方法:
1–根据从库发生异常的位置,查主库上的二进制日志。
2–根据主库二进制日志信息,找到更新后的整条记录。
3–在从库上执行在主库上找到的记录信息,进行insert操作。
4–跳过这条语句,再同步slave。
5–使用pt-table-checksum查看主从库表数据否一致。
pt-table-checksum:https://blog.csdn.net/jswangchang/article/details/79501553
pt-table-checksum原理:https://segmentfault.com/a/1190000004309169
percona-toolkit梳理:https://www.cnblogs.com/kevingrace/p/6261091.html
原理是在主库执行基于statement的sql语句来生成主库数据块的checksum,把相同的sql语句传递到从库执行,并在从库上计算相同数据块的checksum,最后,比较主从库上相同数据块的checksum值,由此判断主从数据是否一致。检测过程根据唯一索引将表按row切分为块(chunk),以为单位计算,可以避免锁表。检测时会自动判断复制延迟、 master的负载, 超过阀值后会自动将检测暂停,减小对线上服务的影响。
percona-toolkit系列工具中的一个
-
pt-table-checksum只校验,然后把结果存储到表,执行过的sql语句记录到binlog。不在意从库延时,延迟多少,计算的校验值都一样;
-
pt-table-sync首先完成chunk的checksum计算,如果数据不一致,则深入到chunk内部,进行逐行比较,并修复。
-
pt-heartbeat 负责监控mysql主从同步延迟
5.8.7 mysql主从同步(跨机房情况)不一致问题
1) 网络的延迟
由于mysql主从复制是基于binlog的一种异步复制,通过网络传送binlog文件,理所当然网络延迟是主从不同步的绝大多数的原因,特别是跨机房的数据同步出现这种几率非常的大,所以做读写分离,注意从业务层进行前期设计。
2) 主从两台机器的负载不一致
由于mysql主从复制是主数据库上面启动1个io线程,而从上面启动1个sql线程和1个io线程,当中任何一台机器的负载很高,忙不过来,导致其中的任何一个线程出现资源不足,都将出现主从不一致的情况。
3) max_allowed_packet设置不一致
主数据库上面设置的max_allowed_packet比从数据库大,当一个大的sql语句,能在主数据库上面执行完毕,从数据库上面设置过小,无法执行,导致的主从不一致。
4) key自增键开始的键值跟自增步长设置不一致引起的主从不一致。
5) mysql异常宕机情况下,如果未设置sync_binlog=1或者innodb_flush_log_at_trx_commit=1很有可能出现binlog或者relaylog文件出现损坏,导致主从不一致。
6) mysql本身的bug引起的主从不同步。
7) 版本不一致,特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面不支持该功能。
5.9 查看Mysql发现查询特别慢,可能的原因,对于慢查询,你的分析思路
查询慢的原因:https://www.jb51.net/article/170953.htm
5.9.1 查询速度慢的原因
查询速度慢的原因很多,常见如下几种:
1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)
2、I/O吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足
5、网络速度慢
6、查询出的数据量过大(可以采用多次查询,其他的方法降低数据量)
7、锁或者死锁(这也是查询慢最常见的问题,是程序设计的缺陷)
8、sp_lock,sp_who,活动的用户查看,原因是读写竞争资源。
9、返回了不必要的行和列
10、查询语句不好,没有优化
5.9.2 查询优化
可以通过如下方法来优化查询 :
1、把数据、日志、索引放到不同的I/O设备上,增加读取速度,以前可以将Tempdb应放在RAID0上,SQL2000不在支持。数据量(尺寸)越大,提高I/O越重要.
2、纵向、横向分割表,减少表的尺寸(sp_spaceuse)
3、升级硬件
4、根据查询条件,建立索引,优化索引、优化访问方式,限制结果集的数据量。注意填充因子要适当(最好是使用默认值0)。索引应该尽量小,使用字节数小的列建索引好(参照索引的创建),不要对有限的几个值的字段建单一索引如性别字段
5、提高网速;
6、扩大服务器的内存,Windows 2000和SQL server 2000能支持4-8G的内存。配置虚拟内存:虚拟内存大小应基于计算机上并发运行的服务进行配置。运行 Microsoft SQL Server? 2000 时,可考虑将虚拟内存大小设置为计算机中安装的物理内存的 1.5 倍。如果另外安装了全文检索功能,并打算运行 Microsoft 搜索服务以便执行全文索引和查询,可考虑:将虚拟内存大小配置为至少是计算机中安装的物理内存的 3 倍。将 SQL Server max server memory 服务器配置选项配置为物理内存的 1.5 倍(虚拟内存大小设置的一半)。
7、增加服务器CPU个数;但是必须明白并行处理比串行处理更需要资源例如内存。使用并行还是串行程是MsSQL自动评估选择的。单个任务分解成多个任务,就可以在处理器上运行。例如耽搁查询的排序、连接、扫描和GROUP BY字句同时执行,SQL SERVER根据系统的负载情况决定最优的并行等级,复杂的需要消耗大量的CPU的查询最适合并行处理。但是更新操作UPDATE,INSERT,DELETE还不能并行处理。
8、如果是使用like进行查询的话,简单的使用index是不行的,而且全文索引耗空间。 like ‘a%’ 使用索引 like ‘%a’ 不使用索引用 like ‘%a%’ 查询时,查询耗时和字段值总长度成正比,所以不能用CHAR类型,而是VARCHAR。对于字段的值很长的建全文索引。
9、DB Server 和APPLication Server 分离;OLTP和OLAP分离
10、分布式分区视图可用于实现数据库服务器联合体。联合体是一组分开管理的服务器,但它们相互协作分担系统的处理负荷。这种通过分区数据形成数据库服务器联合体的机制能够扩大一组服务器,以支持大型的多层 Web 站点的处理需要。有关更多信息,参见设计联合数据库服务器。(参照SQL帮助文件’分区视图’)
a、在实现分区视图之前,必须先水平分区表
b、在创建成员表后,在每个成员服务器上定义一个分布式分区视图,并且每个视图具有相同的名称。这样,引用分布式分区视图名的查询可以在任何一个成员服务器上运行。系统操作如同每个成员服务器上都有一个原始表的复本一样,但其实每个服务器上只有一个成员表和一个分布式分区视图。数据的位置对应用程序是透明的。
11、重建索引 DBCC REINDEX ,DBCC INDEXDEFRAG,收缩数据和日志 DBCC SHRINKDB,DBCC SHRINKFILE. 设置自动收缩日志.对于大的数据库不要设置数据库自动增长,它会降低服务器的性能。 在T-sql的写法上有很大的讲究,下面列出常见的要点:首先,DBMS处理查询计划的过程是这样的:
1)查询语句的词法、语法检查
2)将语句提交给DBMS的查询优化器
3)优化器做代数优化和存取路径的优化
4)由预编译模块生成查询规划
5)然后在合适的时间提交给系统处理执行
6)最后将执行结果返回给用户其次,看一下SQL SERVER的数据存放的结构:一个页面的大小为8K(8060)字节,8个页面为一个盘区,按照B树存放。
12、Commit和rollback的区别 Rollback:回滚所有的事物。 Commit:提交当前的事物. 没有必要在动态SQL里写事物,如果要写请写在外面如: begin tran exec(@s) commit trans 或者将动态SQL 写成函数或者存储过程。
