【365计划-1】pytorch实现mnist手写数字识别
本文为365天深度学习训练营 中的学习记录博客
参考文章地址: 365天深度学习训练营-第P1周:mnist手写数字识别
作者:K同学啊
###本项目来自K同学在线指导###
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
import torch
import numpy as np
from torchsummary import summary
import warnings
import torch.nn.functional as F
device =torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device:",device)
##数据集下载
#torchvision.datasets.MNIST(root,train=True,transform=None,target_transform=None,download=True)
ROOT_FOLDER="data"
MNIST_FOLDER=ROOT_FOLDER+"./mnist"
if not os.path.exists(ROOT_FOLDER) or not os.path.isdir(MNIST_FOLDER):
print("开始下载")
train_ds=torchvision.datasets.MNIST(
ROOT_FOLDER,
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_ds=torchvision.datasets.MNIST(
ROOT_FOLDER,
train=False,
transform=torchvision.transforms.ToTensor(),
download=True,
)
else:
print("数据集已下载")
train_ds=torchvision.datasets.MNIST(
ROOT_FOLDER,
train=True,
transform=torchvision.transforms.ToTensor(),
download=False,
)
test_ds=torchvision.datasets.MNIST(
ROOT_FOLDER,
train=False,
transform=torchvision.transforms.ToTensor(),
download=False,
)
##数据加载
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size=batch_size,
shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size=batch_size)
imgs, labels = next(iter(train_dl))
print(imgs.shape)
plt.figure("数据可视化",figsize=(15,5))
for i,imgs in enumerate(imgs[:20]):
npimg=np.squeeze(imgs.numpy())
plt.subplot(2,10,i+1)
plt.imshow(npimg,cmap=plt.cm.binary)
plt.axis("off")
#plt.show()
num_classes = 10 # 图片的类别数
class Model(nn.Module):
def __init__(self):
super().__init__()
# 特征提取网络
self.conv1 = nn.Conv2d(1, 32, kernel_size=3) # 第一层卷积,卷积核大小为3*3
self.pool1 = nn.MaxPool2d(2) # 设置池化层,池化核大小为2*2
self.drop1 = nn.Dropout(p=0.15)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3) # 第二层卷积,卷积核大小为3*3
self.pool2 = nn.MaxPool2d(2)
self.drop2 = nn.Dropout(p=0.15)
# 分类网络
self.fc1 = nn.Linear(1600, 64)
self.fc2 = nn.Linear(64, num_classes)
# 前向传播
def forward(self, x):
x = self.drop1(self.pool1(F.relu(self.conv1(x))))
x = self.drop2(self.pool2(F.relu(self.conv2(x))))
x = torch.flatten(x, start_dim=1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
##打印模型
model=Model().to(device)
##超参数设置
loss_fn=nn.CrossEntropyLoss()
learn_rate=1e-2
opt=torch.optim.SGD(model.parameters(),lr=learn_rate)
##编写训练函数
def train(dataloader,model,loss_fn,optimizer):
size=len(dataloader.dataset)
num_batches=len(dataloader)
train_loss,train_acc=0,0
for x,y in dataloader:
X,Y=x.to(device),y.to(device)
pred=model(X)
loss=loss_fn(pred,Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == Y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc,train_loss
def test(dataloader,model,loss_fn):
size=len(dataloader.dataset)
num_batches=len(dataloader)
test_loss,test_acc=0,0
with torch.no_grad():
for imgs,target in dataloader:
imgs,target = imgs.to(device),target.to(device)
