决策树(decision tree)
决策树就是像树结构一样的分类下去,最后来预测输入样本的属于那类标签。
本文是本人的学习笔记,所以有些地方也不是很清楚。
大概流程就是
1. 查看子类是否属于同一个类
2. 如果是,返回类标签,如果不是,找到最佳的分类子集的特征
3. 划分数据集
4. 创建分支节点
5. 对每一个节点重复上述步骤
6. 返回树
首先我们要像一个办法,怎么来确定最佳的分类特征就是为什么要这么划分子集。一般有三种方法:
1.Gini不纯度
2.信息熵
3.错误率
参考http://blog.csdn.net/baimafujinji/article/details/51724371
本文采用的是信息熵。
H = -∑p(xi)*log(p(xi))
#计算信息熵
def ShannEnt(dataSet):
m = len(dataSet);
data = {}
shannEnt = 0.0
for i in range(m):
dataKey = dataSet[i][-1]
if dataKey not in data.keys():
data[dataKey] = 0
data[dataKey] += 1
for j in data:
pi = float(data[j])/m
shannEnt -= pi*np.log2(pi)
return shannEnt然后就是选择最佳的划分方式,就是按最佳的方式来分的话,得到的信息增益(就是新的信息熵减去老的信息熵)最多(按加权算法来计算的)。
def chooseDateSplit(dataSet):
numFeature = len(dataSet[0]) - 1
bestFeature = -1
#计算上一个的信息熵
BestEnt = ShannEnt(dataSet)
bestGain = 0
for i in range(numFeature):
featureList = [ex[i] for ex in dataSet]
unquialFeature = set(featureList)
Ent = 0.0
for j in unquialFeature:
returnVect = splitData(dataSet, i, j)
prop = len(returnVect)/float(len(dataSet))
Ent += prop*ShannEnt(returnVect)
#计算信息增益
infoGain = BestEnt - Ent
if infoGain > bestGain:
bestGain = infoGain
bestFeature = i
return bestFeature;然后就是构建树了
def createTree(dataSet,label):
dataList = [ex[-1] for ex in dataSet]
if dataList.count(dataList[0]) == len(dataList):
return dataList[0]
if len(dataList[0]) == 1:
return majorCnt(dataList)
bestFeat = chooseDateSplit(dataSet)
labelFeat = label[bestFeat]
myTree = {labelFeat:{}}
del(label[bestFeat])
feature = [ex[bestFeat] for ex in dataSet]
uniqicalFeat = set(feature)
for value in uniqicalFeat:
subLabel = label[:]
print()
print(myTree[labelFeat])
myTree[labelFeat][value] = createTree(splitData(dataSet, bestFeat, value),subLabel)
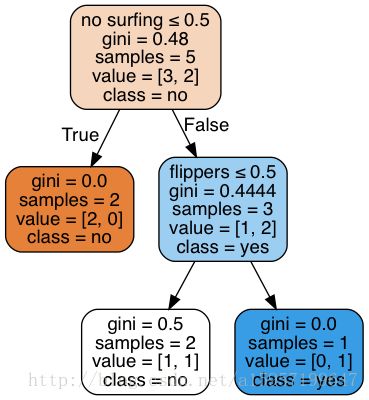
return myTree最后得到的tree为{‘no sufacing’: {0: ‘no’, 1: {‘flippers’: {0: ‘no’, 1: ‘yes’}}}},得到树后,可以用matploytlib模块来可视化。

总结:建立一个决策树的话,最重要还是找到怎么去划分子节点,找到最佳的划分特征。
用sklearn的tree来做(还在学习,有问题请马上指出),
from sklearn.datasets import load_iris
from sklearn.model_selection import cross_val_score
from sklearn import tree
from sklearn.externals.six import StringIO
#默认采用的是gini函数,best分类
clf = tree.DecisionTreeClassifier(random_state=0)
iris = load_iris()
pp = cross_val_score(clf, iris.data, iris.target, cv=5)
x = [[1,1],[1,0],[0,1],[0,1],[1,0]]
y = ['no surfing','flippers','fish']
clf = clf.fit(x,[1,1,0,0,0])
import os
import pydot
dot_data = StringIO()
tree.export_graphviz(clf,out_file=dot_data,feature_names=y,
class_names=['no','yes'],
filled=True, rounded=True,
special_characters=True)
graph = pydot.graph_from_dot_data(dot_data.getvalue())
graph[0].write_pdf('0101.pdf')得到0101.pdf