13、在查询Select语句中用Where字句限制返回的行数,避免表扫描,如果返回不必要的数据,浪费了服务器的I/O资源,加重了网络的负担降低性能。如果表很大,在表扫描的期间将表锁住,禁止其他的联接访问表,后果严重。
14、SQL的注释申明对执行没有任何影响
15、尽可能不使用光标,它占用大量的资源。如果需要row-by-row地执行,尽量采用非光标技术,如:在客户端循环,用临时表,Table变量,用子查询,用Case语句等等。
16、用Profiler来跟踪查询,得到查询所需的时间,找出SQL的问题所在;用索引优化器优化索引
17、注意UNion和UNion all 的区别。UNION all好
18、注意使用DISTINCT,在没有必要时不要用,它同UNION一样会使查询变慢。重复的记录在查询里是没有问题的
19、查询时不要返回不需要的行、列
20、用sp_configure 'query governor cost limit’或者SET QUERY_GOVERNOR_COST_LIMIT来限制查询消耗的资源。当评估查询消耗的资源超出限制时,服务器自动取消查询,在查询之前就扼杀掉。SET LOCKTIME设置锁的时间
21、用select top 100 / 10 Percent 来限制用户返回的行数或者SET ROWCOUNT来限制操作的行
22、在SQL2000以前,一般不要用如下的字句: “IS NULL”, “<>”, “!=”, “!>”, “!<”, “NOT”, “NOT EXISTS”, “NOT IN”, “NOT LIKE”, and “LIKE ‘%500’”,因为他们不走索引全是表扫描。也不要在WHere字句中的列名加函数,如Convert,substring等,如果必须用函数的时候,创建计算列再创建索引来替代.还可以变通写法:WHERE SUBSTRING(firstname,1,1) = 'm’改为WHERE firstname like ‘m%’(索引扫描),一定要将函数和列名分开。并且索引不能建得太多和太大。NOT IN会多次扫描表,使用EXISTS、NOT EXISTS ,IN , LEFT OUTER JOIN 来替代,特别是左连接,而Exists比IN更快,最慢的是NOT操作.如果列的值含有空,以前它的索引不起作用。相同的是IS NULL,“NOT”, “NOT EXISTS”, “NOT IN"能优化她,而”<>"等还是不能优化,用不到索引。
23、使用Query Analyzer,查看SQL语句的查询计划和评估分析是否是优化的SQL。一般的20%的代码占据了80%的资源,我们优化的重点是这些慢的地方。
24、如果使用了IN或者OR等时发现查询没有走索引,使用显示申明指定索引:
SELECT * FROM PersonMember (INDEX = IX_Title) WHERE processid IN (‘男’,‘女’)
25、将需要查询的结果预先计算好放在表中,查询的时候再SELECT。
26、MIN() 和 MAX()能使用到合适的索引。
27、数据库有一个原则是代码离数据越近越好,所以优先选择Default,依次为Rules,Triggers, Constraint(约束如外健主健CheckUNIQUE……,数据类型的最大长度等等都是约束),Procedure.这样不仅维护工作小,编写程序质量高,并且执行的速度快。
28、如果要插入大的二进制值到Image列,使用存储过程,千万不要用内嵌INsert来插入(不知JAVA是否)。因为这样应用程序首先将二进制值转换成字符串(尺寸是它的两倍),服务器受到字符后又将他转换成二进制值.存储过程就没有这些动作: 方法:
Create procedure p_insert as insert into table(Fimage) values (@image)
在前台调用这个存储过程传入二进制参数,这样处理速度明显改善。
29、Between在某些时候比IN速度更快,Between能够更快地根据索引找到范围。用查询优化器可见到差别。
select * from chineseresume where title in (‘男’,‘女’)
Select * from chineseresume where title between ‘男’ and ‘女’
30、在必要是对全局或者局部临时表创建索引,有时能够提高速度,但不是一定会这样,因为索引也耗费大量的资源。他的创建同是实际表一样。
31、不要建没有作用的事物例如产生报表时,浪费资源。只有在必要使用事物时使用它。
32、用OR的字句可以分解成多个查询,并且通过UNION 连接多个查询。他们的速度只同是否使用索引有关,如果查询需要用到联合索引,用UNION all执行的效率更高.多个OR的字句没有用到索引,改写成UNION的形式再试图与索引匹配。一个关键的问题是否用到索引。
33、尽量少用视图,它的效率低。对视图操作比直接对表操作慢,可以用stored procedure来代替她。特别的是不要用视图嵌套,嵌套视图增加了寻找原始资料的难度。我们看视图的本质:它是存放在服务器上的被优化好了的已经产生了查询规划的SQL。对单个表检索数据时,不要使用指向多个表的视图,直接从表检索或者仅仅包含这个表的视图上读,否则增加了不必要的开销,查询受到干扰.为了加快视图的查询,MsSQL增加了视图索引的功能。
34、没有必要时不要用DISTINCT和ORDER BY,这些动作可以改在客户端执行。它们增加了额外的开销。这同UNION 和UNION ALL一样的道理。
35、在IN后面值的列表中,将出现最频繁的值放在最前面,出现得最少的放在最后面,减少判断的次数。
36、当用SELECT INTO时,它会锁住系统表(sysobjects,sysindexes等等),阻塞其他的连接的存取。创建临时表时用显示申明语句,而不是在另一个连接中SELECT * from sysobjects可以看到 SELECT INTO 会锁住系统表,Create table 也会锁系统表(不管是临时表还是系统表)。所以千万不要在事物内使用它!!!这样的话如果是经常要用的临时表请使用实表,或者临时表变量。
37、一般在GROUP BY 个HAVING字句之前就能剔除多余的行,所以尽量不要用它们来做剔除行的工作。他们的执行顺序应该如下最优:select 的Where字句选择所有合适的行,Group By用来分组个统计行,Having字句用来剔除多余的分组。这样Group By 个Having的开销小,查询快.对于大的数据行进行分组和Having十分消耗资源。如果Group BY的目的不包括计算,只是分组,那么用Distinct更快
38、一次更新多条记录比分多次更新每次一条快,就是说批处理好
39、少用临时表,尽量用结果集和Table类性的变量来代替它,Table 类型的变量比临时表好
40、在SQL2000下,计算字段是可以索引的,需要满足的条件如下:
a、计算字段的表达是确定的
b、不能用在TEXT,Ntext,Image数据类型
c、必须配制如下选项 ANSI_NULLS = ON, ANSI_PADDINGS = ON, …….
41、尽量将数据的处理工作放在服务器上,减少网络的开销,如使用存储过程。存储过程是编译好、优化过、并且被组织到一个执行规划里、且存储在数据库中的SQL语句,是控制流语言的集合,速度当然快。反复执行的动态SQL,可以使用临时存储过程,该过程(临时表)被放在Tempdb中。以前由于SQL SERVER对复杂的数学计算不支持,所以不得不将这个工作放在其他的层上而增加网络的开销。SQL2000支持UDFs,现在支持复杂的数学计算,函数的返回值不要太大,这样的开销很大。用户自定义函数象光标一样执行的消耗大量的资源,如果返回大的结果采用存储过程
42、不要在一句话里再三的使用相同的函数,浪费资源,将结果放在变量里再调用更快
43、SELECT COUNT(*)的效率教低,尽量变通他的写法,而EXISTS快.同时请注意区别: select count(Field of null) from Table 和 select count(Field of NOT null) from Table 的返回值是不同的!!!