target_pred=model(imgs)
loss= loss_fn(target_pred,target)
test_loss+=loss.item()
test_acc+=(target_pred.argmax(1)==target).type(torch.float).sum().item()
test_acc /=size
test_loss /=num_batches
return test_acc,test_loss
epochs=10
train_loss=[]
train_acc=[]
test_loss=[]
test_acc=[]
for epoch in range(epochs):
model.train()
epoch_train_acc,epoch_train_loss=train(train_dl,model,loss_fn,opt)
model.eval()
epoch_test_acc,epoch_test_loss=test(test_dl,model,loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template=("Epoch:{:2d},Train_acc:{:.1f}%,Train_loss:{:.3f},Test_acc:{:.1f}%,Test_loss:{:.3f}")
print(template.format(epoch+1,epoch_train_acc*100,epoch_train_loss,epoch_test_acc*100,epoch_test_loss))
print("Done")
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
''' 保存模型参数 '''
saveFile = os.path.join('output', 'epoch'+str(epochs)+'.pkl')
torch.save(model.state_dict(), saveFile)
''' 加载之前保存的模型 '''
if not os.path.exists('output') or not os.path.isdir('output'):
os.makedirs('output')
start_epoch=0
if start_epoch > 0:
resumeFile = os.path.join('output', 'epoch'+str(start_epoch)+'.pkl')
if not os.path.exists(resumeFile) or not os.path.isfile(resumeFile):
start_epoch = 0
else:
model.load_state_dict(torch.load(resumeFile)) # 加载模型参数
打印结果:
Epoch: 1,Train_acc:77.6%,Train_loss:0.749,Test_acc:93.1%,Test_loss:0.227
Epoch: 2,Train_acc:93.5%,Train_loss:0.211,Test_acc:96.5%,Test_loss:0.118
Epoch: 3,Train_acc:95.7%,Train_loss:0.140,Test_acc:96.5%,Test_loss:0.103
Epoch: 4,Train_acc:96.5%,Train_loss:0.114,Test_acc:97.5%,Test_loss:0.076
Epoch: 5,Train_acc:96.9%,Train_loss:0.097,Test_acc:97.9%,Test_loss:0.065
Epoch: 6,Train_acc:97.3%,Train_loss:0.086,Test_acc:98.1%,Test_loss:0.059
Epoch: 7,Train_acc:97.6%,Train_loss:0.077,Test_acc:98.2%,Test_loss:0.054
Epoch: 8,Train_acc:97.8%,Train_loss:0.071,Test_acc:98.4%,Test_loss:0.049
Epoch: 9,Train_acc:97.9%,Train_loss:0.066,Test_acc:98.4%,Test_loss:0.047
Epoch:10,Train_acc:98.1%,Train_loss:0.061,Test_acc:98.8%,Test_loss:0.039
Epoch:11,Train_acc:98.2%,Train_loss:0.058,Test_acc:98.6%,Test_loss:0.041
Epoch:12,Train_acc:98.3%,Train_loss:0.053,Test_acc:98.7%,Test_loss:0.038
Epoch:13,Train_acc:98.4%,Train_loss:0.051,Test_acc:98.9%,Test_loss:0.036
Epoch:14,Train_acc:98.5%,Train_loss:0.048,Test_acc:98.7%,Test_loss:0.038
Epoch:15,Train_acc:98.6%,Train_loss:0.046,Test_acc:98.8%,Test_loss:0.035
Epoch:16,Train_acc:98.5%,Train_loss:0.045,Test_acc:98.9%,Test_loss:0.035
Epoch:17,Train_acc:98.7%,Train_loss:0.041,Test_acc:98.9%,Test_loss:0.032
Epoch:18,Train_acc:98.7%,Train_loss:0.040,Test_acc:98.9%,Test_loss:0.034
Epoch:19,Train_acc:98.8%,Train_loss:0.038,Test_acc:99.1%,Test_loss:0.031
Epoch:20,Train_acc:98.8%,Train_loss:0.037,Test_acc:99.1%,Test_loss:0.030
结果可视化:
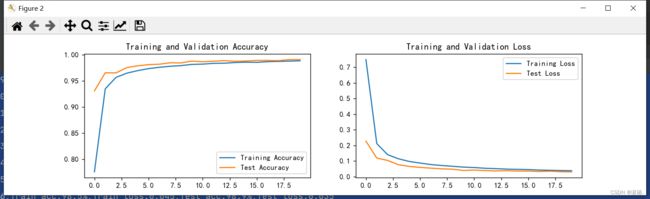
本次分类任务较简单,深度学习具有强大的数据拟合性能,训练至20轮已完全收敛,达到良好效果。
(1):训练数据量小,每张图片尺寸为28*28。
(2):使用droout修正过拟合
(3):学习率为1e-2,故能快速收敛