决策树与随机森林

01
介绍
决策树和随机森林是两种最流行的监督学习预测模型。这些模型可用于分类和回归问题。
在本文中,我将解释决策树和随机森林之间的区别。到本文结束时,您应该熟悉以下概念:
-
决策树算法如何工作?
-
决策树的组成部分
-
决策树算法的优缺点?
-
装袋是什么意思,随机森林算法是如何工作的?
-
哪种算法在速度和性能方面更好
02
决策树
决策树是高度可解释的机器学习模型,允许我们对数据进行分层或分割。它们允许我们根据特定参数不断拆分数据,直到做出最终决定。
决策树算法如何工作?
看看下表:

该数据集仅包含四个变量?——“Day”、“Temperature”、“Wind”和“Play?”。根据任何一天的温度和风,结果是二元的——要么出去玩,要么呆在家里。
让我们使用这些数据构建一个决策树:
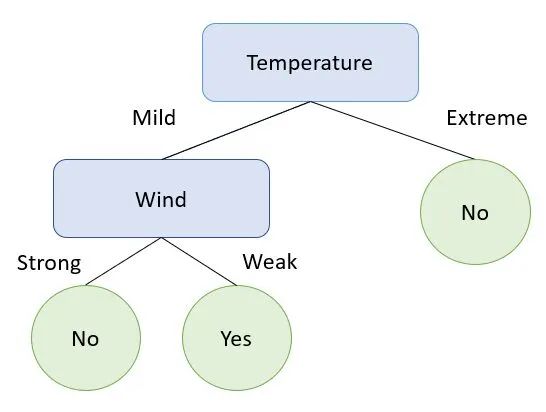
上面的例子很简单,但精确地封装了决策树如何在不同的数据点上分裂直到获得结果。
从上面的可视化中,请注意决策树首先根据变量“温度”进行拆分。它也会在极端温度时停止分裂,并表示我们不要出去玩了。
只有当温度温和时,它才会在第二个变量上开始分裂。
这些观察结果导致以下问题:
-
决策树如何决定要拆分的第一个变量?
-
如何决定何时停止分裂?
-
构建决策树的顺序是什么?
熵
熵是衡量决策树中分裂不纯度的指标。它决定了决策树如何选择对数据进行分区。熵值范围从 0 到 1。值 0 表示纯分裂,值 1 表示不纯分裂。
在上面的决策树中,回想一下树在极端温度时停止分裂:

这是因为当温度极端时,“播放?”的结果。总是“否”。这意味着我们在一个类中有 100% 的数据点的纯分割。本次分裂的熵值为0,决策树将在该节点停止分裂。
决策树将始终选择熵最低的特征作为第一个节点。
在这种情况下,由于变量“温度”的熵值低于“风”,因此这是树的第一次分裂。
观看此YouTube 视频,详细了解熵的计算方式以及它在决策树中的使用方式。
信息增益
信息增益衡量构建决策树时熵的减少。
可以用多种不同的方式构建决策树。这棵树需要找到一个特征来分裂第一、第二、第三等。信息增益是一个指标,它告诉我们可以构建的最好的树来最小化熵。
最好的树是信息增益最高的树。
如果您想详细了解如何计算信息增益并使用它来构建最佳决策树,您可以观看此YouTube 视频。
决策树的组成部分:

-
根节点:根节点位于决策树的顶端,是数据集开始划分的变量。根节点是为我们提供最佳数据拆分的功能。
-
内部节点:这些是在根节点之后拆分数据的节点。
-
叶节点:最后,这些是决策树底部的节点,之后无法进一步拆分。
-
分支:分支将一个节点连接到另一个节点,用于表示测试的结果。
决策树算法的优缺点:
现在您了解了决策树的工作原理,让我们来看看该算法的一些优点和缺点。
优点
-
决策树简单易懂。
-
它们可用于分类和回归问题。
-
他们可以对不可线性分离的数据进行分区。
缺点
-
决策树容易过度拟合。
-
即使训练数据集的微小变化也会对决策树的逻辑产生巨大影响。
03
随机森林
决策树算法的最大缺点之一是它容易过拟合。这意味着模型过于复杂并且具有高方差。像这样的模型将具有很高的训练准确性,但不会很好地泛化到其他数据集。
随机森林算法是如何工作的?
随机森林算法通过组合多个决策树所做的预测并返回单个输出来解决上述挑战。这是使用称为装袋或引导聚合的技术的扩展来完成的。
Bagging 是一种用于减少机器学习模型方差的过程。它通过平均一组观察值来减少方差。
以下是装袋的工作原理:
引导程序
如果我们有多个训练数据集,我们可以在每个数据集上训练多个决策树并对结果进行平均。
然而,由于在大多数真实场景中我们通常只有一个训练数据集,因此使用一种称为bootstrap的统计技术来对数据集进行有放回采样。
然后,创建多个决策树,并在不同的数据样本上训练每棵树:

请注意,已从上面的训练数据集中创建了三个引导样本。随机森林算法比装袋和随机抽取特征更进一步,因此仅使用一部分变量来构建每棵树。
每个决策树将根据训练它们的数据样本呈现不同的预测。
聚合
在此步骤中,将组合每个决策树的预测以得出单个输出。
在分类问题的情况下,进行多数类预测:

在回归问题中,所有决策树的预测将被平均得出一个值。
为什么我们在随机森林算法中随机抽样变量?
在随机森林算法中,随机采样的不仅是行,还有变量。
这是因为如果我们要构建具有相同特征的多棵决策树,每棵树都将相似且彼此高度相关,可能会产生相同的结果。这将再次导致高方差的问题。
04
决策树与随机森林
哪个更好,为什么?
由于以下原因,随机森林通常比决策树表现更好:
-
随机森林解决了过度拟合的问题,因为它们结合了多个决策树的输出来得出最终预测。
-
当您构建决策树时,数据的微小变化会导致模型预测出现巨大差异。对于随机森林,不会出现此问题,因为在生成预测之前对数据进行了多次采样。
然而,就速度而言,随机森林速度较慢,因为构建多个决策树需要更多时间。向随机森林模型中添加更多的树会在一定程度上提高其准确性,但也会增加计算时间。
最后,决策树也比随机森林更容易解释,因为它们很简单。将决策树可视化并理解算法如何得出结果很容易。随机森林更难解构,因为它更复杂并且结合了多个决策树的输出来进行预测。
原文章链接:https://www.kdnuggets.com/2022/08/decision-trees-random-forests-explained.html