44、当服务器的内存够多时,配制线程数量 = 最大连接数+5,这样能发挥最大的效率;否则使用 配制线程数量<最大连接数启用SQL SERVER的线程池来解决,如果还是数量 = 最大连接数+5,严重的损害服务器的性能。
45、按照一定的次序来访问你的表。如果你先锁住表A,再锁住表B,那么在所有的存储过程中都要按照这个顺序来锁定它们。如果你(不经意的)某个存储过程中先锁定表B,再锁定表A,这可能就会导致一个死锁。如果锁定顺序没有被预先详细的设计好,死锁很难被发现
46、通过SQL Server Performance Monitor监视相应硬件的负载 Memory: Page Faults / sec计数器如果该值偶尔走高,表明当时有线程竞争内存。如果持续很高,则内存可能是瓶颈。
Process:
1)% DPC Time 指在范例间隔期间处理器用在缓延程序调用(DPC)接收和提供服务的百分比。(DPC 正在运行的为比标准间隔优先权低的间隔)。 由于 DPC 是以特权模式执行的,DPC 时间的百分比为特权时间 百分比的一部分。这些时间单独计算并且不属于间隔计算总数的一部 分。这个总数显示了作为实例时间百分比的平均忙时。
2)%Processor Time计数器 如果该参数值持续超过95%,表明瓶颈是CPU。可以考虑增加一个处理器或换一个更快的处理器。
3)% Privileged Time 指非闲置处理器时间用于特权模式的百分比。(特权模式是为操作系统组件和操纵硬件驱动程序而设计的一种处理模式。它允许直接访问硬件和所有内存。另一种模式为用户模式,它是一种为应用程序、环境分系统和整数分系统设计的一种有限处理模式。操作系统将应用程序线程转换成特权模式以访问操作系统服务)。 特权时间的 % 包括为间断和 DPC 提供服务的时间。特权时间比率高可能是由于失败设备产生的大数量的间隔而引起的。这个计数器将平均忙时作为样本时间的一部分显示。
4)% User Time表示耗费CPU的数据库操作,如排序,执行aggregate functions等。如果该值很高,可考虑增加索引,尽量使用简单的表联接,水平分割大表格等方法来降低该值。 Physical Disk: Curretn Disk Queue Length计数器该值应不超过磁盘数的1.5~2倍。要提高性能,可增加磁盘。 SQLServer:Cache Hit Ratio计数器该值越高越好。如果持续低于80%,应考虑增加内存。 注意该参数值是从SQL Server启动后,就一直累加记数,所以运行经过一段时间后,该值将不能反映系统当前值。
47、分析select emp_name form employee where salary > 3000 在此语句中若salary是Float类型的,则优化器对其进行优化为Convert(float,3000),因为3000是个整数,我们应在编程时使用3000.0而不要等运行时让DBMS进行转化。同样字符和整型数据的转换。
48、查询的关联同写的顺序
select a.personMemberID, * from chineseresume a,personmember b where personMemberID
= b.referenceid and a.personMemberID = ‘JCNPRH39681’ (A = B ,B = ‘号码’)
select a.personMemberID, * from chineseresume a,personmember b where a.personMemberID
= b.referenceid and a.personMemberID = ‘JCNPRH39681’ and b.referenceid = ‘JCNPRH39681’ (A = B ,B = ‘号码’, A = ‘号码’)
select a.personMemberID, * from chineseresume a,personmember b where b.referenceid
= ‘JCNPRH39681’ and a.personMemberID = ‘JCNPRH39681’ (B = ‘号码’, A = ‘号码’)
49、
(1)IF 没有输入负责人代码 THEN code1=0 code2=9999 ELSE code1=code2=负责人代码 END IF 执行SQL语句为: SELECT 负责人名 FROM P2000 WHERE 负责人代码>=:code1 AND负责人代码 <=:code2
(2)IF 没有输入负责人代码 THEN SELECT 负责人名 FROM P2000 ELSE code= 负责人代码 SELECT 负责人代码 FROM P2000 WHERE 负责人代码=:code END IF 第一种方法只用了一条SQL语句,第二种方法用了两条SQL语句。在没有输入负责人代码时,第二种方法显然比第一种方法执行效率高,因为它没有限制条件;在输入了负责人代码时,第二种方法仍然比第一种方法效率高,不仅是少了一个限制条件,还因相等运算是最快的查询运算。我们写程序不要怕麻烦
50、关于JOBCN现在查询分页的新方法(如下),用性能优化器分析性能的瓶颈,如果在I/O或者网络的速度上,如下的方法优化切实有效,如果在CPU或者内存上,用现在的方法更好。请区分如下的方法,说明索引越小越好。
5.9.3 查看
查看慢查询时间
show variables like ‘slow%’;
查看设置多久是慢查询
show variables like ‘long%’;
修改慢查询时间
set long_query_time=1;
打开慢查询记录日志
set global slow_query_log=‘ON’;
查看哪些线程正在运行
show full processlist
查看最大连接数
show variables like ‘%max_connections%’;
当前连接数
show status like ‘Threads_connected%’;
六、服务器知识
6.1 Docker的原理
Docker:http://dockone.io/article/8148
关于Docker实现原理,简单总结如下:
- 使用Namespaces实现了系统环境的隔离,Namespaces允许一个进程以及它的子进程从共享的宿主机内核资源(网络栈、进程列表、挂载点等)里获得一个仅自己可见的隔离区域,让同一个Namespace下的所有进程感知彼此变化,对外界进程一无所知,仿佛运行在一个独占的操作系统中;
- 使用CGroups限制这个环境的资源使用情况,比如一台16核32GB的机器上只让容器使用2核4GB。使用CGroups还可以为资源设置权重,计算使用量,操控任务(进程或线程)启停等;
- 使用镜像管理功能,利用Docker的镜像分层、写时复制、内容寻址、联合挂载技术实现了一套完整的容器文件系统及运行环境,再结合镜像仓库,镜像可以快速下载和共享,方便在多环境部署。
6.2 CDN
CDN:https://blog.csdn.net/jiangbb8686/article/details/86516656
6.2.1 CDN概念
CDN的全称是Content Delivery Network,即内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到最接近用户的网络"边缘",使用户可以就近取得所需的内容,解决Internet网络拥塞状况,提高用户访问网站的响应速度。从技术上全面解决由于网络带宽小、用户访问量大、网点分布不均等原因,解决用户访问网站的响应速度慢的根本原因。
6.2.2 CDN架构
CDN网络架构主要由两大部分,分为中心和边缘两部分,中心指CDN网管中心和DNS重定向解析中心,负责全局负载均衡,设备系统安装在管理中心机房,边缘主要指异地节点,CDN分发的载体,主要由Cache和负载均衡器等组成。
6.3 LVS(Linux Virtual Server)
6.3.1 lvs架构
LVS架构从逻辑上可分为调度层、Server集群层和共享存储。
6.3.2 工作原理
- 当用户向负载均衡调度器(Director Server)发起请求,调度器将请求发往至内核空间
- PREROUTING链首先会接收到用户请求,判断目标IP确定是本机IP,将数据包发往INPUT链
- IPVS是工作在INPUT链上的,当用户请求到达INPUT时,IPVS会将用户请求和自己已定义好的集群服务进行比对,如果用户请求的就是定义的集群服务,那么此时IPVS会强行修改数据包里的目标IP地址及端口,并将新的数据包发往POSTROUTING链
- POSTROUTING链接收数据包后发现目标IP地址刚好是自己的后端服务器,那么此时通过选路,将数据包最终发送给后端的服务器
简单总结:
基于IP层和基于内容请求分发的负载平衡调度解决方法,并在Linux内核中实现
用户请求LVS VIP,LVS根据转发方式和算法,将请求转发给后端服务器,后端服务器接受到请求,返回给用户。
6.3.3 工作模式
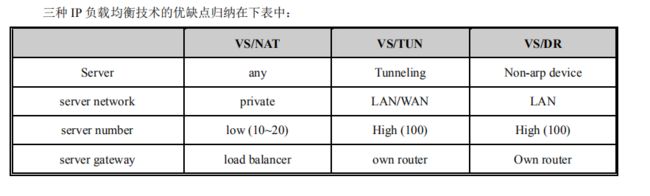
- NAT特性
1)RS应该使用私有地址,RS的网关必须指向DIP
2)DIP和RIP必须在同一个网段内
3)请求和响应报文都需要经过Director Server,高负载场景中,Director Server易成为性能瓶颈
4)支持端口映射
5)RS可以使用任意操作系统
缺陷:对Director Server压力会比较大,请求和响应都需经过director server
- TUN特性
1)RIP、VIP、DIP全是公网地址
2)RS的网关不会也不可能指向DIP
3)所有的请求报文经由Director Server,但响应报文必须不能经过Director Server
4)不支持端口映射
5)RS的系统必须支持隧道
不足:RS配置复杂(IPIP模块等);RS上绑定VIP,风险大;
- DR特性
1)保证前端路由将目标地址为VIP报文统统发给Director Server,而不是RS
2)RS可以使用私有地址;也可以是公网地址,如果使用公网地址,此时可以通过互联网对RIP进行直接访问
3)RS跟Director Server必须在同一个物理网络中
4)所有的请求报文经由Director Server,但响应报文必须不能进过Director Server
5)不支持地址转换,也不支持端口映射
6)RS可以是大多数常见的操作系统
7)RS的网关绝不允许指向DIP(因为我们不允许他经过director)
8)RS上的lo接口配置VIP的IP地址
不足:LVS-RS间必须在同一个VLAN;RS上绑定VIP,风险大;
6.3.4 做高可用
服务部署:https://zhuanlan.zhihu.com/p/59215319
高可用架构:https://www.jianshu.com/p/c8a28bd954b0
Nacos高可用集群搭建+MySQL持久化:https://blog.csdn.net/xudc0521/article/details/105099583?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2allfirst_rank_v2~rank_v25-7-105099583.nonecase&utm_term=nacos%E6%80%8E%E4%B9%88%E5%AE%9E%E7%8E%B0%E9%AB%98%E5%8F%AF%E7%94%A8
安装Keepalived
编辑keepalived.conf配置文件
大型网站的分布式部署,使得位于不同层次的服务器具有不同的可用性设计:
- 应用层 - 为了应对高并发的访问请求,通常会使用负载均衡设备把一组的服务器组合为一个集群,共同对外提供服务。当负载均衡设备监控到某台服务器不可用时,就将其从集群中剔除,并把请求转发到集群中的其他可用的服务器。
- 服务层 - 应用层通过分布式服务框架来调用这一层提供的服务。分布式服务框架会在应用层的客户端程序中实现软件级的负载均衡,并通过注册中心监控这些提供服务的服务器。一旦发现某个服务器不可用,会立即通知客户端程序修改服务访问列表,剔除不可用的服务器。
- 数据层 - 写入数据的同时同步复制数据,把数据写入多台服务器,实现数据的冗余备份。当数据服务器宕机时,会把针对数据的访问切换到拥有备份数据的服务器上。
6.4 Apache服务器怎么搭建, IO复用模型, select epoll
6.4.1 配置apache服务器
配置文件
[root@localhost ~]# vim /etc/httpd/conf/httpd.conf
DocumentRoot "/data/pl"
ServerName www.pl.com
ErrorLog "logs/www.pl.com-error_log"
TransferLog "logs/host.pl.com-access_log"
DocumentRoot "/data/haha"
ServerName www.haha.com
ErrorLog "logs/www.haha.com-error_log"
TransferLog "logs/host.haha.com-access_log"
DocumentRoot "/data/hehe"
ServerName www.hehe.com
ErrorLog "logs/www.hehe.com-error_log"
TransferLog "logs/host.hehe.com-access_log"
创建文件
[root@localhost ~]# mkdir /data
[root@localhost ~]# mkdir /data/{pl,haha,hehe}
[root@localhost ~]# echo "pl " > /data/pl/index.html
[root@localhost ~]# echo "haha " > /data/haha/index.html
[root@localhost ~]# echo "hehe " > /data/hehe/index.html
写入域名解析
[root@localhost ~]# vim /etc/hosts
192.168.217.155 www.pl.com www.haha.com www.hehe.com
测试

6.4.2 nginx架构
任何Unix应用程序的基本基础都是线程或进程。
NGINX Worker流程内部
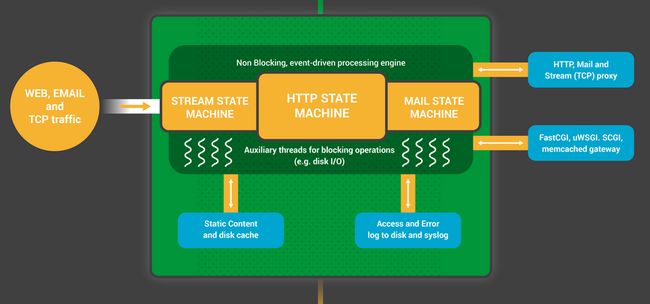
每个NGINX工作进程都使用NGINX配置初始化,并且由主进程提供一组侦听套接字。
NGINX工作进程始于等待侦听套接字上的事件(accept_mutex和内核套接字分片)。事件由新的传入连接启动。这些连接被分配给状态机 -HTTP状态机是最常用的,但是NGINX还为流(原始TCP)流量和许多邮件协议(SMTP,IMAP和POP3)实现状态机。
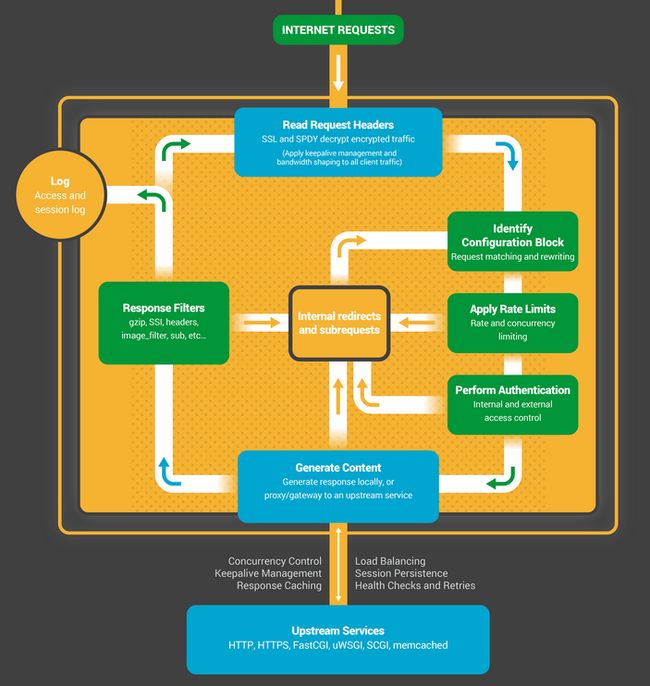
状态机本质上是一组指令,用于告诉NGINX如何处理请求。大多数执行与NGINX相同功能的Web服务器都使用类似的状态机-区别在于实现。
6.4.3 IO复用模型
Linux中IO复用工具:在Linux中先后出现了select、poll、epoll等,FreeBSD的kqueue也是非常优秀的IO复用工具,kqueue的原理和epoll很类似
参考知乎文章:https://www.zhihu.com/question/20122137/answer/14049112
流:一个流可以是文件,socket,pipe等等可以进行I/O操作的内核对象。
阻塞:比如某个时候你在等快递,但是你不知道快递什么时候过来,而且你没有别的事可以干(或者说接下来的事要等快递来了才能做);那么你可以去睡觉了,因为你知道快递把货送来时一定会给你打个电话(假定一定能叫醒你)。
非阻塞忙轮询:接着上面等快递的例子,如果用忙轮询的方法,那么你需要知道快递员的手机号,然后每分钟给他挂个电话:“你到了没?”
为了避免CPU空转,可以引进了一个代理(一开始有一位叫做select的代理,后来又有一位叫做poll的代理,不过两者的本质是一样的)。
这个代理比较厉害,可以同时观察许多流的I/O事件,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有I/O事件时,就从阻塞态中醒来,于是我们的程序就会轮询一遍所有的流(于是我们可以把“忙”字去掉了)。
于是,如果没有I/O事件产生,我们的程序就会阻塞在select处。
epoll可以理解为event poll,不同于忙轮询和无差别轮询,epoll只会把哪个流发生了怎样的I/O事件通知我们。此时我们对这些流的操作都是有意义的。(复杂度降低到了O(k),k为产生I/O事件的流的个数,也有认为O(1)的)
注:单个select最多只能同时处理1024个socket。
select的做法:
步骤1的解法:select创建3个文件描述符集,并将这些文件描述符拷贝到内核中,这里限制了文件句柄的最大的数量为1024(注意是全部传入—第一次拷贝);
步骤2的解法:内核针对读缓冲区和写缓冲区来判断是否可读可写,这个动作和select无关;
步骤3的解法:内核在检测到文件句柄可读/可写时就产生中断通知监控者select,select被内核触发之后,就返回可读可写的文件句柄的总数;
步骤4的解法:select会将之前传递给内核的文件句柄再次从内核传到用户态(第2次拷贝),select返回给用户态的只是可读可写的文件句柄总数,再使用FD_ISSET宏函数来检测哪些文件I/O可读可写(遍历);
步骤5的解法:select对于事件的监控是建立在内核的修改之上的,也就是说经过一次监控之后,内核会修改位,因此再次监控时需要再次从用户态向内核态进行拷贝(第N次拷贝)
epoll的做法:
步骤1的解法:首先执行epoll_create在内核专属于epoll的高速cache区,并在该缓冲区建立红黑树和就绪链表,用户态传入的文件句柄将被放到红黑树中(第一次拷贝)。
步骤2的解法:内核针对读缓冲区和写缓冲区来判断是否可读可写,这个动作与epoll无关;
步骤3的解法:epoll_ctl执行add动作时除了将文件句柄放到红黑树上之外,还向内核注册了该文件句柄的回调函数,内核在检测到某句柄可读可写时则调用该回调函数,回调函数将文件句柄放到就绪链表。
步骤4的解法:epoll_wait只监控就绪链表就可以,如果就绪链表有文件句柄,则表示该文件句柄可读可写,并返回到用户态(少量的拷贝);
步骤5的解法:由于内核不修改文件句柄的位,因此只需要在第一次传入就可以重复监控,直到使用epoll_ctl删除,否则不需要重新传入,因此无多次拷贝。
简单说:epoll是继承了select/poll的I/O复用的思想,并在二者的基础上从监控IO流、查找I/O事件等角度来提高效率,具体地说就是内核句柄列表、红黑树、就绪list链表来实现的。
epoll高效的原因:
这是由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件.
当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效。
五种网络IO模型和select/epoll对比:https://zhuanlan.zhihu.com/p/38277885

总结
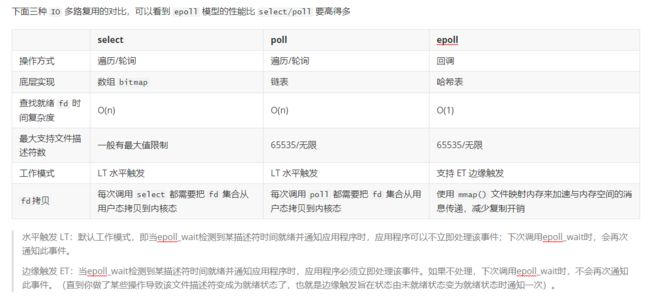
6.5 公钥私钥原理,公钥文件存放哪里,权限是多少
6.5.1 对称加密算法原理
- 密钥K的可能值的范围叫做密钥空间,加密和解密运算都使用这个密钥,即运算都依赖于密钥,并用K作为下标表示,
- 加/解密函数表达为:
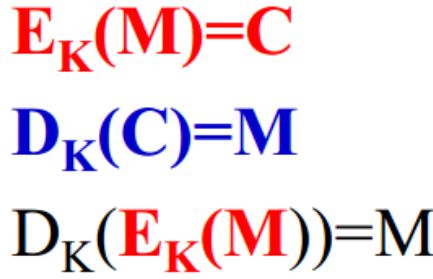
- 流程
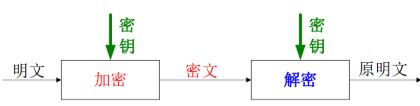
- 对称加密算法介绍
- 对称密码体制的加密密钥和解密密钥是相同的;
- 对称密码技术相比于非对称密码技术最明显的优势是:速度快,一般适用于对大量的数据进行加密和解密;
- 对称密码技术包括:DES、AES、3DES
6.5.2 非对称加密算法原理
- 有些算法使用不同的加密密钥和解密密钥,也就是说加密密钥K1与相应的解密密钥K2不同,在这种情况下,
- 加密和解密的函数表达式为:
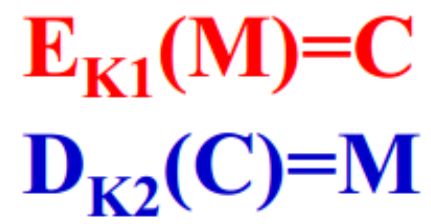
- 流程
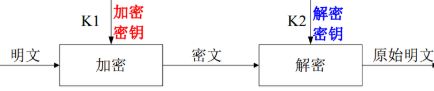
公私钥:https://blog.csdn.net/udeankyd/article/details/81059704
使用公钥与私钥的目的就是实现安全的电子邮件,必须实现如下目的:
1、我发送给你的内容必须加密,在邮件的传输过程中不能被别人看到。
2、必须保证是我发送的邮件,不是别人冒充我的。
要达到这样的目标必须发送邮件的两人都有公钥和私钥。
公钥,就是给大家用的,你可以通过电子邮件发布,可以通过网站让别人下载,公钥其实是用来加密/验章用的。私钥,就是自己的,必须非常小心保存,最好加上密码,私钥是用来解密/签章,首先就Key的所有权来说,私钥只有个人拥有。公钥与私钥的作用是:用公钥加密的内容只能用私钥解密,用私钥加密的内容只能用公钥解密。
比如说,我要给你发送一个加密的邮件。首先,我必须拥有你的公钥,你也必须拥有我的公钥。
首先,我用你的公钥给这个邮件加密,这样就保证这个邮件不被别人看到,而且保证这个邮件在传送过程中没有被修改。你收到邮件后,用你的私钥就可以解密,就能看到内容。
其次我用我的私钥给这个邮件加密,发送到你手里后,你可以用我的公钥解密。因为私钥只有我手里有,这样就保证了这个邮件是我发送的。
当A->B资料时,A会使用B的公钥加密,这样才能确保只有B能解开,否则普罗大众都能解开加密的讯息,就是去了资料的保密性。验证方面则是使用签验章的机制,A传资料给大家时,会以自己的私钥做签章,如此所有收到讯息的人都可以用A的公钥进行验章,便可确认讯息是由 A 发出来的了。
6.5.3 公钥文件以及权限
服务端文件
-
/etc/ssh/ssh_host_rsa_key
-
/etc/ssh/ssh_host_rsa_key.pub
-
~/.ssh/authorized_keys
客户端文件
- 客户端主机认证文件
- ~/.ssh/known_host
- 客户端密钥对
- ssh-keygen生成
- ~/.ssh/id.rsa
- ~/.ssh/id.rsa.pub
设定为700 ~/.ssh
600 ~/.ssh/authorized_keys
6.6 了解云计算
云计算:
- 一种资源交付模式
- 必须通过网络来使用
- 弹性计算,按需付费,快速扩展
6.6.1 云计算分层
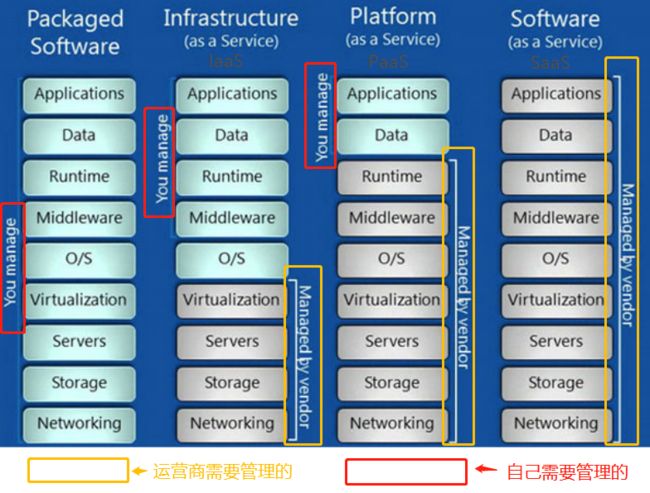
-
IaaS
基础设施即服务
AWS,阿里云,腾讯云 -
PaaS
平台即服务
新浪云 -
SaaS
软件即服务
云盘,企业邮箱等
6.7 DNS的解析过程
6.7.1 实际查询过程分析
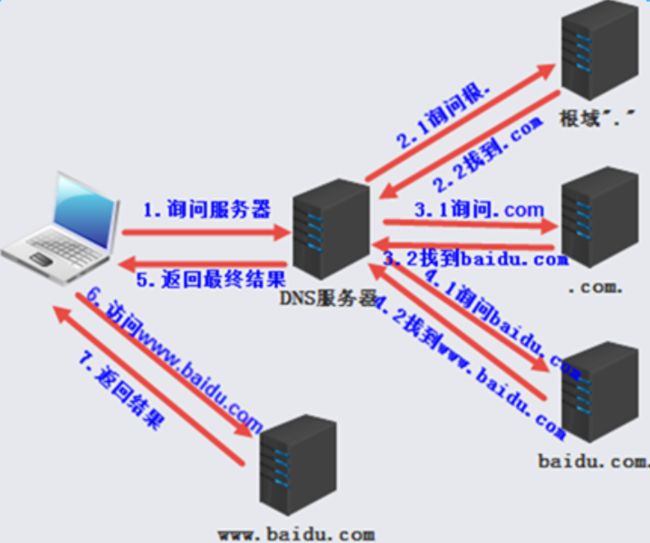
(1).客户端要访问www.baidu.com,首先会查找本机DNS缓存,再查找自己的hosts文件,还没有的话就找DNS服务器(这个DNS服务器就是计算机里设置指向的DNS)。
windows
查看本机dns缓存
ipconfig/displaydns
ipconfig/flushdns
linux
resolv.conf
(2).DNS服务器收到询问请求,首先查看自己是否有www.baidu.com的缓存,如果有就直接返回给客户端,没有就越级上访到根域".",并询问根域。
(3).根域看到是找.com域的,把到.com域的路(地址)告诉DNS服务器,让DNS服务器去找.com询问。
(4).DNS服务器去找.com,".com"一看是自己辖下的baidu.com,就把baidu.com的IP地址给DNS服务器,让它去找baidu.com。
(5).DNS找到baidu.com,baidu.com发现DNS服务器要找的是自己区域里的www主机,就把这个主机IP地址给了DNS服务器。
(6).DNS服务器把得到的www.baidu.com的IP结果告诉客户端,并缓存一份结果在自己机器中(默认会缓存,因为该服务器允许为客户端递归,否则不会缓存非权威数据)。
(7).客户端得到回答的IP地址后缓存下来,并去访问www.baidu.com,然后www.baidu.com就把页面内容发送给客户端,也就是百度页面。
6.7.2 解析顺序
解析顺序
1) 浏览器缓存
当用户通过浏览器访问某域名时,浏览器首先会在自己的缓存中查找是否有该域名对应的IP地址(若曾经访问过该域名且没有清空缓存便存在);
2) 系统缓存
当浏览器缓存中无域名对应IP则会自动检查用户计算机系统Hosts文件DNS缓存是否有该域名对应IP;
3) 路由器缓存
当浏览器及系统缓存中均无域名对应IP则进入路由器缓存中检查,以上三步均为客服端的DNS缓存;
4) ISP(互联网服务提供商)DNS缓存
当在用户客服端查找不到域名对应IP地址,则将进入ISP DNS缓存中进行查询。比如你用的是电信的网络,则会进入电信的DNS缓存服务器中进行查找;
5) 根域名服务器
当以上均未完成,则进入根服务器进行查询。全球仅有13台根域名服务器,1个主根域名服务器,其余12为辅根域名服务器。根域名收到请求后会查看区域文件记录,若无则将其管辖范围内顶级域名(如.com)服务器IP告诉本地DNS服务器;
6) 顶级域名服务器
顶级域名服务器收到请求后查看区域文件记录,若无则将其管辖范围内主域名服务器的IP地址告诉本地DNS服务器;
7) 主域名服务器
主域名服务器接受到请求后查询自己的缓存,如果没有则进入下一级域名服务器进行查找,并重复该步骤直至找到正确纪录;
8)保存结果至缓存
本地域名服务器把返回的结果保存到缓存,以备下一次使用,同时将该结果反馈给客户端,客户端通过这个IP地址与web服务器建立链接。
6.7.3 DNS服务器查找根域时丢包怎么办
丢包:https://zhuanlan.zhihu.com/p/70031826
修改MTU->1492或1480
主要根据你所在的网络环境决定
1.更换DNS查看是否正常,某些网络可能有指定的DNS
2.检查内网是否正常
3.出口IP是否正常,可能ISP那边有问题,可报修询问
4.某些网络环境有做防火墙策略等问题造成
DNS常见优化思路
DNS结果缓存:开启dnsmasq
DNS解析预存:在web应用中,不等用户点击页面上超链,浏览器在后台自动解析域名,把结果缓存。
HttpDNS取代DNS解析:移动应用防DNS劫持
基于DNS的全局负载均衡(GSLB):负载均衡和高可用,同时返回离用户最近的IP。
规避办法
规避方案一:使用TCP发送DNS请求
规避方案二:避免相同五元组DNS请求的并发
规避方案三:使用本地DNS缓存
6.8 为什么nginx支持高并发?
6.8.1 搭建静态资源web服务器
1.准备好服务器server,并安装nginx
2.准备好静态网页文件,并放到安装目录下的html中
3.启动服务 /usr/local/nginx/sbin/nginx
4.基本配置 配置文件nginx.conf
6.8.2 为什么nginx支持高并发
nginx 采用的是多进程+epoll
epoll:https://www.cnblogs.com/moris5013/p/11207499.html
6.8.3 动态网页和静态网页有什么区别?
静态网页是指内容是死的。这里的静,指的就是内容完全不变,不会跑。
动态网页是指内容是活的。这里的动,指的是内容是从数据库中,或者是从别的地方写出来的,拼接而成的。
6.8.4 介绍一下nginx的日志
常用日志格式
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
参数:
$remote_addr:远程IP;
$remote_user:远程用户;
$stime_local:时间;
$request:用来记录请求的url与http协议;
$status:用来记录请求状态;成功是200;
$body_bytes_sent:记录发送给客户端文件主体内容大小;
$http_referer:用来记录从那个页面链接访问过来的;
$http_user_agent:记录客户浏览器的相关信息;
$http_x_forwarded_for:访问用户的真实 IP 地址;
常见的日志参数
日志参数:https://www.cnblogs.com/njkk/p/6573533.html
6.8.5 nginx的虚拟主机
虚拟主机类型
-
基于IP的虚拟主机
-
基于端口的虚拟主机
-
基于域名的虚拟主机(常用)
[root@localhost ~]# vim /usr/local/nginx/conf/vhost/hehe1.conf
server {
listen 80;
server_name www.hehe1.com;
location / {
root /data/hehe1;
index index.html index.htm;
}
}
6.8.6 nginx如何部署django
部署django:https://www.cnblogs.com/frchen/p/5709533.html
安装uWSGI
6.9 ansible的原理和使用方法
Ansible是一个简单的自动化运维管理工具,基于python语言实现,由Paramiko和PyYAML两个关键模块构建,可用于自动化部署应用、配置、编排task(持续交付、无宕机更新)
6.9.1 原理
原理:https://www.linuxprobe.com/ansible-formwork-2.html
以上是从网上找到的两张ansible工作原理图,两张图基本都是在架构图的基本上进行的拓展。从上面的图上可以了解到:
1、管理端支持local 、ssh、zeromq 三种方式连接被管理端,默认使用基于ssh的连接---这部分对应基本架构图中的连接模块;
2、可以按应用类型等方式进行Host Inventory(主机群)分类,管理节点通过各类模块实现相应的操作---单个模块,单条命令的批量执行,我们可以称之为ad-hoc;
3、管理节点可以通过playbooks 实现多个task的集合实现一类功能,如web服务的安装部署、数据库服务器的批量备份等。playbooks我们可以简单的理解为,系统通过组合多条ad-hoc操作的配置文件 。
6.9.2 使用方法
密钥部署
管理端生成密钥
ssh-keygen
将密钥分发到2个节点中
ssh-copy-id [email protected]
ansible-doc 模块名 查看指定模块文档
ansible-doc -s 模块名 只显示模块关键参数
ansible-doc -l 列出所有模块
ansible-doc --version 查看ansible版本及配置信息
6.9.3 SaltStack、Ansible、Puppet比较
比较:https://www.cnblogs.com/xiaonq/p/11548297.html
1、SaltStack
1)saltStack由Python编写,为server-client模式的系统,自己本身支持多master。
2)运行模式为master端下发指令,客户端接收指令执行。
3)saltstack依赖于zeromq消息队列,采用yaml格式编写配置文件,比较简单。
4)支持api及自定义python模块,能轻松实现功能扩展。
2、Ansible
1)类似与saltstack,基于python开发,关注的重点是精简和快速。
2)不需要在节点安装代理软件,通过ssh执行所有功能,安装运行简单。
3)其模块可以用任何语言开发,采用yaml格式编写配置文件。
4)没有客户端,较难扩展。
3、Puppet
1)puppet由Ruby编写,为server-client模式的系统。
2)运行时由客户端定时去获取自己的配置文件进而应用更改。
3)也可以通过master的push命令即可触发变更。
4)将命令,文件,服务等抽象成资源,概念比较统一,时间悠久,文档较多。
5)就可用操作,模块,用户界面等等功能而言,是三者之中最全面的。
6)安装部署难度一般,配置清单相对于其他工具较复杂。
比较
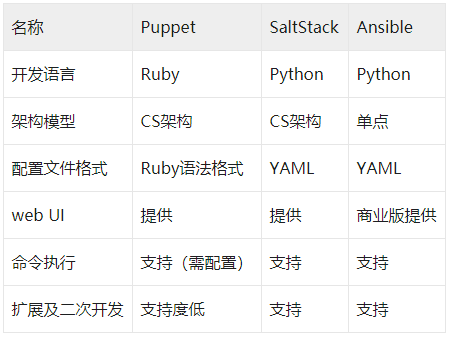
6.10 redis
redis作用:https://blog.csdn.net/weixin_42295141/article/details/81380633
Remote Dictionary Server(远程字典服务器)是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型的一种Key-Value数据库,并提供多种语言的APl。
它通常被称为数据结构服务器,因为值(value)可以是字符串(String),哈希(Map),列表(list),集合(sets)和有序集合(sorted sets)等类型。
6.10.1 redis的作用
通常局限点来说,Redis也以消息队列的形式存在,作为内嵌的List存在,满足实时的高并发需求。而通常在一个电商类型的数据处理过程之中,有关商品,热销,推荐排序的队列,通常存放在Redis之中,期间也包扩Storm对于Redis列表的读取和更新。
Redis优点:
1.支持多种数据结构,如string(字符串)、list(双向链表)、dict(hash表)、set(集合)、zset(排序set)、hyperloglog(基数估算)
2.支持持久化操作,可以进行aof及rdb数据持久化到磁盘,从而进行数据备份或数据恢复等操作,较好的防止数据丢失的手段。
3.支持通过Replication 进行数据复制,通过master-slave机制,可以实时进行数据的同步复制,支持多级复制和增量复制,master-slave机制是Redis进行HA的重要手段。
4.单进程请求,所有命令串行执行,并发情况下不需要考虑数据一致性问题。
Redis的缺点
是数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
总结: Redis受限于特定的场景,专注于特定的领域之下,速度相当之快,目前还未找到能替代使用产品。
6.10.2 redis哨兵怎么做
redis哨兵搭建:https://blog.csdn.net/bazhuayu_1203/article/details/93589893
redis哨兵:https://www.cnblogs.com/kevingrace/p/9004460.html
哨兵配置
开启守护进程 daemonize yes
关闭保护模式 protected-mode no
指定监听主服务器名称、ip、port和几个sentinel检测异常执行故障转移
指定监听服务器密码
Redis的集群方案大致有三种:
1)redis cluster集群方案;
2)master/slave主从方案;
3)哨兵模式来进行主从替换以及故障恢复。
Sentinel(哨兵)是用于监控redis集群中Master状态的工具。
sentinel系统可以监视一个或者多个redis master服务,以及这些master服务的所有从服务;当某个master服务下线时,自动将该master下的某个从服务升级为master服务替代已下线的master服务继续处理请求。
sentinel可以让redis实现主从复制,当一个集群中的master失效之后,sentinel可以选举出一个新的master用于自动接替master的工作,集群中的其他redis服务器自动指向新的master同步数据。一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。其结构如下:
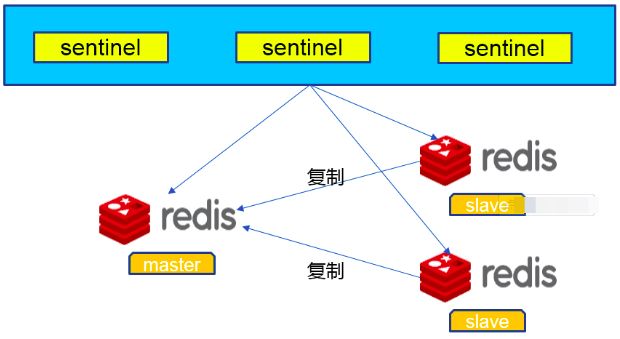
Sentinel作用:
1)Master状态检测
2)如果Master异常,则会进行Master-Slave切换,将其中一个Slave作为Master,将之前的Master作为Slave。
3)Master-Slave切换后,master_redis.conf、slave_redis.conf和sentinel.conf的内容都会发生改变,即master_redis.conf中会多一行slaveof的配置,sentinel.conf的监控目标会随之调换。
6.10.3 redis数据库存放文件的地方
这里以安装到/usr/local/redis为例,配置文件在/usr/local/redis/redis.conf
这个demo.rdb文件便是存放数据文件的地方
默认文件名 :/var/lib/redis/dump.rdb
6.10.4 主从复制的过程
主从复制:https://www.cnblogs.com/kevingrace/p/5685332.html
redis主从复制简单来说:
A)Redis的复制功能是支持多个数据库之间的数据同步。一类是主数据库(master)一类是从数据库(slave),主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而从数据库一般是只读的,并接收主数据库同步过来的数据,一个主数据库可以有多个从数据库,而一个从数据库只能有一个主数据库。
B)通过redis的复制功能可以很好的实现数据库的读写分离,提高服务器的负载能力。主数据库主要进行写操作,而从数据库负责读操作。
Redis主从复制流程简图
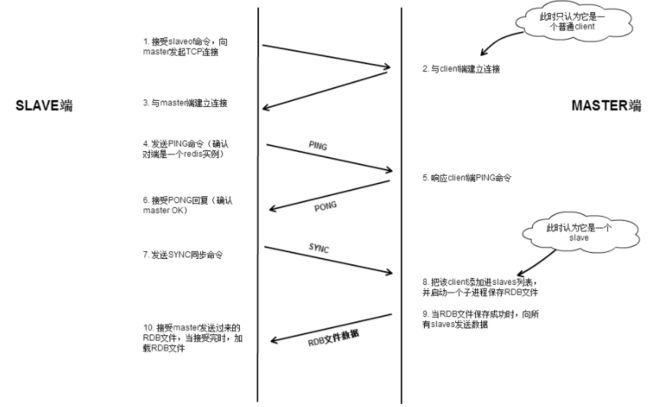
redis主从复制的大致过程:
1)当一个从数据库启动时,会向主数据库发送sync命令,
2)主数据库接收到sync命令后会开始在后台保存快照(执行rdb操作),并将保存期间接收到的命令缓存起来
3)当快照完成后,redis会将快照文件和所有缓存的命令发送给从数据库。
4)从数据库收到后,会载入快照文件并执行收到的缓存的命令。
注意:redis2.8之前的版本:当主从数据库同步的时候从数据库因为网络原因断开重连后会重新执行上述操作,不支持断点续传。redis2.8之后支持断点续传。
Redis大概主从同步是怎么实现的?
全量同步
master服务器会开启一个后台进程用于将redis中的数据生成一个rdb文件,与此同时,服务器会缓存所有接收到的来自客户端的写命令(包含增、删、改),当后台保存进程处理完毕后,会将该rdb文件传递给slave服务器,而slave服务器会将rdb文件保存在磁盘并通过读取该文件将数据加载到内存,在此之后master服务器会将在此期间缓存的命令通过redis传输协议发送给slave服务器,然后slave服务器将这些命令依次作用于自己本地的数据集上最终达到数据的一致性。
部分同步=
从redis 2.8版本以前,并不支持部分同步,当主从服务器之间的连接断掉之后,master服务器和slave服务器之间都是进行全量数据同步,但是从redis 2.8开始,即使主从连接中途断掉,也不需要进行全量同步,因为从这个版本开始融入了部分同步的概念。部分同步的实现依赖于在master服务器内存中给每个slave服务器维护了一份同步日志和同步标识,每个slave服务器在跟master服务器进行同步时都会携带自己的同步标识和上次同步的最后位置。当主从连接断掉之后,slave服务器隔断时间(默认1s)主动尝试和master服务器进行连接,如果从服务器携带的偏移量标识还在master服务器上的同步备份日志中,那么就从slave发送的偏移量开始继续上次的同步操作,如果slave发送的偏移量已经不再master的同步备份日志中(可能由于主从之间断掉的时间比较长或者在断掉的短暂时间内master服务器接收到大量的写操作),则必须进行一次全量更新。在部分同步过程中,master会将本地记录的同步备份日志中记录的指令依次发送给slave服务器从而达到数据一致。
主从同步中需要注意几个问题
1)在上面的全量同步过程中,master会将数据保存在rdb文件中然后发送给slave服务器,但是如果master上的磁盘空间有限怎么办呢?那么此时全部同步对于master来说将是一份十分有压力的操作了。此时可以通过无盘复制来达到目的,由master直接开启一个socket将rdb文件发送给slave服务器。(无盘复制一般应用在磁盘空间有限但是网络状态良好的情况下)
**2)**主从复制结构,一般slave服务器不能进行写操作,但是这不是死的,之所以这样是为了更容易的保证主和各个从之间数据的一致性,如果slave服务器上数据进行了修改,那么要保证所有主从服务器都能一致,可能在结构上和处理逻辑上更为负责。不过你也可以通过配置文件让从服务器支持写操作。(不过所带来的影响还得自己承担哦。。。)
3)主从服务器之间会定期进行通话,但是如果master上设置了密码,那么如果不给slave设置密码就会导致slave不能跟master进行任何操作,所以如果你的master服务器上有密码,那么也给slave相应的设置一下密码吧(通过设置配置文件中的masterauth);
4)关于slave服务器上过期键的处理,由master服务器负责键的过期删除处理,然后将相关删除命令已数据同步的方式同步给slave服务器,slave服务器根据删除命令删除本地的key。
6.10.5 Redis常见问题和解决办法梳理
问题:https://www.cnblogs.com/kevingrace/p/5569987.html
1、Redis主从复制读写分离问题
1)数据复制的延迟
读写分离时,master会异步的将数据复制到slave,如果这是slave发生阻塞,则会延迟master数据的写命令,造成数据不一致的情况。
解决方法:可以对slave的偏移量值进行监控,如果发现某台slave的偏移量有问题,则将数据读取操作切换到master,但本身这个监控开销比较高,所以关于这个问题,大部分的情况是可以直接使用而不去考虑的。
2)读到过期的数据
redis在删除过期key的时候有两种策略,第一种是懒惰型策略,即只有当redis操作这个key的时候,发现这个key过期,就会把这个key删除。第二种是定期采样一些key进行删除。
针对上面说的两种过期策略,会有个问题,即如果过期key的数量非常多,而采样速度根本比不上过期key的生成速度时会造成很多过期数据没有删除,但在redis里master和slave达成一种协议,slave是不能处理数据的(即不能删除数据)而客户端没有及时读到到过期数据同步给master将key删除,就会导致slave读到过期的数据(这个问题已经在redis3.2版本中解决)。
2、Redis主从配置不一致
1)max memory配置不一致:这个会导致数据的丢失。
原因:例如master配置4G,slave配置2G,这个时候主从复制可以成功,但如果在进行某一次全量复制的时候,slave拿到master的RDB加载数据时发现自身的2G内存不够用,这时就会触发slave的maxmemory策略,将数据进行淘汰。更可怕的是,在高可用的集群环境下,如果将这台slave升级成master的时候,就会发现数据已经丢失了。
2)数据结构优化参数不一致(例如hash-max-ziplist-entries):这个就会导致内存不一致。
原因:例如在master上对这个参数进行了优化,而在slave没有配置,就会造成主从节点内存不一致的诡异问题。
3、规避全量复制
1)第一次全量复制
当某一台slave第一次去挂到master上时,是不可避免要进行一次全量复制的,那么如何去想办法降低开销呢?
**方案1:**小主节点,例如把redis分成2G一个节点,这样一来会加速RDB的生成和同步,同时还可以降低fork子进程的开销(master会fork一个子进程来生成同步需要的RDB文件,而fork是要拷贝内存快的,如果主节点内存太大,fork的开销就大)。
方案2:既然第一次不可以避免,那可以选在集群低峰的时间(凌晨)进行slave的挂载。
2)节点RunID不匹配
例如主节点重启(RunID发生变化),对于slave来说,它会保存之前master节点的RunID,如果它发现了此时master的RunID发生变化,那它会认为这是master过来的数据可能是不安全的,就会采取一次全量复制。
解决办法:对于这类问题,只有是做一些故障转移的手段,例如master发生故障宕掉,选举一台slave晋升为master(哨兵或集群)。
3)复制积压缓冲区不足
master生成RDB同步到slave,slave加载RDB这段时间里,master的所有写命令都会保存到一个复制缓冲队列里(如果主从直接网络抖动,进行部分复制也是走这个逻辑),待slave加载完RDB后,拿offset的值到这个队列里判断,如果在这个队列中,则把这个队列从offset到末尾全部同步过来,这个队列的默认值为1M。而如果发现offset不在这个队列,就会产生全量复制。
**解决办法:**增大复制缓冲区的配置 rel_backlog_size 默认1M,我们可以设置大一些,从而来加大offset的命中率。这个值,可以假设,一般网络故障时间是分钟级别,那可以根据当前的QPS来算一下每分钟可以写入多少字节,再乘以可能发生故障的分钟就可以得到我们这个理想的值。
4、规避复制风暴
什么是复制风暴?举例:master重启,其master下的所有slave检测到RunID发生变化,导致所有从节点向主节点做全量复制。尽管redis对这个问题做了优化,即只生成一份RDB文件,但需要多次传输,仍然开销很大。
1)单主节点复制风暴:主节点重启,多从节点全量复制
**解决办法:**更换复制拓扑,如下图:
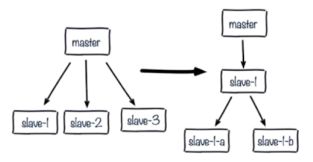
a)将原来master与slave中间加一个或多个slave,再在slave上加若干个slave,这样可以分担所有slave对master复制的压力。(这种架构还是有问题:读写分离的时候,slave1也发生了故障,怎么去处理?)
b)如果只是实现高可用,而不做读写分离,那当master宕机,直接晋升一台slave即可。
简单总结:
- Master最好不要做任何持久化工作,包括内存快照和AOF日志文件,特别是不要启用内存快照做持久化。
- 如果数据比较关键,某个Slave开启AOF备份数据,策略为每秒同步一次。
- 为了主从复制的速度和连接的稳定性,Slave和Master最好在同一个局域网内。
- 尽量避免在压力较大的主库上增加从库
- 为了Master的稳定性,主从复制不要用图状结构,用单向链表结构更稳定,即主从关系 为:Master<–Slave1<–Slave2<–Slave3…….,这样的结构也方便解决单点故障问题,实现Slave对 Master的替换,也即,如果Master挂了,可以立马启用Slave1做Master,其他不变。
6.10.6 RDB和AOF持久化对比
| RDB持久化 | AOF持久化 |
|---|---|
| 全量备份,一次保存整个数据库 | 增量备份,一次保存一个修改数据库的命令 |
| 保存的间隔较长 | 保存的间隔默认为一秒钟 |
| 数据还原速度快 | 数据还原速度一般,冗余命令多,还原速度慢 |
| 执行SAVE命令时会阻塞服务器,但手动或者自动触发的BGSAVE不会阻塞服务器 | 无论是平时还是进行AOF重写时,都不会阻塞服务器 |